🤖 Renumics RAG:探索和可视化RAG数据
使用LangChain 和Streamlit的检索增强生成助手演示。
🛠️ 安装
在项目目录中设置虚拟环境:
python3.8 -m venv .venv
source .venv/bin/activate # Linux/MacOS
# .\.venv\Scripts\activate.bat # Windows CMD
# .\.venv\Scripts\activate.ps1 # PowerShell
pip install -IU pip setuptools wheel
安装RAG演示包和一些额外的依赖:
# 支持GPU
pip install renumics-rag[all]@git+https://github.com/Renumics/renumics-rag.git torch torchvision sentence-transformers accelerate
# 支持CPU
# pip install renumics-rag[all]@git+https://github.com/Renumics/renumics-rag.git torch torchvision sentence-transformers accelerate --extra-index-url https://download.pytorch.org/whl/cpu
⚒️ 本地设置
如果你打算进行编辑而不仅仅是使用这个项目,克隆整个代码库:
git clone git@github.com:Renumics/renumics-rag.git
然后以可编辑模式安装。
通过pip
在项目文件夹中设置虚拟环境:
python3.8 -m venv .venv
source .venv/bin/activate # Linux/MacOS
# .\.venv\Scripts\activate.bat # Windows CMD
# .\.venv\Scripts\activate.ps1 # PowerShell
pip install -IU pip setuptools wheel
安装RAG演示包和一些额外的依赖:
pip install -e .[all]
# 支持GPU
pip install pandas torch torchvision sentence-transformers accelerate
# 支持CPU
# pip install pandas torch torchvision sentence-transformers accelerate --extra-index-url https://download.pytorch.org/whl/cpu
通过poetry
安装RAG演示包和一些额外的依赖:
poetry install --all-extras
# 支持GPU的Torch
pip install pandas torch torchvision sentence-transformers accelerate
# 支持CPU的Torch
# pip install pandas torch torchvision sentence-transformers accelerate --extra-index-url https://download.pytorch.org/whl/cpu
激活环境(否则,在所有后续命令之前加上poetry run前缀):
poetry shell
注意:如果你安装了Direnv,你可以通过在项目目录中执行
direnv allow来避免python命令前的poetry run前缀。它将在你进入项目目录时激活环境。
⚙️ 配置
如果你打算使用OpenAI模型,创建一个.env文件,并包含以下内容:
OPENAI_API_KEY="Your OpenAI API key"
如果你打算通过Azure使用OpenAI模型,创建.env文件并包含以下内容:
OPENAI_API_TYPE="azure"
OPENAI_API_VERSION="2023-08-01-preview"
AZURE_OPENAI_API_KEY="Your Azure OpenAI API key"
AZURE_OPENAI_ENDPOINT="Your Azure OpenAI endpoint"
如果你使用Hugging Face模型,不需要.env文件。你可以在配置文件(settings.yaml)中配置嵌入模型、检索器和LLM。默认设置(取自settings file)如下:
llm_type: 'openai' # 'openai', 'hf' or 'azure'
llm_name: 'gpt-3.5-turbo'
relevance_score_fn: 'l2'
k: 20
search_type: 'similarity'
score_threshold: 0.5
fetch_k: 20
lambda_mult: 0.5
embeddings_model_type: 'openai' # 'openai', 'hf' or 'azure'
embeddings_model_name: 'text-embedding-ada-002'
你可以通过设置一个指向本地配置文件的环境变量RAG_SETTINGS进行修改而无需克隆代码库。你也可以在问答环节通过GUI进行配置。但选择所需的嵌入模型很重要,因为索引是在预处理阶段完成的。
🚀 用法:索引
你可以跳过此部分,下载包含F1数据集嵌入的演示数据库。该数据集基于维基百科文章并遵循知识共享署名-相同方式共享许可协议。原始文章和作者名单可在相应的维基百科页面上找到。 要使用自己的数据,请在项目中创建一个新的data/docs目录并将文档放置在其中(支持递归目录)。
通过索引文档开始流程。执行以下命令:
create-db
这将在项目中创建一个包含索引文档的db-docs目录。要索引其他文档,使用--exist-ok和--on-match标志(有关更多信息,请参见 create-db --help)。
🚀 用法:提问
现在,你可以利用索引的文档来回答问题。
通过命令行接口仅检索相关文档:
retrieve "Your question here"
