
 Github
Github Huggingface
Huggingface 论文
论文
ComfyUI-N-Suite
一套定制节点的集合,包括整数字符串和浮点变量节点、GPT节点和视频节点。
[!重要提示]
这些节点主要在Windows中ComfyUI提供的默认环境和在notebook专门创建的环境中进行了测试,使用的是cyberes/gradient-base-py3.10:latest的Docker镜像。 任何其他环境都没有经过测试。
安装步骤
-
克隆该存储库:
git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
到你的ComfyUIcustom_nodes目录 -
重要:如果你想在GPU上运行GPT节点,你需要运行install_dependency批处理文件。 有两个版本:install_dependency_ggml_models.bat用于旧的ggmlv3模型,而install_dependency_gguf_models.bat用于所有新的模型(GGUF)。 你只能同时使用其中一个! 由于_llama-cpp-python_需要从源代码编译以使其使用GPU,你首先需要安装CUDA和Visual Studio 2019或2022(在我的批处理中)来进行编译。详情和完整指南可以点击这里。 -
如果你打算使用Moondream模型的GPTLoaderSimple,你需要执行'install_extra.bat'脚本,这将安装transformers 4.36.2版本。
-
重启ComfyUI
如果由于与其他节点不兼容需要撤销这些更改,可以使用'remove_extra.bat'脚本。
ComfyUI将在启动时自动加载所有自定义脚本和节点。
[!注意]
llama-cpp-python的安装将由脚本自动完成。如果你有一个NVIDIA GPU,不再需要更多的CUDA编译,感谢jllllll库。我也已经放弃了对GGMLv3模型的支持,因为所有重要的模型现在应该都已经切换到最新版本的GGUF了。
[!注意]
