
 Github
Github 文档
文档 论文
论文



![]()
[!提示] [2024年6月更新] 😎 第一篇全面的时间序列插补基准论文TSI-Bench:时间序列插补基准测试现已公开发布。代码在Awesome_Imputation仓库中开源。通过近35,000次实验,我们对28种插补方法、3种缺失模式(点、序列、块)、多种缺失率和8个真实世界数据集进行了全面的基准测试研究。
[2024年5月更新] 🔥 我们在
PyPOTS中将SAITS的嵌入和训练策略应用于iTransformer、FiLM、FreTS、Crossformer、PatchTST、DLinear、ETSformer、FEDformer、Informer、Autoformer、非平稳Transformer、Pyraformer、Reformer、SCINet、RevIN、Koopa、MICN、TiDE和StemGNN,使它们能够应用于时间序列插补任务。
[2024年2月更新] 🎉 我们的综述论文多变量时间序列插补的深度学习方法:一项综述已在arXiv上发布。我们全面回顾了最先进的深度学习时间序列插补方法的文献,为它们提供了分类,并讨论了该领域的挑战和未来方向。
‼️友情提醒:本文档可以帮助您解决许多常见问题,请在运行代码之前阅读它。
这是论文SAITS:基于自注意力的时间序列插补(arXiv预印本在这里)的官方代码仓库。该论文已被期刊*Expert Systems with Applications (ESWA)*接收[2022年影响因子8.665,CiteScore 12.2,JCR-Q1,CAS-Q1,CCF-C]。您可能从未听说过ESWA,但它在2016年被Google Scholar评为人工智能领域顶级出版物中排名第一(信息来源),并且根据Google Scholar指标,它仍然是排名第一的AI期刊(这里是当前排名列表供参考)。
SAITS是首个将纯自注意力应用于通用时间序列插补的工作,没有使用任何递归设计。基本上,您可以将其视为一个经过验证的时间序列插补框架,就像我们通过调整SAITS框架将2️⃣0️⃣❗️个预测模型集成到PyPOTS中一样。更广泛地说,您可以将其用于序列插补。此外,这里的代码根据MIT许可证开源。因此,欢迎您修改SAITS代码以用于您自己的研究目的和领域应用。当然,对于特定场景或数据输入,可能需要对模型结构或损失函数进行一些修改。这是一个不完整的列表,列出了在论文中引用SAITS的科学研究。
🤗 如果SAITS对您的工作有帮助,请在您的出版物中引用SAITS。如果您认为它有用,请给这个仓库加星🌟,以帮助其他人注意到SAITS。这对我们的开源研究真的意义重大。谢谢!顺便说一句,您可能也会喜欢
PyPOTS 
[!重要]
SAITS 现已在 PyPOTS 中可用,这是一个用于部分观测时间序列(POTS)数据挖掘的 Python 工具箱。 下面展示了一个使用 SAITS 训练并对 PhysioNet-2012 数据集进行插补的示例。使用 PyPOTS,轻而易举!😉
👉 点击此处查看示例 👀
# 数据预处理。虽然繁琐,但 PyPOTS 可以帮忙。
import numpy as np
from sklearn.preprocessing import StandardScaler
from pygrinder import mcar
from pypots.data import load_specific_dataset
data = load_specific_dataset('physionet_2012') # PyPOTS 将自动下载并解压数据。
X = data['X']
num_samples = len(X['RecordID'].unique())
