

[CVPR 2024] | LAMP: 学习运动模式的少样本视频生成

本仓库是LAMP的官方实现
LAMP: 学习运动模式的少样本视频生成
吴瑞琦, 陈良宇, 杨桐, 郭春乐, 李崇义, 张祥雨
( * 表示通讯作者)
[Arxiv 论文]
[项目网页]
[Google Drive]
[百度网盘 (密码: ffsp)]
[Colab 笔记本]
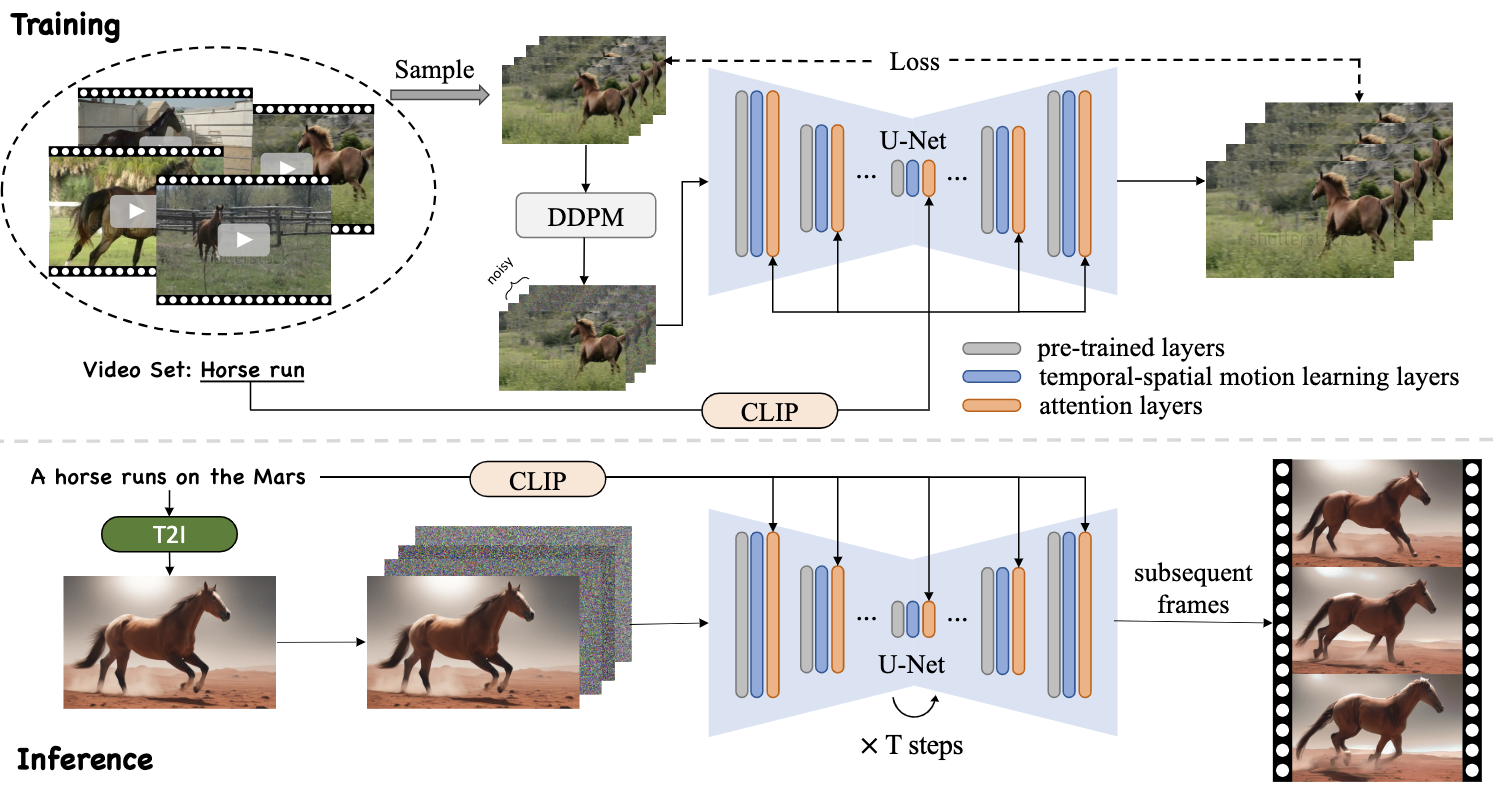
:rocket: LAMP 是一种基于少样本的文本到视频生成方法。您只需要**8~16个视频和1个GPU(显存 > 15 GB)**进行训练!然后您就可以用学习到的运动模式生成视频。
新闻
- [2024/02/27] 我们的论文被CVPR2024接收!
- [2023/11/15] 发布了将LAMP应用于视频编辑的代码!
- [2023/11/02] Colab演示已发布!感谢@ShashwatNigam99的PR。
- [2023/10/21] 我们添加了Google Drive链接,提供我们的检查点和训练数据。
- [2023/10/17] 我们发布了我们的检查点和Arxiv论文。
- [2023/10/16] 我们的代码已公开可用。
准备工作
依赖项和安装
- Ubuntu > 18.04
- CUDA=11.3
- 其他:
# 克隆仓库
git clone https://github.com/RQ-Wu/LAMP.git
cd LAMP
# 创建虚拟环境
conda create -n LAMP python=3.8
conda activate LAMP
# 安装包
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install -r requirements.txt
pip install xformers==0.0.13
权重和数据
-
您可以在Hugging Face上下载预训练的T2I扩散模型。 在我们的工作中,我们使用Stable Diffusion v1.4作为我们的骨干网络。使用
git-lfs克隆预训练权重并将它们放在./checkpoints中 -
我们的检查点和训练数据列表如下。您也可以自行收集视频数据(推荐网站:pexels, frozen-in-time),并将.mp4文件放在
./training_videos/[motion_name]/中 -
[更新] 您可以在
assets/run.mp4中找到视频编辑演示的培训视频
开始使用
1. 训练
# 学习动作模式的训练代码
CUDA_VISIBLE_DEVICES=X accelerate launch train_lamp.py config="configs/horse-run.yaml"
# 视频编辑的训练代码(训练视频可在 assets/run.mp4 中找到)
CUDA_VISIBLE_DEVICES=X accelerate launch train_lamp.py config="configs/run.yaml"
2. 推理
以下是推理的示例命令
# 动作模式
python inference_script.py --weight ./my_weight/turn_to_smile/unet --pretrain_weight ./checkpoints/stable-diffusion-v1-4 --first_frame_path ./benchmark/turn_to_smile/head_photo_of_a_cute_girl,_comic_style.png --prompt "head photo of a cute girl, comic style, turns to smile"
# 视频编辑
python inference_script.py --weight ./outputs/run/unet --pretrain_weight ./checkpoints/stable-diffusion-v1-4 --first_frame_path ./bemchmark/editing/a_girl_runs_beside_a_river,_Van_Gogh_style.png --length 24 --editing
#########################################################################################################
# --weight: 我们模型的路径
# --pretrain_weight: 预训练模型的路径(例如 SDv1.4)
# --first_frame_path: 由 T2I 模型生成的第一帧的路径(例如 SD-XL)
# --prompt: 输入提示,默认值与第一帧的文件名对齐
# --output: 输出路径,默认: ./results
# --height: 视频高度,默认: 320
# --width: 视频宽度,默认: 512
# --length 视频长度,默认: 16
# --cfg: 无分类器引导,默认: 12.5
#########################################################################################################
视觉示例
少样本文本到视频生成
| 马奔跑 |

