
 访问官网
访问官网 Github
Github Huggingface
HuggingfaceMuseTalk
MuseTalk:使用潜在空间修复实现实时高质量唇形同步
Yue Zhang *、 Minhao Liu*、 Zhaokang Chen、 Bin Wu†、 Yingjie He、 Chao Zhan、 Wenjiang Zhou (*贡献相同,†通讯作者,benbinwu@tencent.com)
腾讯音乐娱乐集团 Lyra 实验室
github huggingface space 项目(即将推出) 技术报告(即将推出)
我们推出了 MuseTalk,这是一个实时高质量的唇形同步模型(在 NVIDIA Tesla V100 上可达 30fps+)。MuseTalk 可以应用于输入视频,例如由 MuseV 生成的视频,作为一个完整的虚拟人解决方案。
:new: 更新:我们很高兴地宣布 MusePose 已经发布。MusePose 是一个图像到视频生成框架,可以根据姿势等控制信号生成虚拟人。结合 MuseV 和 MuseTalk,我们希望社区能够加入我们,朝着能够端到端生成具有全身运动和交互能力的虚拟人的愿景迈进。
招聘
加入腾讯音乐娱乐集团 Lyra 实验室!
我们目前正在招聘 AIGC 研究人员,包括实习生、应届毕业生和资深人才(实习、校招、社招)。
详情请查看以下两个链接或联系 zkangchen@tencent.com
- AI 研究员(https://join.tencentmusic.com/social/post-details/?id=13488, https://join.tencentmusic.com/social/post-details/?id=13502)