自2024年2月14日以来,该节点经历了一次大规模重写,也导致所有节点名称的更改,以避免未来与其他扩展的任何冲突(或者至少我希望如此)。因此,旧的工作流程不再兼容,需要手动替换每个节点。 为了避免这种情况,我创建了一个工具,允许自动替换。 在Windows上,只需将任何*.json工作流程拖动到(custom_nodes/ComfyUI-N-Nodes)中的migrate.bat文件上,将在当前工作流程相同的文件夹中创建一个带有后缀_migrated的新工作流程。 在Linux上,你可以使用以下脚本:python libs/migrate.py 路径/到/原始/工作流程/。 出于安全原因,不会删除原始工作流程。 要安装变更前的这个存储库的最后一个版本,请执行git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083。
- 卸载步骤:
- 删除
custom_nodes中的ComfyUI-N-Nodes文件夹 - 删除
ComfyUI\web\extensions中的comfyui-n-nodes文件夹 - 删除
ComfyUI\styles中的n-styles.csv和n-styles.csv.backup文件 - 删除
ComfyUI\models中的GPTcheckpoints文件夹
- 删除
更新
- 导航到克隆的项目例如
custom_nodes/ComfyUI-N-Nodes git pull
特性
📽️ 视频节点 📽️
LoadVideo
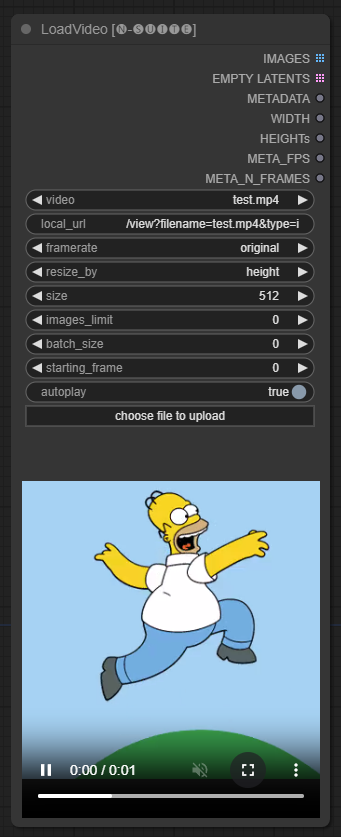
LoadVideoAdvanced节点允许载入视频文件并从中提取帧。
名称已从LoadVideo更改为LoadVideoAdvanced,以避免与LoadVideo animatediff节点的冲突。
输入字段
video: 选择要加载的视频文件。framerate: 选择维持原始帧率或减少到一半或四分之一速度。resize_by: 选择如何调整帧大小 - 'none', 'height'或 'width'。size: 以高度或宽度调整时的目标大小。images_limit: 限制提取的帧数。batch_size: 帧编码的批处理大小。starting_frame: 选择从哪个帧开始。autoplay: 选择是否自动播放视频。use_ram: 选择使用内存而不是磁盘来解压视频帧。
输出