|

|

|
| 一匹马在宇宙中奔跑。 | 一匹马在火星上奔跑。 | 一匹马在路上奔跑。 | |
| 烟花 |

|

|

|
| 沙漠夜空中的烟花。 | 山峦上空的烟花。 | 夜晚城市中的烟花。 | |
| 弹吉他 |

|

|

|
| GTA5海报,一个男人弹吉他。 | 一个女人弹吉他。 | 一个宇航员弹吉他,逼真风格。 | |
| 鸟飞翔 |

|

|

|
| 鸟儿在粉色天空中飞翔。 | 鸟儿在天空中飞翔,海面上空。 | 许多鸟儿在广场上空飞翔。 |
| 原始视频 | 编辑结果-1 | 编辑结果-2 |

|

|

|
| 一个穿黑衣的女孩在路上跑步。 | 一个男人在路上跑步。 | |

|

|

|
| 一个男人在跳舞。 | 一个穿白衣的女孩在跳舞。 |
引用
如果您发现我们的仓库对您的研究有用,请引用我们:
@inproceedings{wu2024lamp,
title={LAMP: Learn A Motion Pattern for Few-Shot Video Generation},
author={Wu, Ruiqi and Chen, Liangyu and Yang, Tong and Guo, Chunle and Li, Chongyi and Zhang, Xiangyu},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
许可证
根据知识共享署名-非商业性使用 4.0 国际许可协议获得许可,仅供非商业用途使用。 任何商业用途都应首先获得正式许可。
致谢
本仓库由吴瑞琪维护。 代码基于Tune-A-Video构建。感谢这个优秀的开源代码!