概述
MuseTalk 是一个实时高质量的音频驱动唇形同步模型,在 ft-mse-vae 的潜在空间中训练,它具有以下特点:
- 根据输入音频修改未见过的人脸,人脸区域大小为
256 x 256。 - 支持多种语言的音频,如中文、英文和日语。
- 在 NVIDIA Tesla V100 上支持实时推理,可达 30fps+。
- 支持修改人脸区域的中心点,这显著影响生成结果。
- 提供在 HDTF 数据集上训练的检查点。
- 训练代码(即将推出)。
新闻
- [2024/04/02] 发布 MuseTalk 项目和预训练模型。
- [2024/04/16] 在 HuggingFace Spaces 上发布 Gradio 演示(感谢 HF 团队的社区资助)
- [2024/04/17] :mega: 我们发布了一个使用 MuseTalk 进行实时推理的流程。
模型
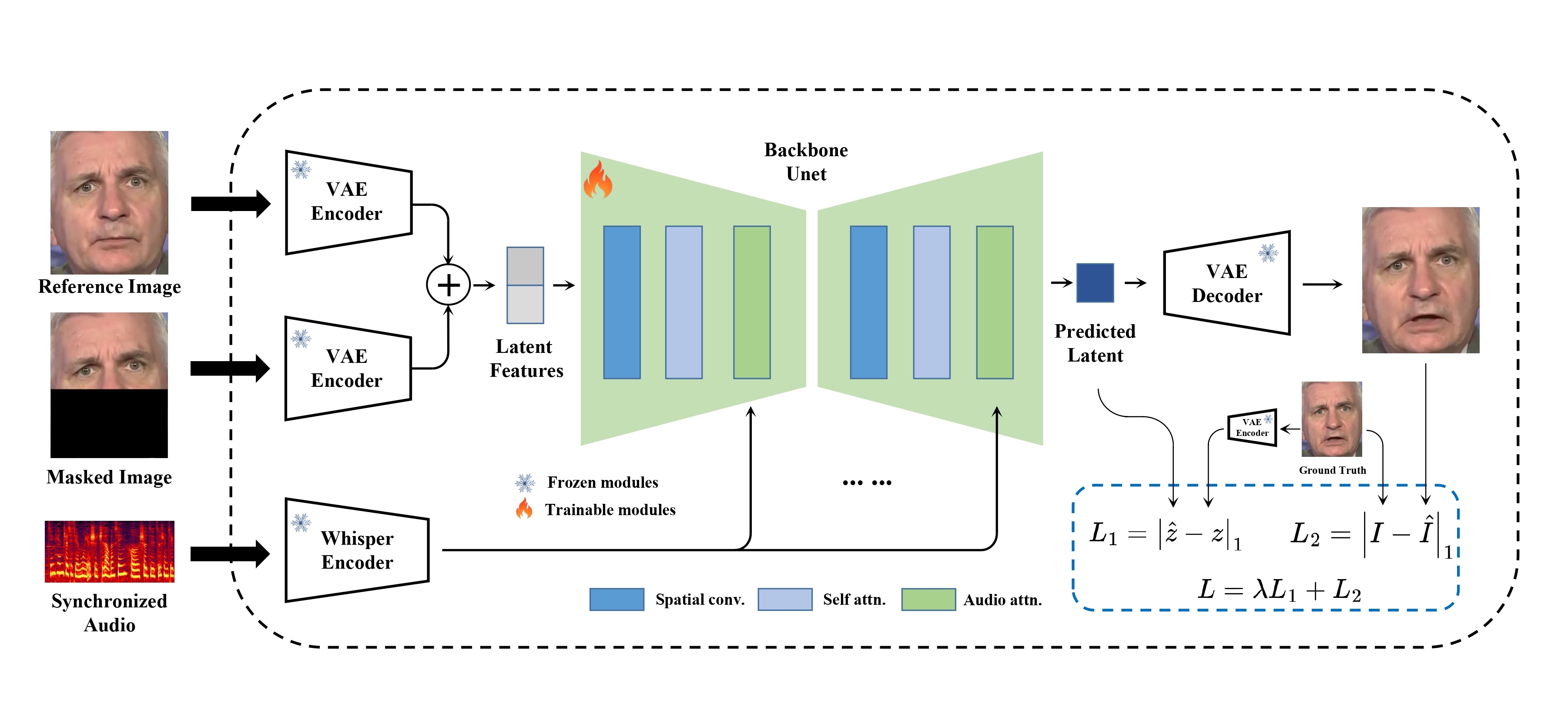 MuseTalk 在潜在空间中训练,其中图像由冻结的 VAE 编码。音频由冻结的
MuseTalk 在潜在空间中训练,其中图像由冻结的 VAE 编码。音频由冻结的 whisper-tiny 模型编码。生成网络的架构借鉴了 stable-diffusion-v1-4 的 UNet,其中音频嵌入通过交叉注意力与图像嵌入融合。
请注意,尽管我们使用了与 Stable Diffusion 非常相似的架构,但 MuseTalk 与之不同,它不是扩散模型。相反,MuseTalk 通过单步在潜在空间进行修复操作。
案例展示
MuseV + MuseTalk 让人物照片栩栩如生!
| 图片 | MuseV | +MuseTalk |

