
病理语言和图像预训练(PLIP)
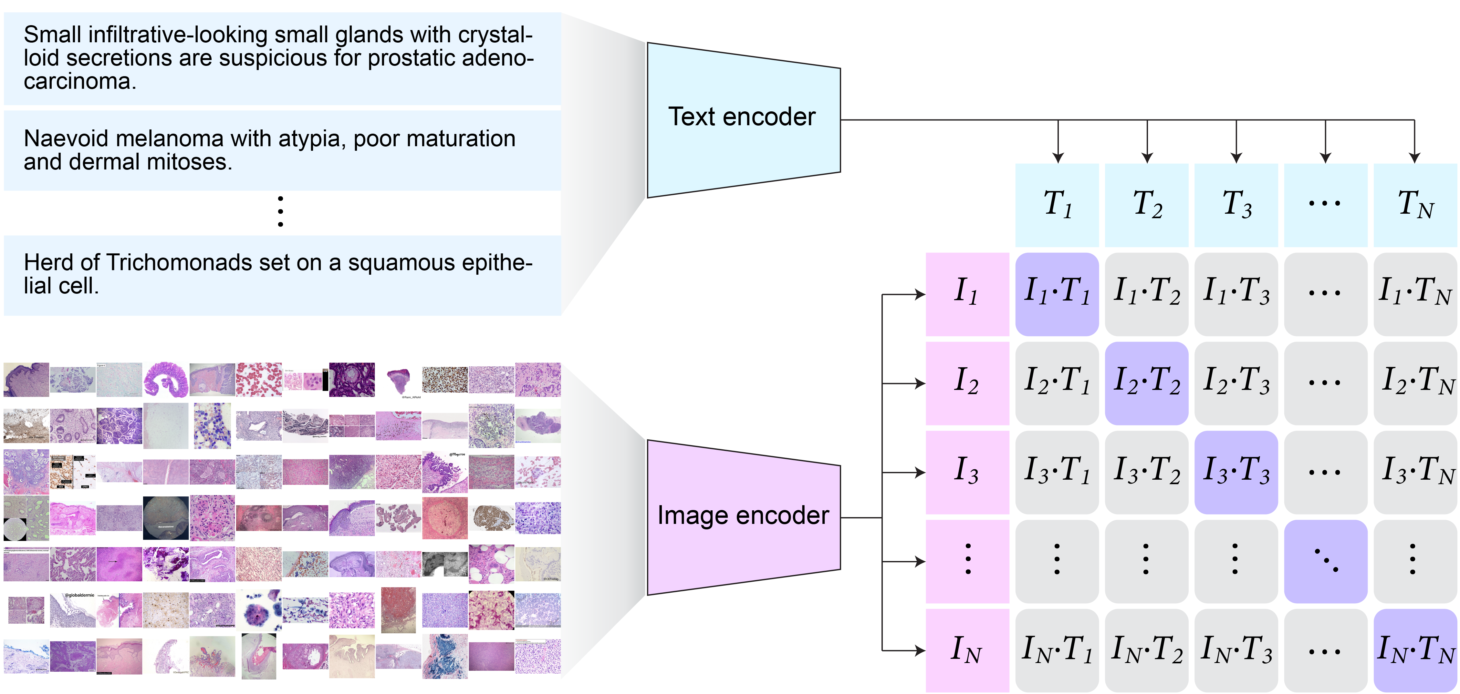
病理语言和图像预训练(PLIP)是第一个用于病理AI的视觉和语言基础模型。PLIP是一个大规模预训练模型,可用于从病理图像和文本描述中提取视觉和语言特征。该模型是原始CLIP模型的微调版本。
资源
- 📚 官方演示
- 📚 PLIP on HuggingFace
- 📚 论文
内部API使用
from plip.plip import PLIP
import numpy as np
plip = PLIP('vinid/plip')
# 创建图像嵌入和文本嵌入
image_embeddings = plip.encode_images(images, batch_size=32)
text_embeddings = plip.encode_text(texts, batch_size=32)
# 将嵌入标准化为单位范数(这样我们可以使用点积而不是余弦相似度进行比较)
image_embeddings = image_embeddings/np.linalg.norm(image_embeddings, ord=2, axis=-1, keepdims=True)
text_embeddings = text_embeddings/np.linalg.norm(text_embeddings, ord=2, axis=-1, keepdims=True)
HuggingFace API使用
from PIL import Image
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("vinid/plip")
processor = CLIPProcessor.from_pretrained("vinid/plip")
image = Image.open("images/image1.jpg")
inputs = processor(text=["标签1的照片", "标签2的照片"],
images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 这是图像-文本相似度得分
probs = logits_per_image.softmax(dim=1)
print(probs)
image.resize((224, 224))
引用
如果您在研究中使用PLIP,请引用以下论文:
@article{huang2023visual,
title={A visual--language foundation model for pathology image analysis using medical Twitter},
author={Huang, Zhi and Bianchi, Federico and Yuksekgonul, Mert and Montine, Thomas J and Zou, James},
journal={Nature Medicine},
pages={1--10},
year={2023},
publisher={Nature Publishing Group US New York}
}
致谢
内部API已从FashionCLIP复制。