IMAGES: 提取的帧图像作为PyTorch张量。LATENT: 空潜在向量。METADATA: 视频元数据 - FPS和帧数。WIDTH:帧宽。HEIGHT: 帧高。META_FPS: 帧率。META_N_FRAMES: 帧数。
该节点按指定的帧率从输入视频中提取帧。如果选择,可以调整帧的大小,并将它们作为PyTorch图像张量的批处理返回,以及潜在向量、元数据和帧尺寸。
SaveVideo
SaveVideo节点接收提取的帧并将其保存回视频文件。

输入字段
images: 作为张量的帧图像。METADATA: 来自LoadVideo节点的元数据。SaveVideo: 切换保存输出视频文件。SaveFrames: 切换保存帧到文件夹。CompressionLevel: 保存帧时的PNG压缩级别。
输出
保存输出视频文件和/或提取的帧。
该节点接受提取的帧和元数据,可以将它们保存为新的视频文件和/或单独的帧图像。可以配置视频压缩和帧PNG压缩。 注意:如果你使用 LoadVideo 作为帧的来源,原始文件的音频会被保留,但仅在images_limit 和 starting_frame都等于零的情况下。
LoadFramesFromFolder
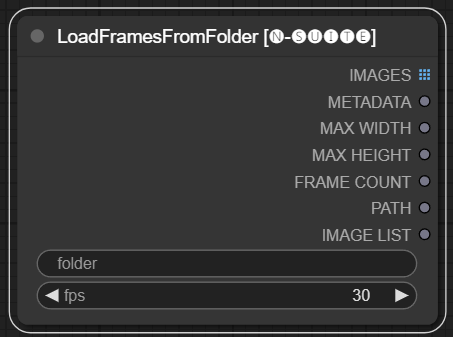
LoadFramesFromFolder节点允许从文件夹加载图像帧并将它们作为一个批返回。
输入字段
folder: 包含帧图像的文件夹路径。必须是png格式,用数字命名(例如1.png或甚至0001.png)。图像将按顺序加载。fps: 为加载的帧分配的每秒帧数。
输出
IMAGES: 作为PyTorch张量加载的帧图像批。METADATA: 包含设置的FPS值的元数据。MAX_WIDTH: 最大帧宽度。MAX_HEIGHT: 最大帧高度。FRAME COUNT: 文件夹中的帧数。PATH: 包含帧图像的文件夹路径。IMAGE LIST: 文件夹中所有帧图像的列表(不是实际列表,只是一个以\n分隔的字符串)。
该节点从指定的文件夹中加载所有图像文件,将它们转换为PyTorch张量,并将它们作为加载的图像张量批返回,同时包含简单的元数据,带有设定的FPS值。