# QUESTION: ...
# SOURCES: ...
根据索引的文档回答问题:
answer "Your question here"
# QUESTION: ...
# ANSWER: ...
# SOURCES: ...
启动一个Web应用程序(查看app --help了解可用的应用选项):
app
这将打开一个新的浏览器窗口:
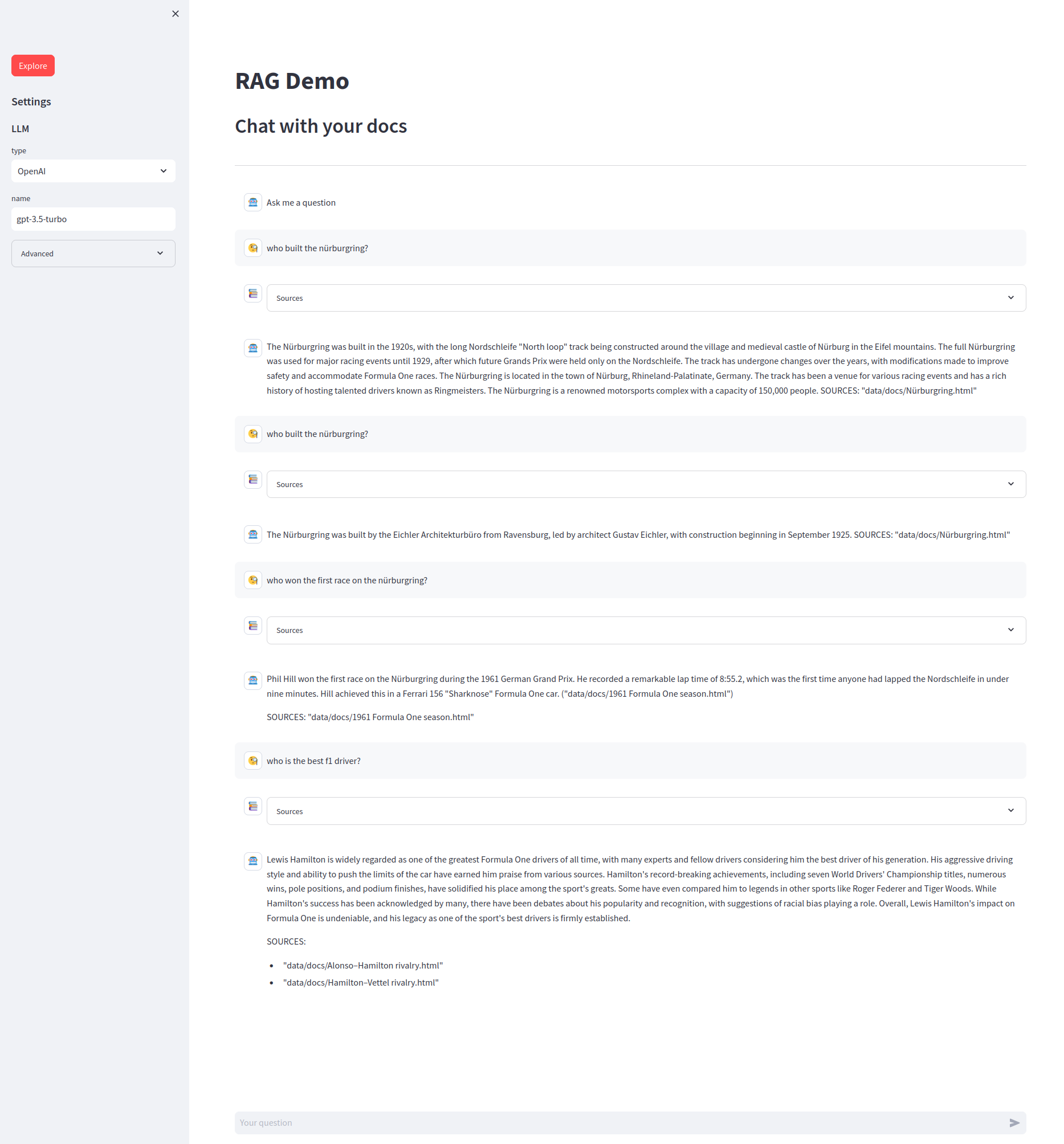
