
 Github
Github Huggingface
Huggingface 文档
文档 论文
论文LiLT-RoBERTa 项目介绍
LiLT-RoBERTa 是一个结合了预训练的 RoBERTa 模型(英语)和预训练的语言无关布局变换器(LiLT)的基础模型。它是由 Wang 等人提出的,并详细介绍于论文 LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding。这个模型最初发布在 GitHub 仓库 中。
模型描述
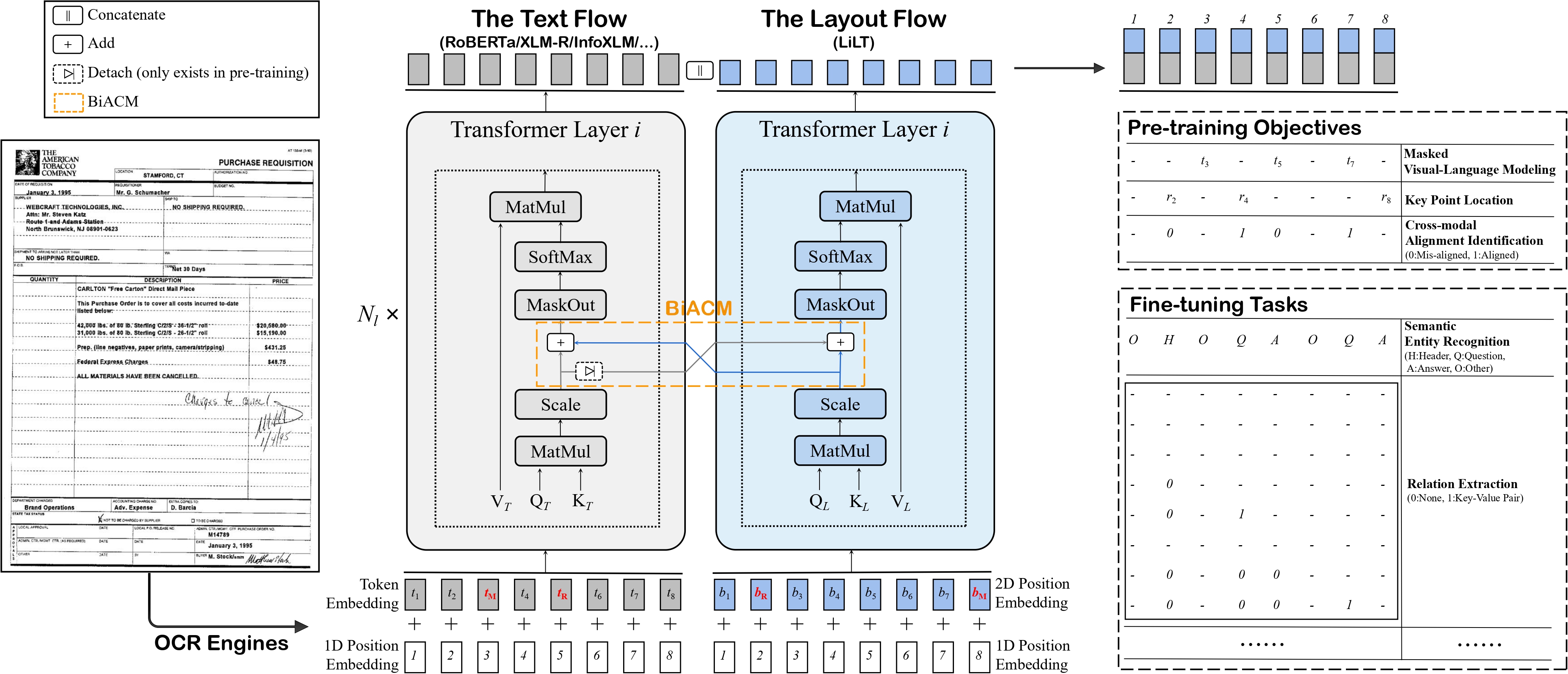
语言无关布局变换器(LiLT)允许将来自模型库的任何预训练 RoBERTa 编码器(因此可以是任何语言)与一个轻量级布局变换器结合,用以创建一个类似 LayoutLM 的跨语言模型。这种组合使得语言无关的文档结构理解变得简单而有效。
该模型的结构如下图所示:
使用意图与限制
LiLT-RoBERTa 主要用于在文档图像分类、文档解析和文档问答等任务上进行微调。用户可以通过访问 模型库 寻找适合他们任务的微调版本。
如何使用
对于如何使用该模型的代码示例,可以参考 Hugging Face 文档。
引用文献
如果需要在学术作品中引用 LiLT-RoBERTa 模型,可以参考以下 BibTeX 条目:
@misc{https://doi.org/10.48550/arxiv.2202.13669,
doi = {10.48550/ARXIV.2202.13669},
url = {https://arxiv.org/abs/2202.13669},
author = {Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
总之,LiLT-RoBERTa 是一个强大的模型,将语言无关的文档布局理解推进到一个新的高度,为多语言环境中的文档处理提供了灵活的解决方案。










