
 访问官网
访问官网 Github
Github Huggingface
Huggingfacetitle: Stable Diffusion XL 1.0 emoji: 🔥 colorFrom: yellow colorTo: gray sdk: gradio sdk_version: 3.11.0 app_file: app.py pinned: true license: mit
StableDiffusion XL Gradio演示Web界面
这是一个支持Stable Diffusion XL 1.0的Gradio演示Web界面。该演示加载了基础模型和精炼模型。
本项目源自StableDiffusion v2.1演示Web界面。请参阅git提交记录以查看具体更改。
更新 🔥🔥🔥:现已支持并默认启用潜在一致性模型(LCM) LoRA(通过ENABLE_LCM控制)!开启USE_SSD以使用SSD-1B实现更快的生成速度(在免费Colab T4上无需额外优化即可达到4.9秒/图像)! Colab已更新为默认使用此设置。

更新 🔥🔥🔥: 查看我们的最新工作LLM-grounded Diffusion (LMD),它将大语言模型引入扩散模型领域,无需任何微调即可实现比标准Stable Diffusion更好的提示理解能力!支持SDXL的LMD可在我们的GitHub仓库中找到,这里提供了一个使用SD的演示。
更新: SDXL 1.0已发布,我们的Web界面演示现已支持!无需申请即可获取权重!启动Colab即可开始使用。您可以在免费的Colab T4上运行此演示。
更新: 现已支持多GPU。通过设置MULTI_GPU=True,您可以轻松地将工作负载分配到不同的GPU上。这使用数据并行来将工作负载分配到不同的GPU。