你可以输入问题来获得RAG系统的回答。每个答案都包含一个可展开的"来源"部分,其中包括用于生成答案的每个片段的文本和文件名。 左侧的设置部分允许你从OpenAI或Hugging Face中选择不同的LLMs。在高级设置中,你可以调整检索设置,如关联评分函数的选择、检索片段的数量和搜索类型。你也可以更改嵌入模型。 注意:更改嵌入模型需要使用新嵌入创建新的数据库。
🔎 交互式探索
提交一些问题后,你可以通过点击左侧的红色探索按钮使用Renumics Spotlight进行探索:
这将打开一个新的浏览器标签页:
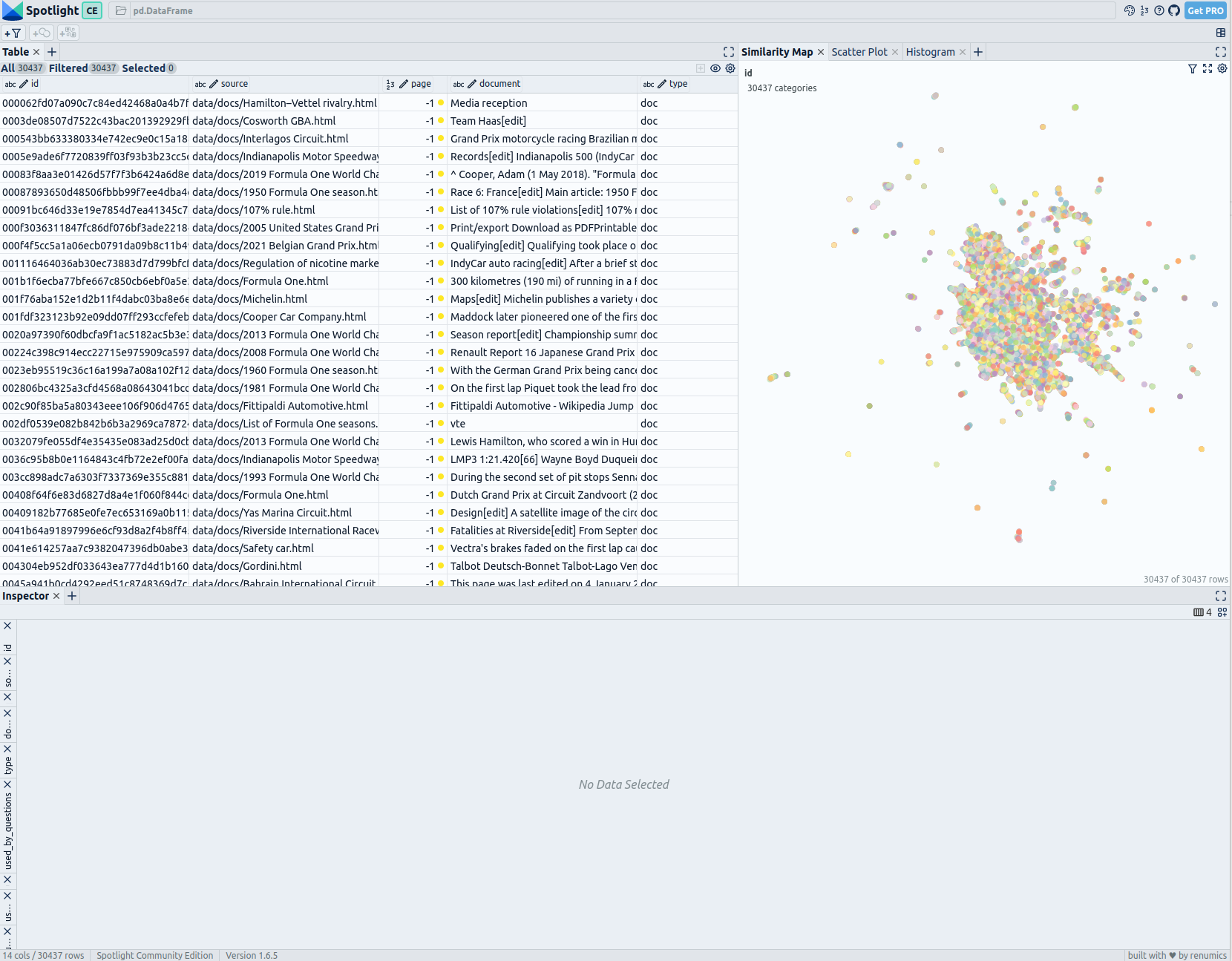
你可以在左上角看到所有问题和所有文档片段的表格。使用“可见列”按钮,你可以控制表中显示哪些列。
右侧是相似度图;它基于嵌入显示问题和文件。你可以点击设置按钮进行自定义,并通过"used_by_num_question"进行着色,以根据检索器加载片段的问题数量来着色片段。