X = X.drop(['RecordID', 'Time'], axis = 1)
X = StandardScaler().fit_transform(X.to_numpy())
X = X.reshape(num_samples, 48, -1)
X_ori = X # 保留 X_ori 用于验证
X = mcar(X, 0.1) # 随机保留 10% 的观测值作为真实值
dataset = {"X": X} # X 作为模型输入
print(X.shape) # (11988, 48, 37),11988 个样本,每个样本有 48 个时间步和 37 个特征
# 模型训练。这是 PyPOTS 的表演时间。
from pypots.imputation import SAITS
from pypots.utils.metrics import calc_mae
saits = SAITS(n_steps=48, n_features=37, n_layers=2, d_model=256, d_ffn=128, n_heads=4, d_k=64, d_v=64, dropout=0.1, epochs=10)
# 这里我使用整个数据集作为训练集,因为真实值对模型不可见,你也可以将其分为训练/验证/测试集
saits.fit(dataset) # 在数据集上训练模型
imputation = saits.impute(dataset) # 对原始缺失值和人为缺失值进行插补
indicating_mask = np.isnan(X) ^ np.isnan(X_ori) # 用于计算插补误差的指示掩码
mae = calc_mae(imputation, np.nan_to_num(X_ori), indicating_mask) # 在真实值(人为缺失值)上计算平均绝对误差
saits.save("save_it_here/saits_physionet2012.pypots") # 保存模型以供将来使用
saits.load("save_it_here/saits_physionet2012.pypots") # 重新加载序列化的模型文件以进行后续插补或训练
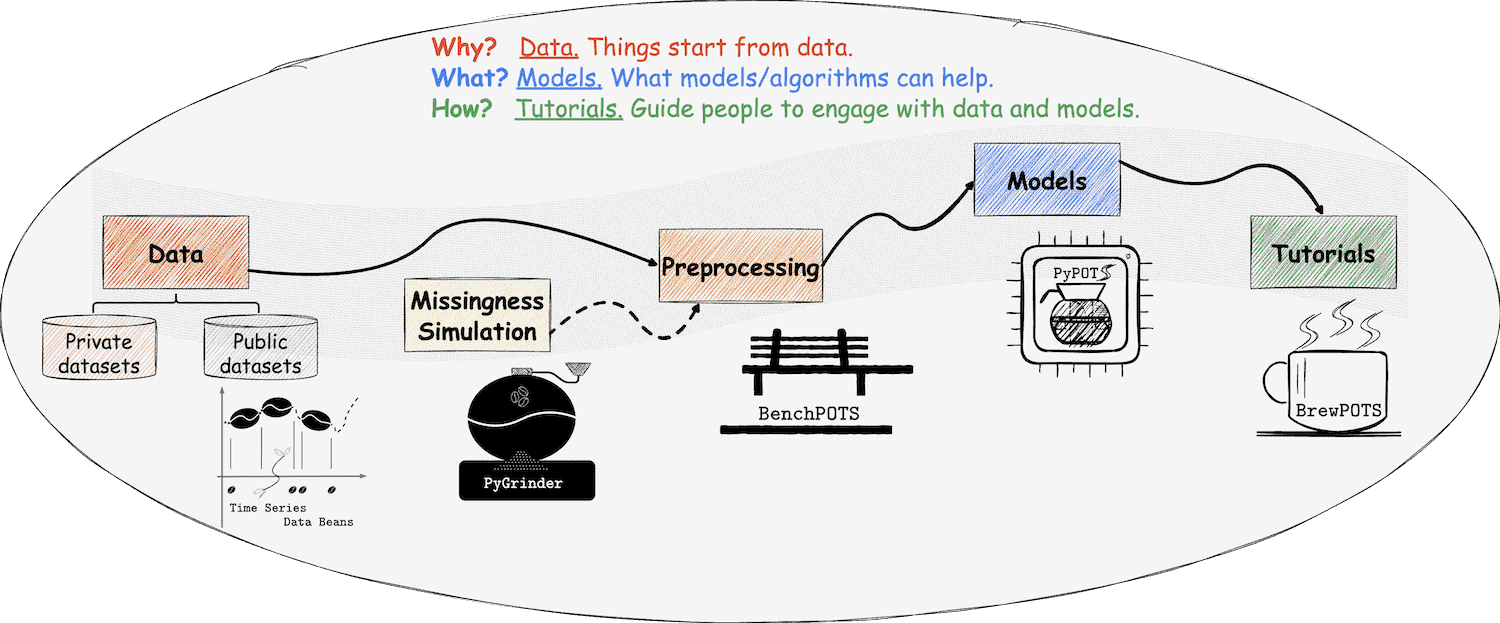
☕️ 欢迎来到 PyPOTS 的宇宙。尽情享受吧!
❖ 动机和性能
⦿ 动机:SAITS 的主要开发目的是帮助克服基于 RNN 的插补模型的缺点(速度慢、内存限制和误差累积),并在部分观测时间序列上获得最先进(SOTA)的插补精度。
⦿ 性能:SAITS 在 MAE(平均绝对误差)上比 BRITS 提高了 12% ∼ 38%,训练速度提高了 2.0 ∼ 2.6 倍。此外,SAITS 在 MAE 上比 Transformer(使用我们的联合优化方法训练)提高了 2% ∼ 19%,同时具有更高效的模型结构(要获得相当的性能,SAITS 只需要 Transformer 15% ∼ 30% 的参数)。与另一个 SOTA 自注意力插补模型 NRTSI 相比,SAITS 实现了 7% ∼ 39% 更小的均方误差(在十六种情况中有九种超过 20%),同时在实践中需要更少的参数和更短的插补时间。有关 SAITS 性能的更多详细信息,请参阅我们的完整论文。
❖ 方法简要图解
这里我们只展示了我们方法的两个主要组成部分:联合优化训练方法和 SAITS 结构。有关详细描述和解释,请阅读本仓库中的完整论文 Paper_SAITS.pdf 或在 arXiv 上。

图 1:训练方法

图 2:SAITS 结构
❖ 引用 SAITS
如果您发现 SAITS 对您的工作有帮助,请按以下方式引用我们的论文, 给这个仓库⭐️星标,并推荐给您认为可能需要的其他人。🤗 谢谢!