这允许轻松加载先前提取并保存的一组帧,例如,重新加载并再次处理它们。通过设置FPS值,可以正确解释这些帧作为视频序列。
SetMetadataForSaveVideo
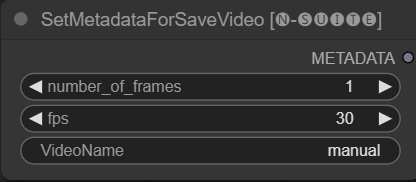
SetMetadataForSaveVideo节点允许设置SaveVideo节点的元数据。
FrameInterpolator
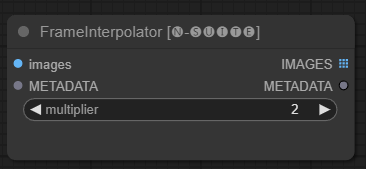
FrameInterpolator节点允许在提取的视频帧之间插值,以增加帧速率并平滑运动。
输入字段
images: 提取的帧图像作为张量。METADATA: 来自视频的元数据 - 帧速率和帧数。multiplier: 帧率增加的倍数。
输出
IMAGES: 插值后的帧作为图像张量。METADATA: 带有新帧速率的更新元数据。
该节点接收提取的帧和元数据作为输入。它使用插值模型(RIFE)生成额外的中间帧,以更高的帧率插值。
元数据中的原始帧速率乘以multiplier值得到新的插值帧速率。
插值后的帧作为图像张量批返回,并带有含有新帧速率的更新元数据。
这允许增加现有视频的帧速率,以实现更平滑的运动和更慢的播放。插值模型创建新的逼真帧以填补空白,而不仅仅是重复现有帧。
原始代码取自这里
变量
由于原始节点在链接方面有局限性(例如在我编写时你不能链接另一个k样本的"start_at_step"和"steps"),我决定创建这些简单的节点变量以绕过此限制 节点变量为:
- Integer(整数)
- Float(浮点数)
- String(字符串)
🤖 GPTLoaderSimple和GPTSampler 🤖
这些自定义节点旨在通过使用GGUF GPT模型启用文本生成来增强ConfyUI框架的功能。此README提供了两个自定义节点及其在ConfyUI中的使用概述。
你可以在_extra_model_paths.yaml_中添加你的GGUF模型路径,格式如下(示例):
other_ui: base_path: I:\\text-generation-webui GPTcheckpoints: models/
否则它将创建一个GPTcheckpoints文件夹在ComfyUI的模型文件夹中,你可以将你的.gguf模型放在那里。