| ||

| ||

| ||

| ||

| ||

| ||

|
- 最后两行的人物"孙新颖"是一位超模网红。您可以在抖音上关注她。
视频配音
| MuseTalk | 原始视频 |
|
链接
|
- 对于视频配音,我们应用了一个自主开发的工具,可以识别说话的人。
一些有趣的视频!
| 图片 | MuseV + MuseTalk |

|
待办事项:
- 训练好的模型和推理代码。
- Huggingface Gradio 演示。
- 实时推理的代码。
- 技术报告。
- 训练代码。
- 更好的模型(可能需要更长时间)。
入门指南
我们为新用户提供了一个详细的教程,介绍MuseTalk的安装和基本使用方法:
第三方集成
感谢第三方集成,这使得安装和使用对每个人来说都更加方便。 我们也希望您注意,我们没有验证、维护或更新第三方集成。具体结果请参考本项目。
ComfyUI
安装
要准备Python环境并安装额外的包,如opencv、diffusers、mmcv等,请按以下步骤操作:
构建环境
我们建议Python版本>=3.10,CUDA版本=11.7。然后按如下方式构建环境:
pip install -r requirements.txt
mmlab包
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"
下载ffmpeg-static
下载ffmpeg-static并
export FFMPEG_PATH=/path/to/ffmpeg
例如:
export FFMPEG_PATH=/musetalk/ffmpeg-4.4-amd64-static
下载权重
您可以按以下方式手动下载权重:
-
下载我们训练的权重。
-
下载其他组件的权重:
最后,这些权重应该在models中按以下方式组织:
./models/
├── musetalk
│ └── musetalk.json
│ └── pytorch_model.bin
├── dwpose
│ └── dw-ll_ucoco_384.pth
├── face-parse-bisent
│ ├── 79999_iter.pth
│ └── resnet18-5c106cde.pth
├── sd-vae-ft-mse
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── whisper
└── tiny.pt
快速开始
推理
这里,我们提供了推理脚本。
python -m scripts.inference --inference_config configs/inference/test.yaml
configs/inference/test.yaml是推理配置文件的路径,包括video_path和audio_path。 video_path应该是视频文件、图像文件或图像目录。
建议输入25fps的视频,这与训练模型时使用的fps相同。如果您的视频帧率远低于25fps,建议应用帧插值或直接使用ffmpeg将视频转换为25fps。
使用bbox_shift获得可调整的结果
:mag_right: 我们发现蒙版上界对嘴部开合度有重要影响。因此,为了控制蒙版区域,我们建议使用bbox_shift参数。正值(向下半部移动)会增加嘴部开合度,而负值(向上半部移动)会减少嘴部开合度。
您可以先用默认配置运行以获取可调整的值范围,然后在此范围内重新运行脚本。
例如,对于Xinying Sun,运行默认配置后,显示可调整的值范围是[-9, 9]。然后,为了减少嘴部开合度,我们将值设为-7。
python -m scripts.inference --inference_config configs/inference/test.yaml --bbox_shift -7
:pushpin: 更多技术细节可以在bbox_shift中找到。
结合MuseV和MuseTalk
作为虚拟人生成的完整解决方案,建议您首先参考这里应用MuseV生成视频(文本到视频、图像到视频或姿势到视频)。建议进行帧插值以提高帧率。然后,您可以参考这里使用MuseTalk生成唇形同步视频。
:new: 实时推理
这里,我们提供了推理脚本。该脚本首先预先应用必要的预处理,如人脸检测、人脸解析和VAE编码。在推理过程中,只涉及UNet和VAE解码器,这使得MuseTalk可以实时运行。
python -m scripts.realtime_inference --inference_config configs/inference/realtime.yaml --batch_size 4
configs/inference/realtime.yaml是实时推理配置文件的路径,包括preparation、video_path、bbox_shift和audio_clips。
- 在
realtime.yaml中将preparation设置为True,为新的avatar准备材料。(如果bbox_shift发生变化,您也需要重新准备材料。) - 之后,
avatar将使用从audio_clips中选择的音频片段生成视频。Inferring using: data/audio/yongen.wav - 当MuseTalk正在推理时,子线程可以同时将结果流式传输给用户。在NVIDIA Tesla V100上,生成过程可以达到30fps以上。
- 如果您想使用相同的avatar生成更多视频,请将
preparation设置为False并运行此脚本。
实时推理注意事项
- 如果您想使用相同的avatar/视频生成多个视频,您也可以使用此脚本来显著加快生成过程。
- 在先前的脚本中,生成时间也受到I/O(如保存图像)的限制。如果您只想测试生成速度而不保存图像,可以运行
python -m scripts.realtime_inference --inference_config configs/inference/realtime.yaml --skip_save_images
致谢
- 我们感谢开源组件如whisper、dwpose、face-alignment、face-parsing、S3FD。
- MuseTalk参考了diffusers和isaacOnline/whisper的许多内容。
- MuseTalk基于HDTF数据集构建。
感谢开源!
局限性
-
分辨率:尽管MuseTalk使用256 x 256的面部区域大小,比其他开源方法更好,但尚未达到理论分辨率上限。我们将继续解决这个问题。 如果您需要更高的分辨率,可以结合使用超分辨率模型,如GFPGAN。
-
身份保持:原始面部的一些细节未能很好地保留,如胡须、嘴唇形状和颜色。
-
抖动:由于当前管道采用单帧生成,存在一些抖动。
引用
@article{musetalk,
title={MuseTalk: Real-Time High Quality Lip Synchorization with Latent Space Inpainting},
author={Zhang, Yue and Liu, Minhao and Chen, Zhaokang and Wu, Bin and He, Yingjie and Zhan, Chao and Zhou, Wenjiang},
journal={arxiv},
year={2024}
}
免责声明/许可
代码:MuseTalk的代码根据MIT许可发布。对学术和商业用途均无限制。模型:训练好的模型可用于任何目的,包括商业用途。其他开源模型:使用的其他开源模型必须遵守其许可,如whisper、ft-mse-vae、dwpose、S3FD等。- 测试数据从互联网收集,仅供非商业研究目的使用。
AIGC:本项目致力于积极影响AI驱动的视频生成领域。用户可以自由使用此工具创建视频,但应遵守当地法律并负责任地使用。开发者不对用户可能的滥用承担任何责任。