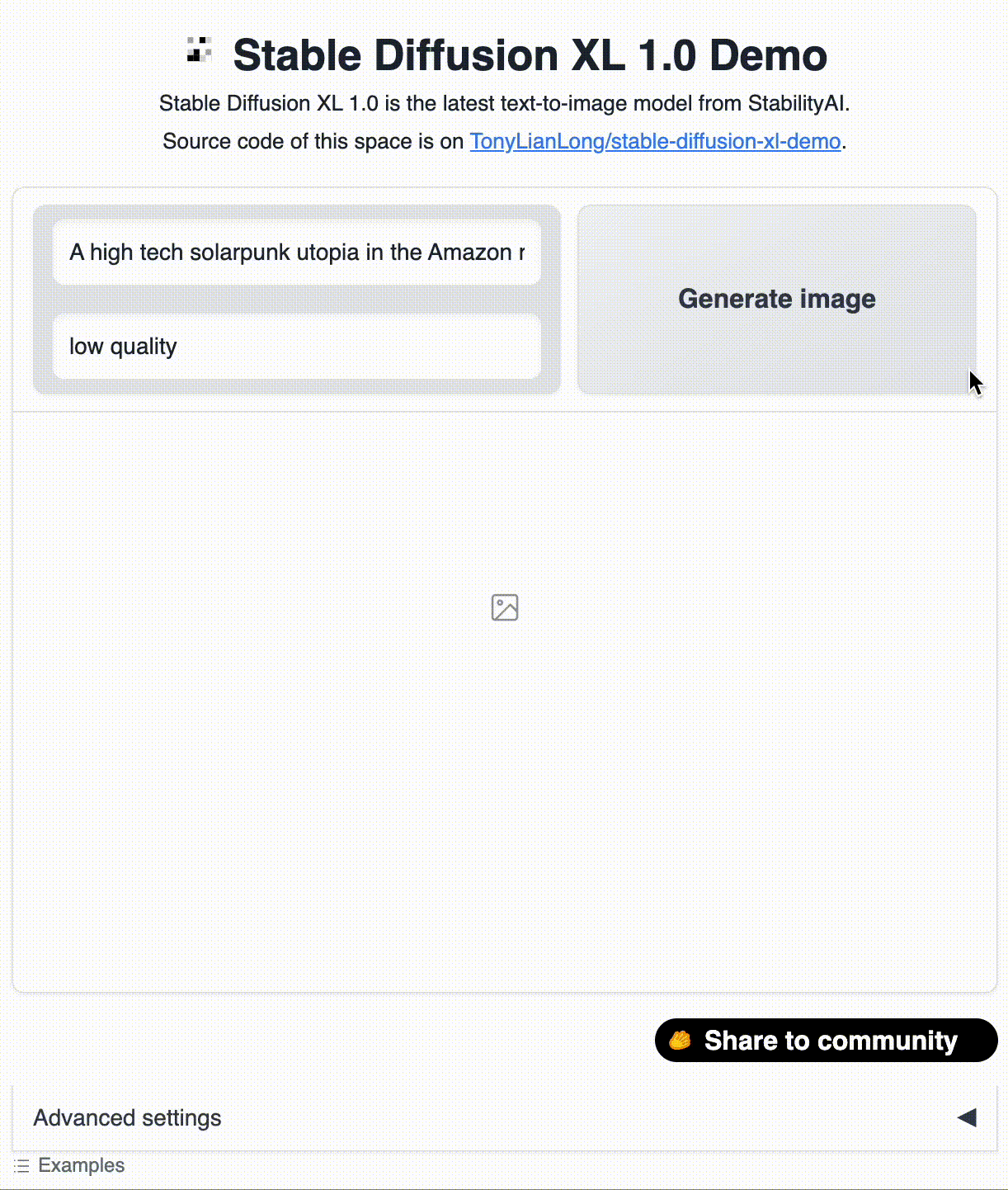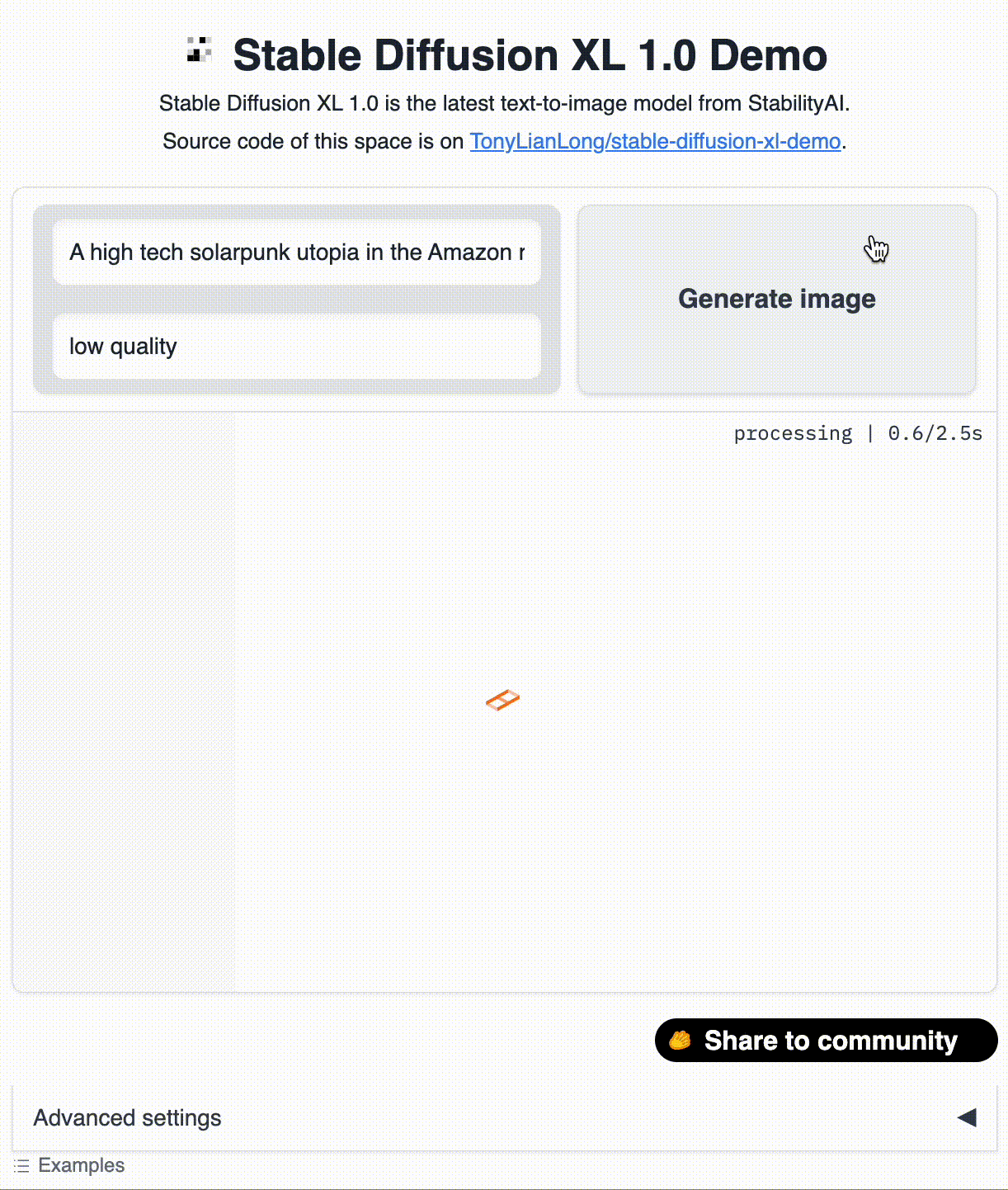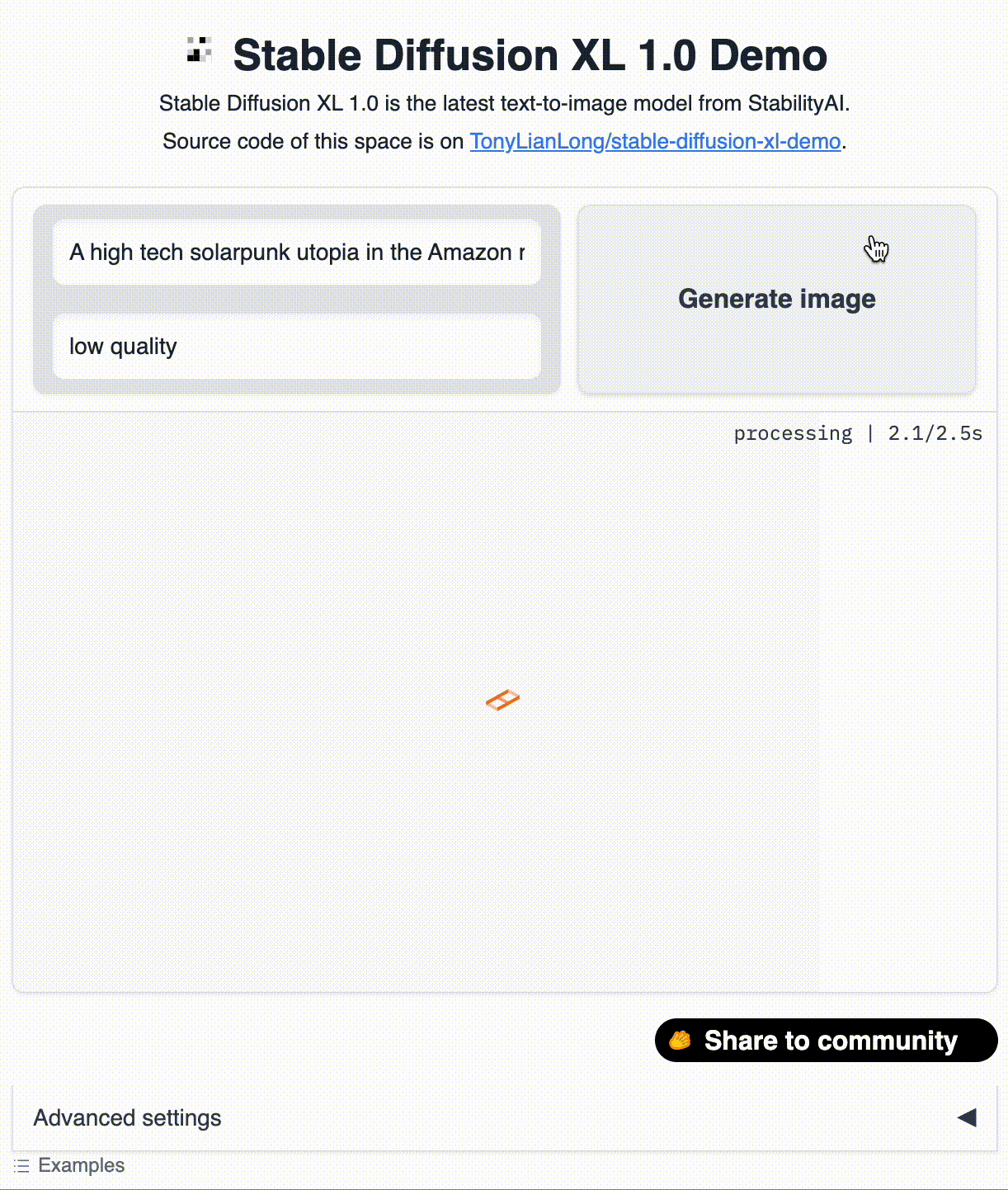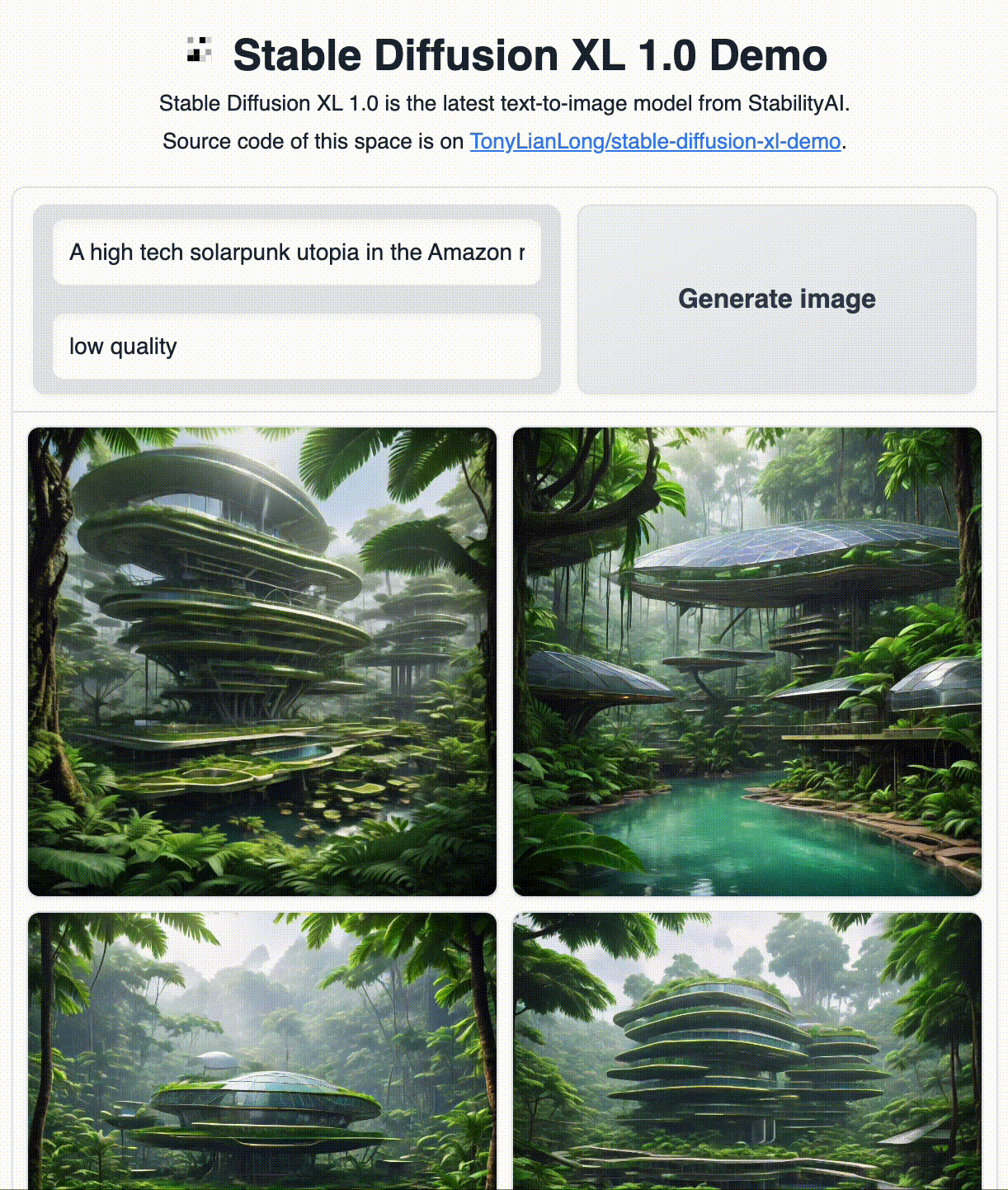
示例
更新: 这里有一个包含1200多张图像的更全面比较。SD XL和SD v2.1都在来自StableStudio的提示词上进行了基准测试。
左:SDXL。右:SD v2.1。
无需任何调整,SDXL生成的图像质量就明显优于SD v2.1!