在 'Llava' 目录下的 'GPTcheckpoints' 文件夹中,创建了两个文件夹供LLava模型使用:
clips: 该文件夹用于存储你的LLava模型的剪辑(通常是库中以mm开头的文件)。
models: 该文件夹用于存储LLava模型。
这两个节点实际上支持4种不同的模型:
- 所有由llama.cpp支持的GGUF模型
- Llava
- Moondream
- Joytag
GGUF LLM
GGUF模型可以从Huggingface Hub下载
这个视频解释了如何使用GGUF模型这里,作者是boricuapab
Llava
这里是该节点支持的一些模型的列表:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Vision
Llava模型示例:
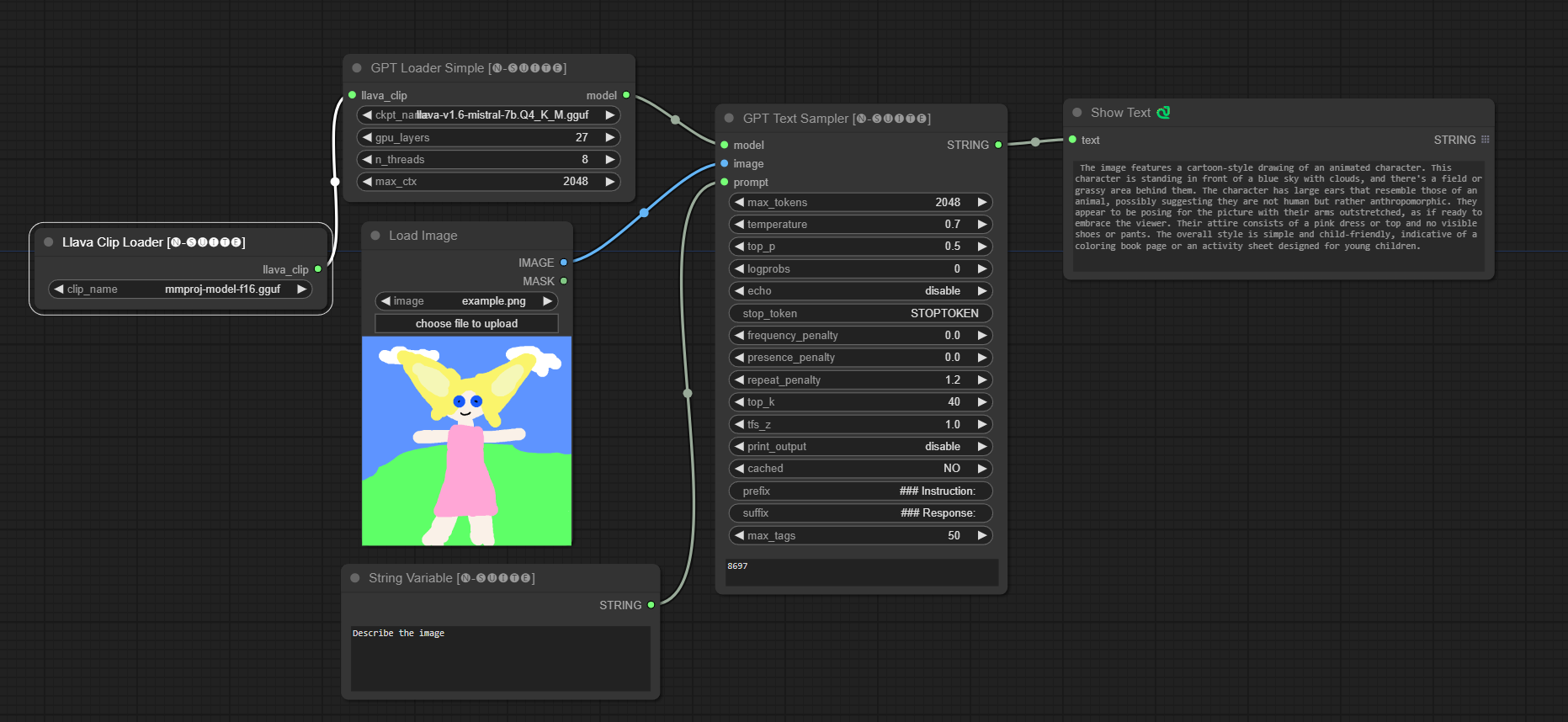
Moondream
首次运行时会自动下载模型。 无论如何,它可以从这里下载 代码取自此库
Moondream模型示例:
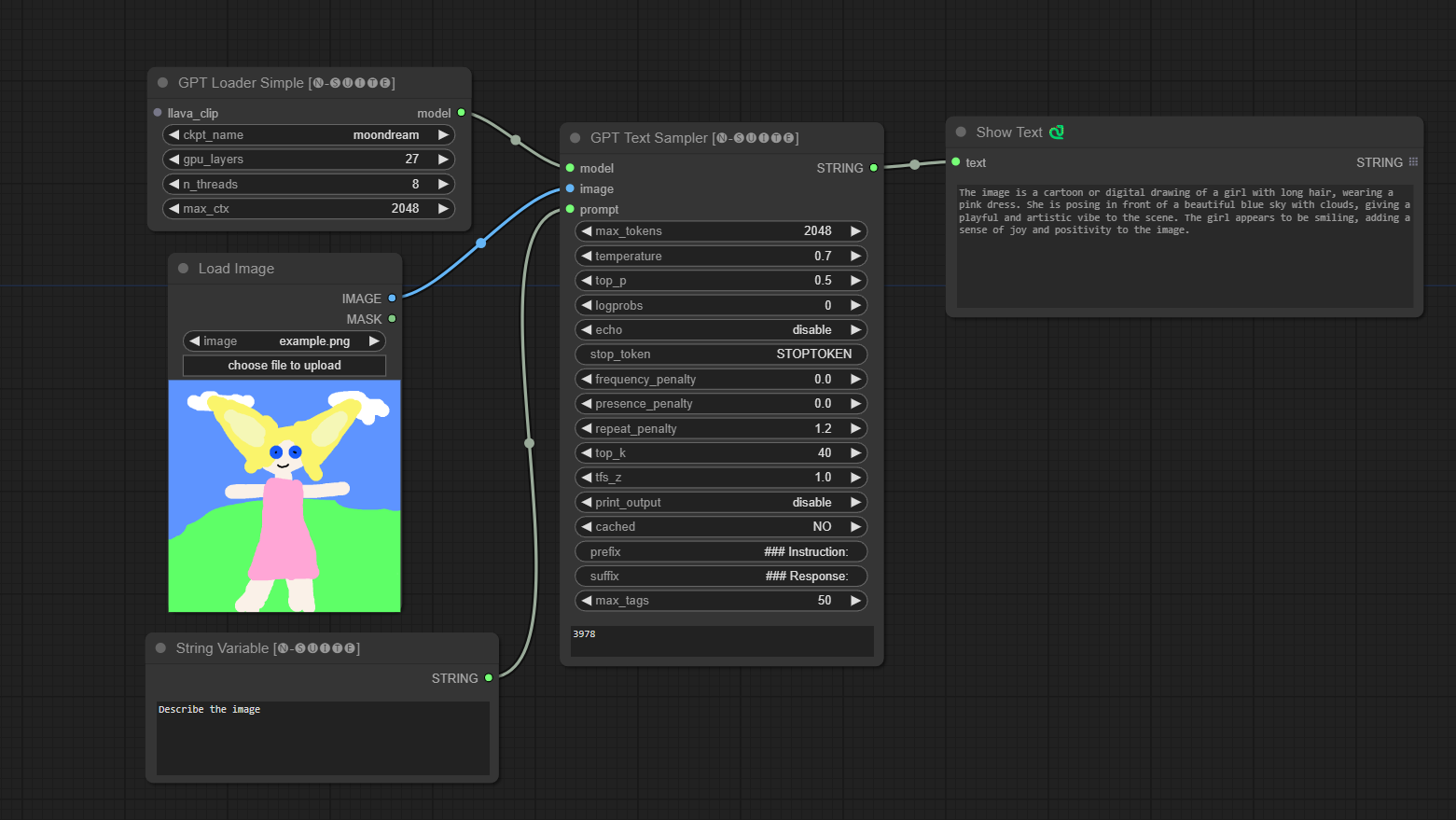
Joytag
首次运行时会自动下载模型。 无论如何,它可以从这里下载 代码取自此库
Joytag模型示例:
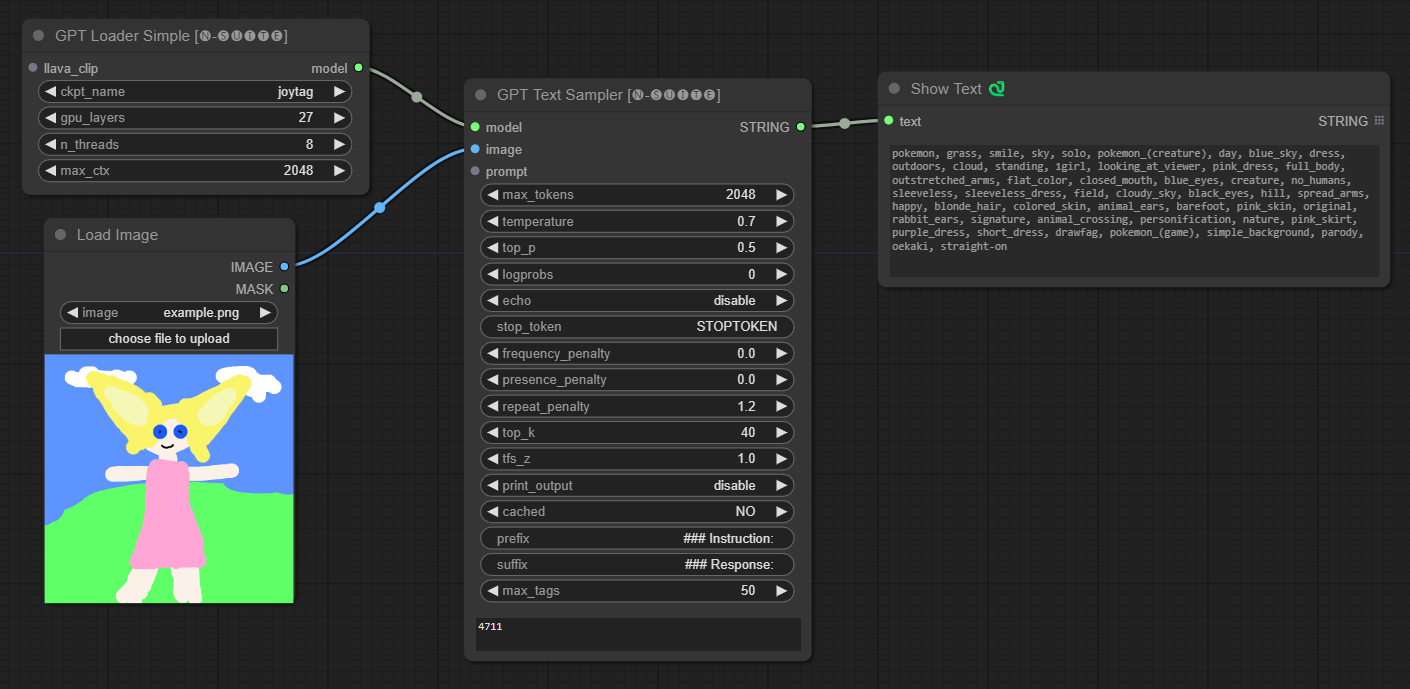
GPTLoaderSimple

GPTLoaderSimple 节点负责加载 GPT 模型检查点并创建用于文本生成的 Llama 库实例。它提供了一个界面来配置 GPU 层数、线程数量和文本生成的最大上下文。
输入字段
ckpt_name:从可用选项中选择 GPT 检查点名称(首次使用时将自动下载 joytag 和 moondream)。gpu_layers:指定要使用的 GPU 层数(默认:27)。n_threads:指定文本生成的线程数量(默认:8)。max_ctx:指定文本生成的最大上下文长度(默认:2048)。
输出
节点返回 Llama 库的实例(MODEL)和加载的检查点路径(STRING)。
GPTSampler
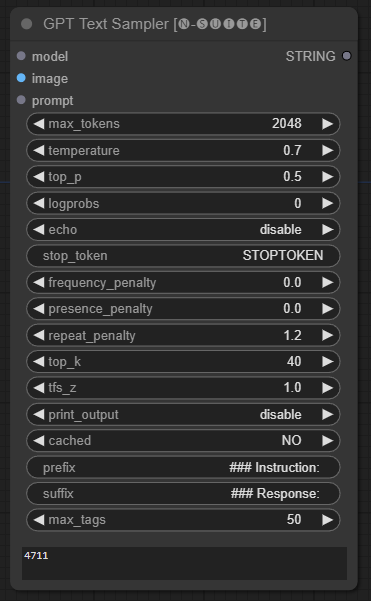