@article{du2023saits,
title = {{SAITS: Self-Attention-based Imputation for Time Series}},
journal = {Expert Systems with Applications},
volume = {219},
pages = {119619},
year = {2023},
issn = {0957-4174},
doi = {10.1016/j.eswa.2023.119619},
url = {https://arxiv.org/abs/2202.08516},
author = {Wenjie Du and David Cote and Yan Liu},
}
或
Wenjie Du, David Cote, and Yan Liu. SAITS: Self-Attention-based Imputation for Time Series. Expert Systems with Applications, 219:119619, 2023.
😎 我们最新的时间序列插补调查和基准研究可能也与您的工作相关:
@article{du2024tsibench,
title={TSI-Bench: Benchmarking Time Series Imputation},
author={Wenjie Du and Jun Wang and Linglong Qian and Yiyuan Yang and Fanxing Liu and Zepu Wang and Zina Ibrahim and Haoxin Liu and Zhiyuan Zhao and Yingjie Zhou and Wenjia Wang and Kaize Ding and Yuxuan Liang and B. Aditya Prakash and Qingsong Wen},
journal={arXiv preprint arXiv:2406.12747},
year={2024}
}
@article{wang2024deep,
标题={多元时间序列插补的深度学习方法:一项综述},
作者={王俊 和 杜文杰 和 曹伟 和 张克力 和 王文佳 和 梁宇轩 和 温庆松},
期刊={arXiv预印本 arXiv:2402.04059},
年份={2024}
}
🔥 如果您在研究中使用PyPOTS,请同时引用以下论文:
@article{du2023pypots,
标题={{PyPOTS:一个用于部分观测时间序列数据挖掘的Python工具箱}},
作者={杜文杰},
期刊={arXiv预印本 arXiv:2305.18811},
年份={2023},
}
或
杜文杰. PyPOTS:一个用于部分观测时间序列数据挖掘的Python工具箱. arXiv, abs/2305.18811, 2023.
❖ 仓库结构
SAITS的实现在modeling目录中。
我们在configs目录中给出了我们模型的配置,在dataset_generating_scripts目录中提供了数据集链接和预处理脚本。
NNI_tuning目录包含了超参数搜索配置。
❖ 开发环境
我们开发环境的所有依赖项都列在conda_env_dependencies.yml文件中。
您可以使用anaconda命令conda env create -f conda_env_dependencies.yml快速创建一个可用的python环境。
❖ 数据集
关于数据集的下载和生成,请查看dataset_generating_scripts目录中的脚本。
❖ 快速运行
首先生成您需要的数据集。为此,请查看dataset_generating_scripts目录中的生成脚本。
数据生成后,训练和测试您的模型,例如,
# 创建一个目录来保存日志和结果
mkdir NIPS_results
# 训练模型
nohup python run_models.py \
--config_path configs/PhysioNet2012_SAITS_best.ini \
> NIPS_results/PhysioNet2012_SAITS_best.out &
# 训练期间,您可以运行以下命令来阅读训练日志
less NIPS_results/PhysioNet2012_SAITS_best.out
# 训练后,选择最佳模型并在配置文件中修改模型路径以进行测试,然后运行以下命令来测试模型
python run_models.py \
--config_path configs/PhysioNet2012_SAITS_best.ini \
--test_mode
❗️请注意,数据集和保存目录的路径在个人计算机上可能不同,请在配置文件中检查它们。
❖ 致谢
感谢Ciena、Mitacs和NSERC(加拿大自然科学与工程研究理事会)提供资金支持。 感谢Ciena提供计算资源。 感谢所有审稿人帮助提高本文的质量。 也感谢大家对这项工作的关注。
✨欢迎Star/Fork/Issue/PR!
👏 点击查看Star和Fork用户:
❖ 最后但同样重要的是
如果您有任何其他问题或有兴趣合作, 请查看我的GitHub个人资料并随时与我联系😃。