示例1


示例2

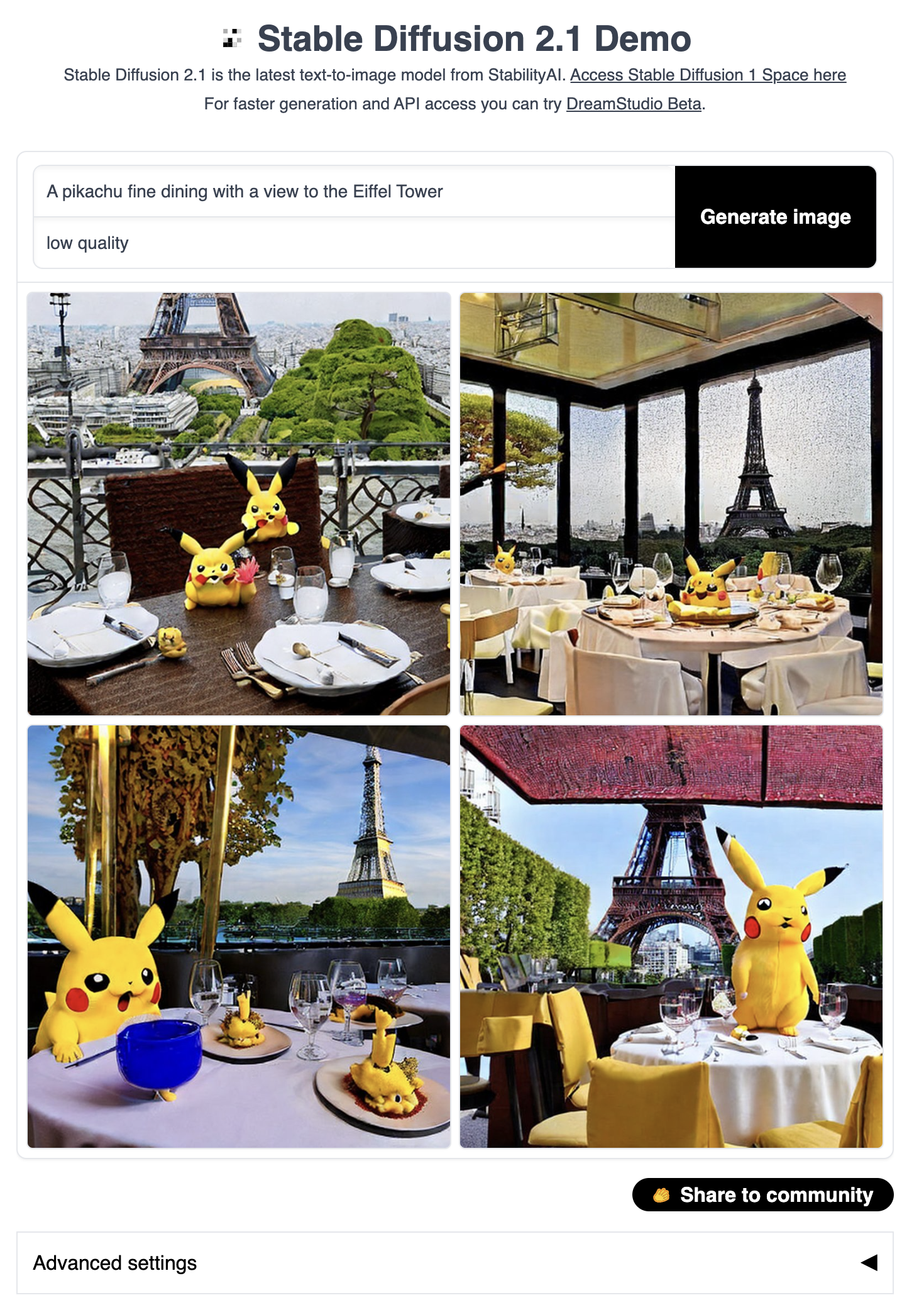
示例3
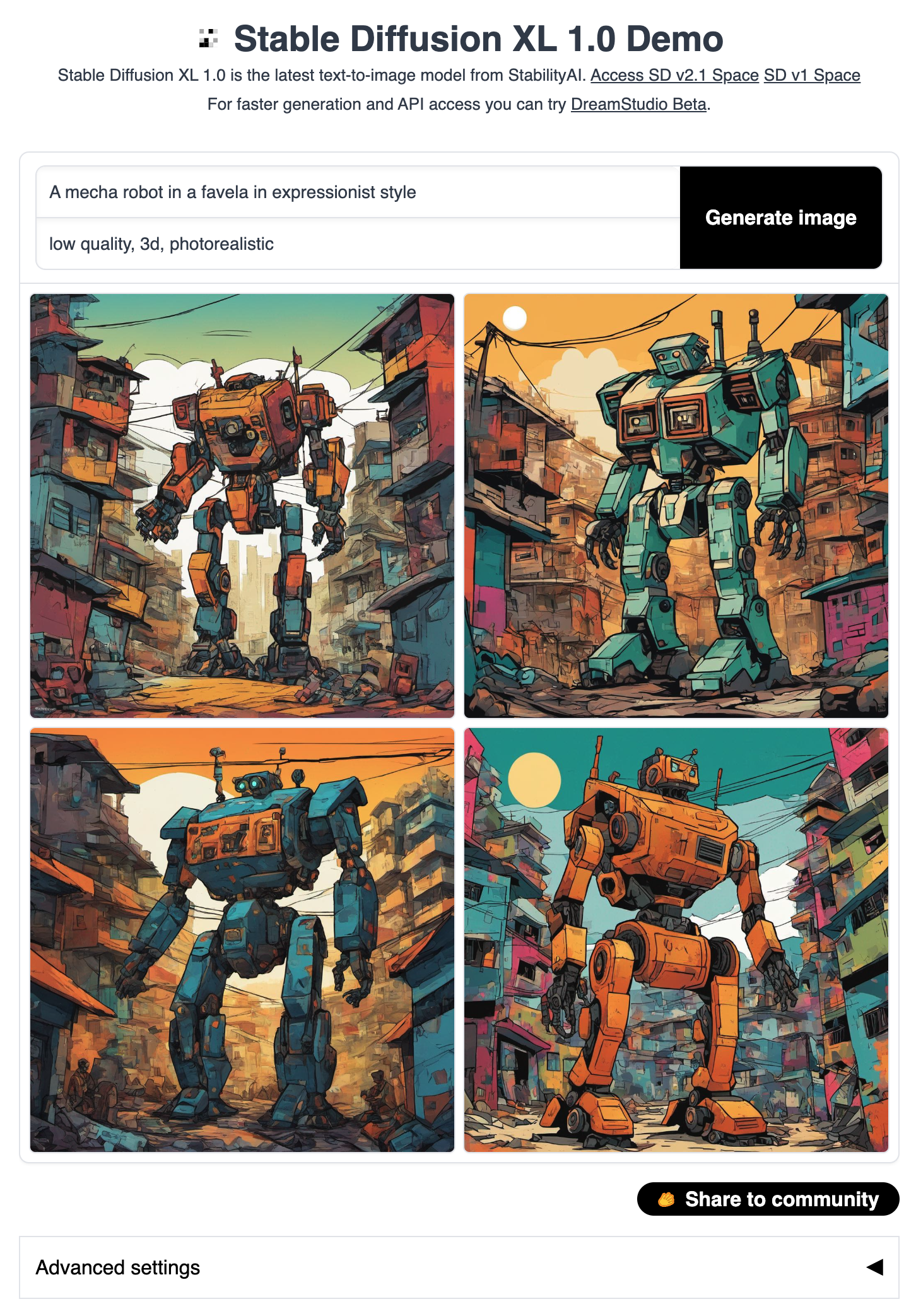
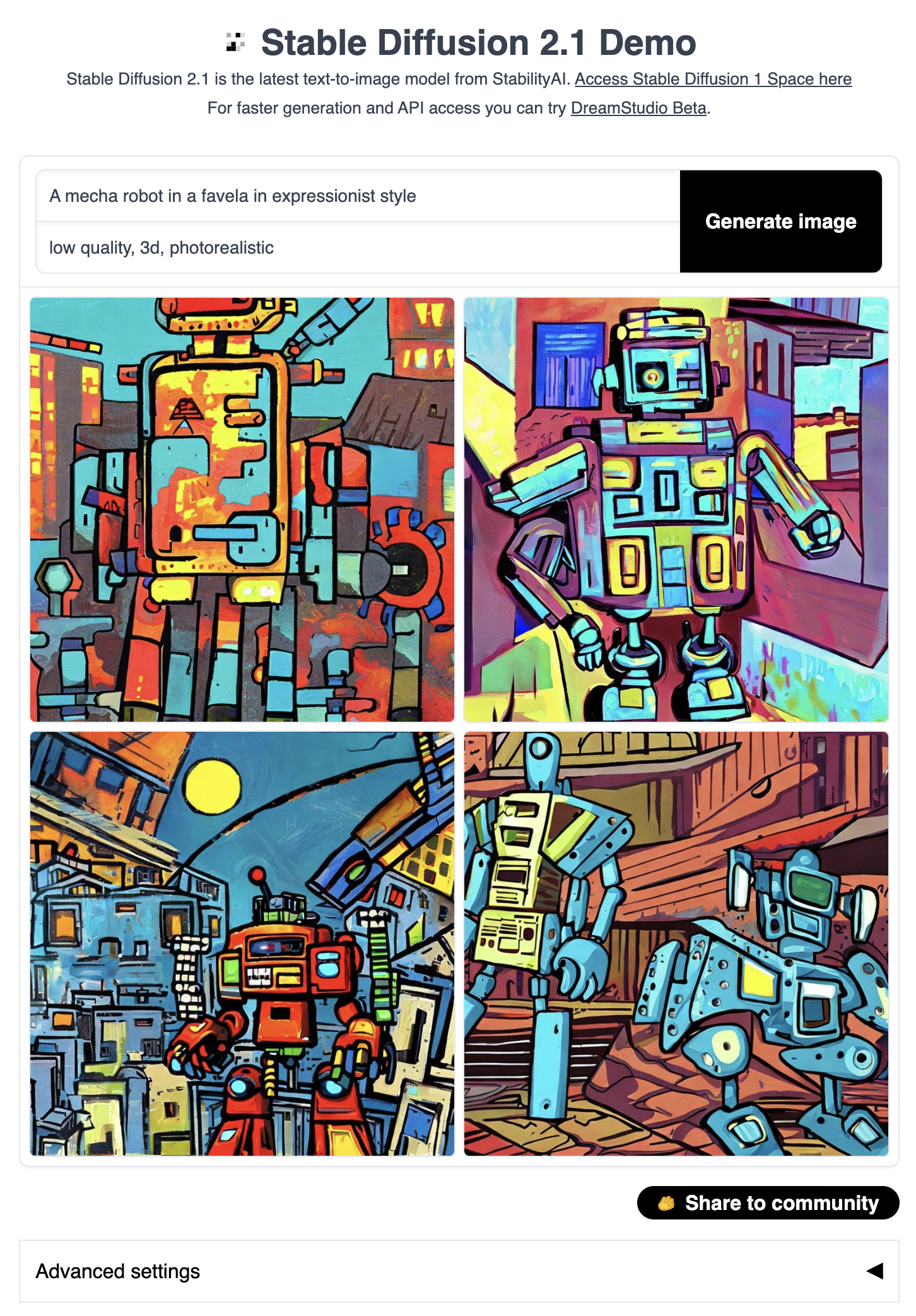

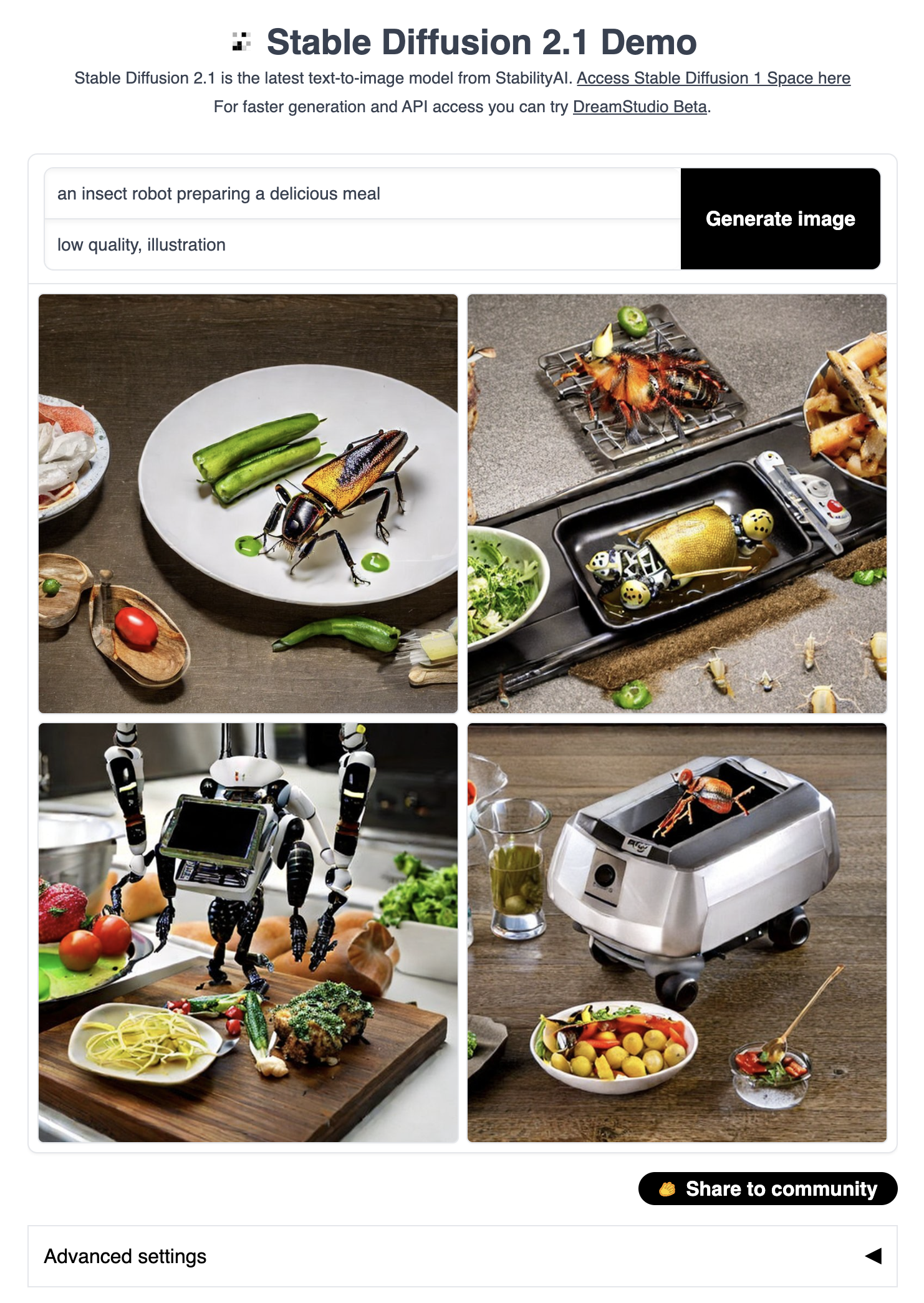
示例 5

安装
在已安装torch 2.0.1的基础上,我们还需要安装:
pip install accelerate transformers invisible-watermark "numpy>=1.17" "PyWavelets>=1.1.1" "opencv-python>=4.1.0.25" safetensors "gradio==3.11.0"