GPTSampler 节点基于输入提示和各种生成参数促进 GPT 模型的文本生成。它允许你控制温度、top-p 采样、惩罚等方面。
输入字段
prompt:输入文本生成的提示。image:Joytag、moondream 和 llava 模型的图像输入。model:选择用于文本生成的 GPT 模型。max_tokens:设置生成文本的最大标记数(默认:128)。temperature:设置随机性的温度参数(默认:0.7)。top_p:设置核采样的 top-p 概率(默认:0.5)。logprobs:指定输出的对数概率数量(默认:0)。echo:启用或禁用同时打印输入提示和生成的文本。stop_token:指定文本生成停止的标记。frequency_penalty、presence_penalty、repeat_penalty:控制词生成的惩罚。top_k:设置生成期间考虑的 top-k 标记(默认:40)。tfs_z:设置高频样本的温度缩放因子(默认:1.0)。print_output:启用或禁用将生成的文本打印到控制台。cached:选择是否使用缓存生成(默认:NO)。prefix、suffix:指定要在提示前后添加的文本。max_tags:仅影响 joydag 生成的最大标签数量。
输出
节点返回生成的文本以及用户界面友好的表示形式。
高级图像填充 (用于外部绘画)
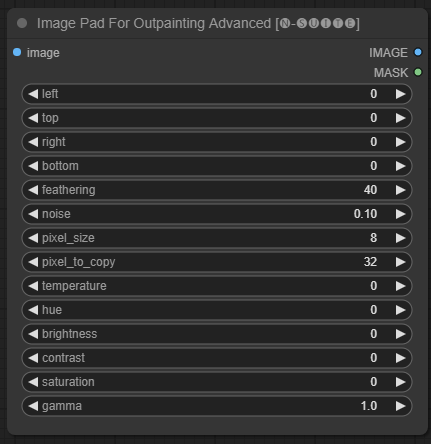
ImagePadForOutpaintingAdvanced 节点是 ImagePadForOutpainting 节点的替代方案,在外部绘画遮罩下应用此视频中所示的技术。颜色校正部分取自 Sipherxyz 的自定义节点。
输入字段
image:图像输入。left:从左侧扩展的像素,top:从顶部扩展的像素,right:从右侧扩展的像素,bottom:从底部扩展的像素。feathering:羽化强度noise:噪声与复制边界的混合强度pixel_size:像素化效果中像素的大小pixel_to_copy:要复制的像素数量(每侧)temperature:仅应用于遮罩部分的颜色校正设置。hue:仅应用于遮罩部分的颜色校正设置。brightness:仅应用于遮罩部分的颜色校正设置。contrast:仅应用于遮罩部分的颜色校正设置。saturation:仅应用于遮罩部分的颜色校正设置。gamma:仅应用于遮罩部分的颜色校正设置。