你可以在相似度图或表格中选择片段,在底部的详细视图中显示它们。要自定义详细视图,你可以点击"x"移除行,并使用“添加视图”按钮添加视图。一个好的设置是显示文档、used_by_num_question和类型。
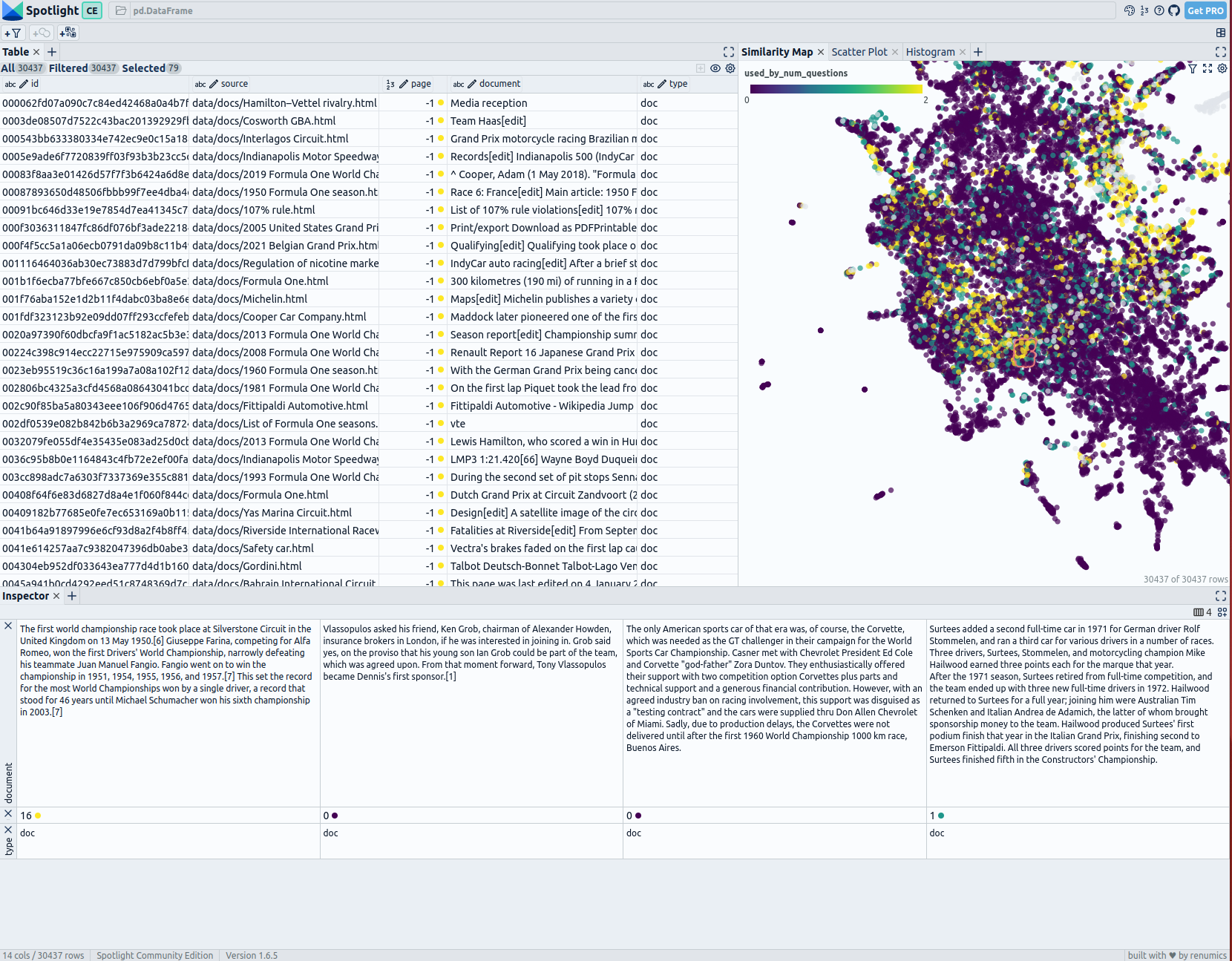
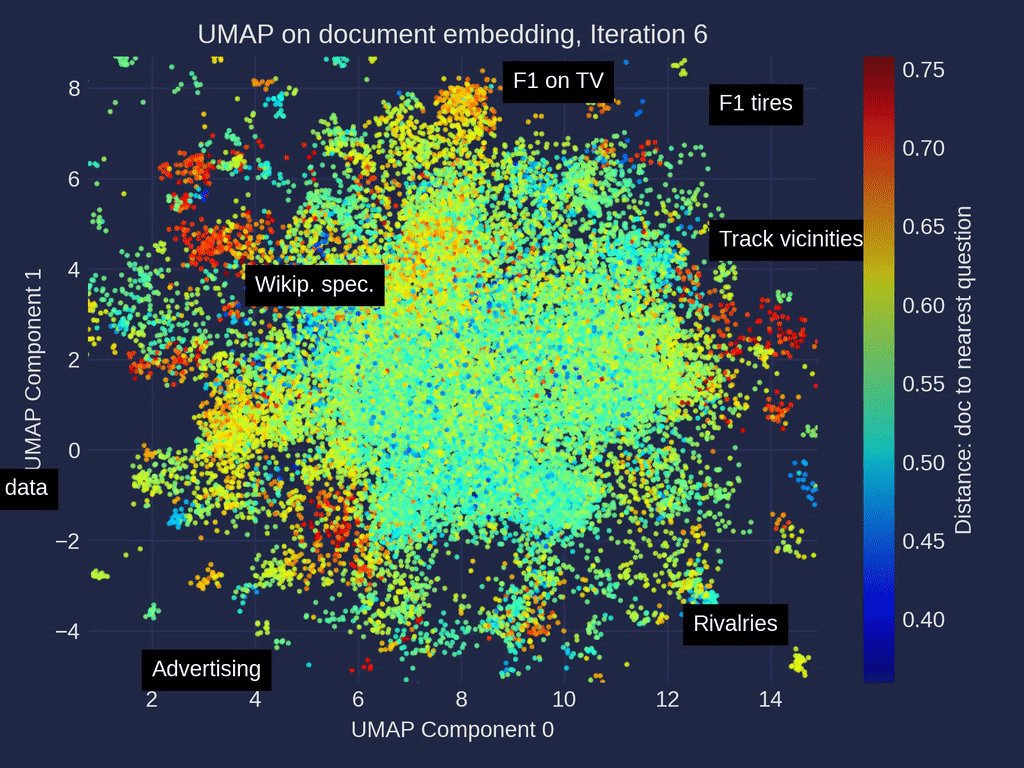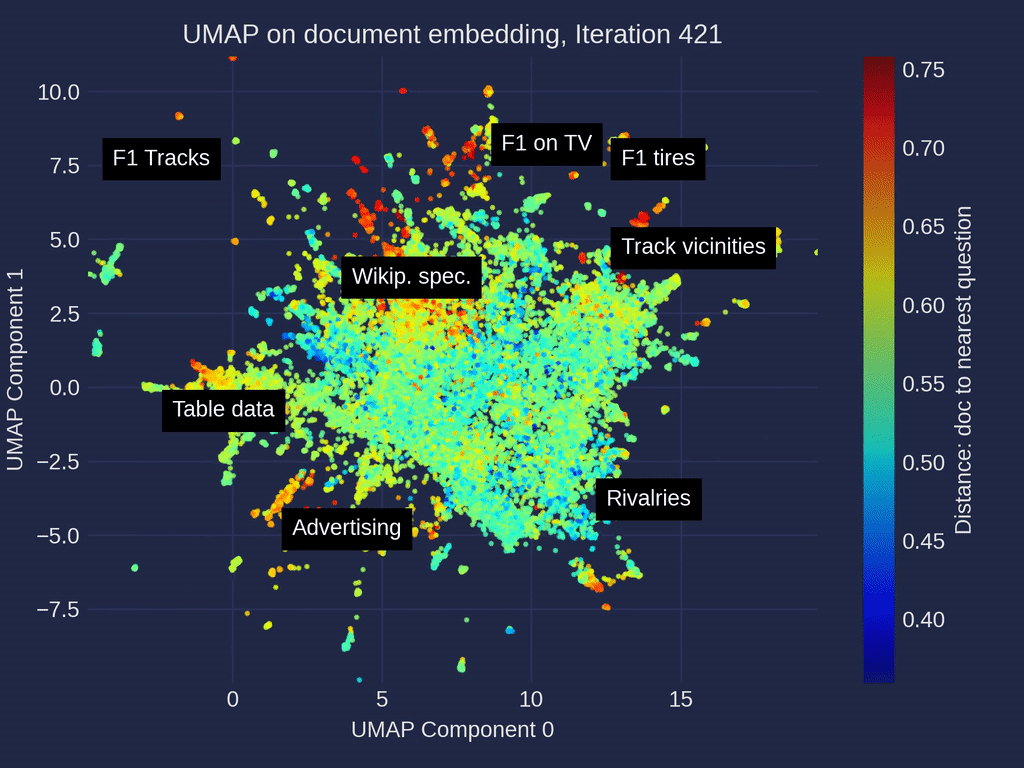