pip install git+https://github.com/huggingface/diffusers.git
启动
现在免费使用,无需填写表格。泄露的权重似乎可以在reddit上找到,但我没有使用或测试过。
有两种方式加载权重。选项1可以直接使用(无需手动下载)。如果你更喜欢从本地仓库加载,可以使用选项2。
选项1
运行以下命令自动设置权重:
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512 python app.py
选项2
如果你已在本地克隆了两个仓库(base和refiner),请更改path_to_sdxl:
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512 SDXL_MODEL_DIR=/path_to_sdxl python app.py
注意,stable-diffusion-xl-base-1.0和stable-diffusion-xl-refiner-1.0应放在同一目录下。该目录的路径应替换/path_to_sdxl。
支持torch.compile
启用torch.compile将使整体推理更快。然而,这会增加首次运行的开销(即,首次运行时需要等待编译)。
节省内存的方法
- 在
app.py中启用pipe.enable_model_cpu_offload()并关闭pipe.to("cuda")。 - 通过将
enable_refiner设置为False来关闭refiner。 - 更多节省内存和加速的方法。
通过环境变量设置的几个选项
USE_SSD:使用segmind/SSD-1B。这是一个更快的蒸馏SDXL模型。默认禁用。ENABLE_LCM:使用LCM LoRA。默认启用。SDXL_MODEL_DIR:本地加载SDXL。ENABLE_REFINER=true/false开启/关闭refiner(refiner用于改进生成结果)。如果启用了LCM LoRA或SSD模型,refiner默认禁用。OFFLOAD_BASE和OFFLOAD_REFINER可设置为true/false以启用/禁用模型卸载(模型卸载可节省内存,但会降低生成速度)。OUTPUT_IMAGES_BEFORE_REFINER=true/false在启用refiner时有用。输出refiner阶段前后的图像。SHARE=true/false创建公共链接(适用于分享和在colab上使用)MULTI_GPU=true/false在多GPU上启用数据并行。