输出
节点返回处理后的图像和遮罩。
动态提示
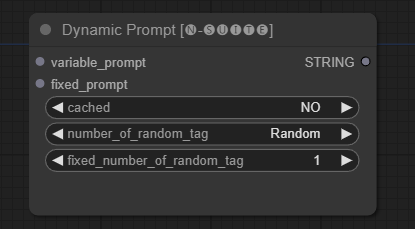
DynamicPrompt 节点通过将固定提示与可变提示中的随机选择标签组合来生成提示。这为各种用例提供了灵活和动态的提示生成。
输入字段
variable_prompt:输入用于标签选择的可变提示。cached:选择是否缓存生成的提示(默认:NO)。number_of_random_tag:选择要包含的随机标签数量为 "固定" 还是 "随机"。fixed_number_of_random_tag:如果number_of_random_tag为 "固定",则指定要包含的随机标签数量(默认:1)。fixed_prompt(可选):输入用于生成最终提示的固定提示。
输出
节点返回生成的提示,即固定提示和选定随机标签的组合。
示例用法
- 只需在
variable_prompt字段中填写用逗号分隔的标签,fixed_prompt为可选。
高级 CLIP 文本编码 (实验性)

CLIP Text Encode Advanced 节点是标准 CLIP Text Encode 节点的替代方案。它支持添加/替换/删除样式,允许在单个节点中包含正面和负面提示。
基本样式文件名为 n-styles.csv,位于 ComfyUI\styles 文件夹中。
样式文件遵循当前在 A1111 中使用的 styles.csv 文件格式(在撰写本文时)。
注意:此节点是实验性的,仍然有很多漏洞
输入字段
clip:clip 输入style:它将根据选择的样式自动填充正面和负面提示
输出
positive:正面条件negative:负面条件
故障排除
SaveVideo - 预览不起作用:这是与 animateDiff 的冲突有关,我已经开了一个 PR 来解决这个问题。同时你可以从这里 下载我修补过的版本拉取请求已被合并,所以这个问题应该已经解决了!
贡献
欢迎通过报告问题或提出改进建议来为这个项目做出贡献。在 GitHub 仓库上打开一个问题或提交拉取请求。
许可证
此项目根据 MIT 许可证授权。详见 许可证 文件。