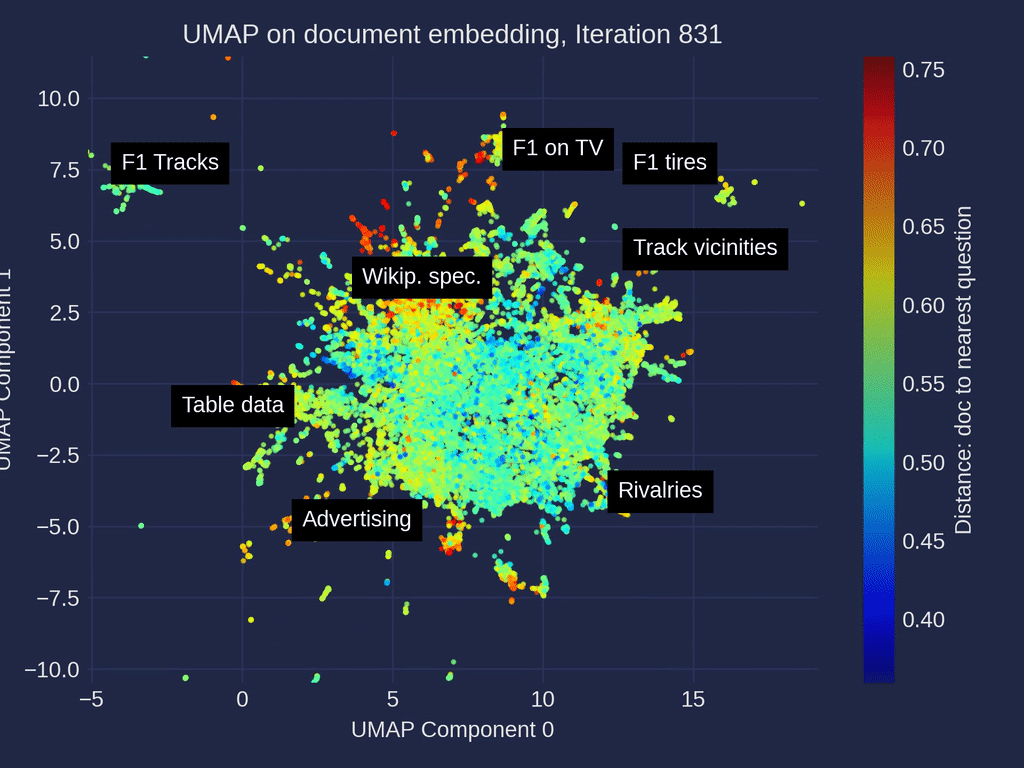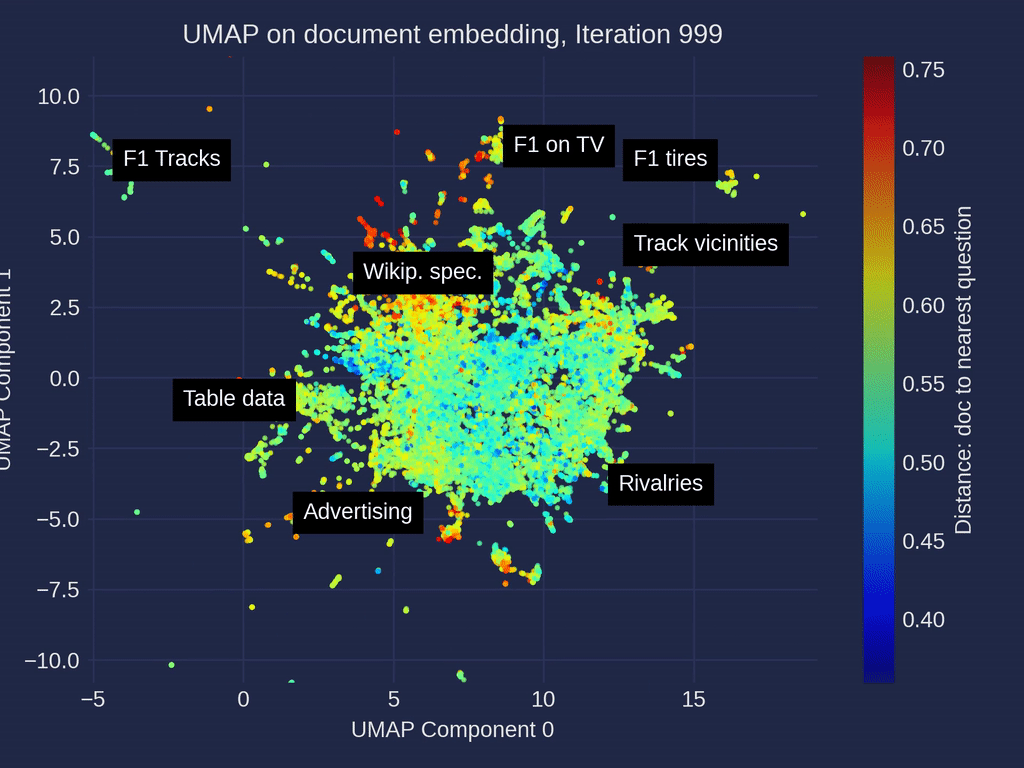
探索我们RAG评估文章中的示例性F1数据集和超过500个问题可以揭示有趣的集群。比赛统计、赛车技术和策略以及团队详细信息的文件集群经常被至少一个问题引用。其他的,如电视转播权或特定赛道详细信息,检索次数较少。
🔎 教程和参考资料
要了解更多关于可视化RAG的信息,请查看我们的文章:
-
ITNext: 可视化你的RAG数据——检索增强生成的EDA:单个问题、答案和相关文件的可视化展示了RAG的巨大潜力。降维技术可以使嵌入空间对用户和开发者来说更加可访问

-
Towards Data Science: 可视化你的RAG数据——使用Ragas评估你的检索增强生成系统:利用基于UMAP的可视化方法提供了一种有趣的方式,可以深入到RAG评估中的全局指标分析。