
 访问官网
访问官网 Github
Github 论文
论文FlashAvatar
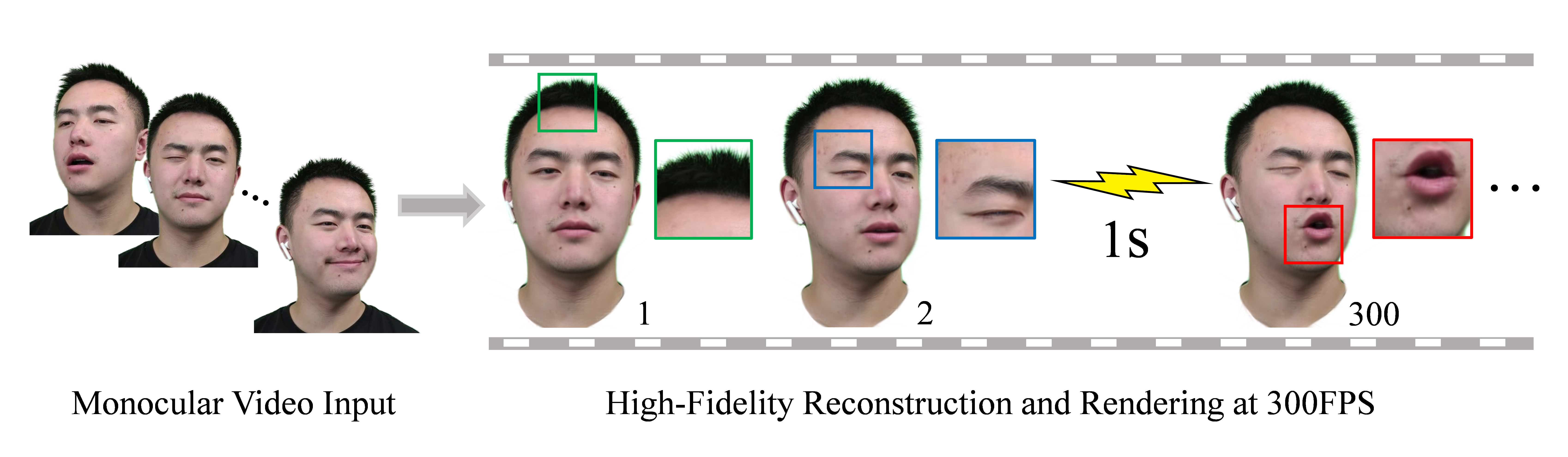 给定单目视频序列,我们提出的FlashAvatar能在几分钟内重建高保真度的数字化头像,可以在512×512分辨率下以每秒300帧以上的速度进行动画和渲染(使用Nvidia RTX 3090显卡)。
给定单目视频序列,我们提出的FlashAvatar能在几分钟内重建高保真度的数字化头像,可以在512×512分辨率下以每秒300帧以上的速度进行动画和渲染(使用Nvidia RTX 3090显卡)。
环境配置
此代码已在Nvidia RTX 3090上测试通过。
创建环境:
conda env create --file environment.yml
conda activate FlashAvatar
安装PyTorch3D:
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
conda install -c bottler nvidiacub
conda install pytorch3d -c pytorch3d
数据约定
数据按以下形式组织:
dataset
├── <id1_name>
├── alpha # 原始alpha预测
├── imgs # 提取的视频帧
├── parsing # 语义分割
├── <id2_name>
...
metrical-tracker
├── output
├── <id1_name>
├── checkpoint
├── <id2_name>
...
运行
- 评估预训练模型
python test.py --idname <id_name> --checkpoint dataset/<id_name>/log/ckpt/chkpnt.pth
- 在自己的数据上训练
python train.py --idname <id_name>
下载示例,其中包含预处理数据和预训练模型,可以尝试一下!
引用
@inproceedings{xiang2024flashavatar,
author = {Jun Xiang and Xuan Gao and Yudong Guo and Juyong Zhang},
title = {FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}











