
🐈 CatVTON: 级联是你在扩散模型虚拟试穿中所需要的全部
CatVTON是一个简单高效的虚拟试穿扩散模型,具有1) 轻量级网络(总共899.06M参数)、***2) 参数高效训练(49.57M可训练参数)和3) 简化推理(1024X768分辨率下<8G显存)***的特点。

更新
2024/08/13: 我们本地化了DensePose和SCHP以避免某些环境问题。2024/08/10: 我们的🤗 HuggingFace Space现已上线!感谢ZeroGPU的资助!2024/08/09: 提供了评估代码用于计算指标📚。2024/07/27: 我们提供了在ComfyUI上部署CatVTON的代码和工作流程💥。2024/07/24: 我们的ArXiv论文已经发布🥳!2024/07/22: 我们的应用代码已发布,在您的机器上部署并享受CatVTON吧🎉!2024/07/21: 我们的推理代码和权重 🤗已发布。2024/07/11: 我们的在线演示已发布😁。
安装
创建conda环境并安装依赖
conda create -n catvton python==3.9.0
conda activate catvton
cd CatVTON-main # 或者您的CatVTON项目目录路径
pip install -r requirements.txt
部署
ComfyUI工作流程
我们修改了主要代码,以便在ComfyUI上轻松部署CatVTON。由于代码结构不兼容,我们在Releases中发布了这部分内容,其中包括放置在ComfyUI的custom_nodes下的代码和我们的工作流JSON文件。
要将CatVTON部署到您的ComfyUI,请按照以下步骤操作:
- 安装CatVTON和ComfyUI的所有依赖,参考CatVTON安装指南和ComfyUI安装指南。
- 下载
ComfyUI-CatVTON.zip并解压到您的ComfyUI项目(从ComfyUI克隆)的custom_nodes文件夹下。 - 运行ComfyUI。
- 下载
catvton_workflow.json并将其拖入您的ComfyUI网页,尽情享受吧😆!
Windows系统下的问题,请参考issue#8。
首次运行CatVTON工作流时,权重文件将自动下载,通常需要几十分钟。
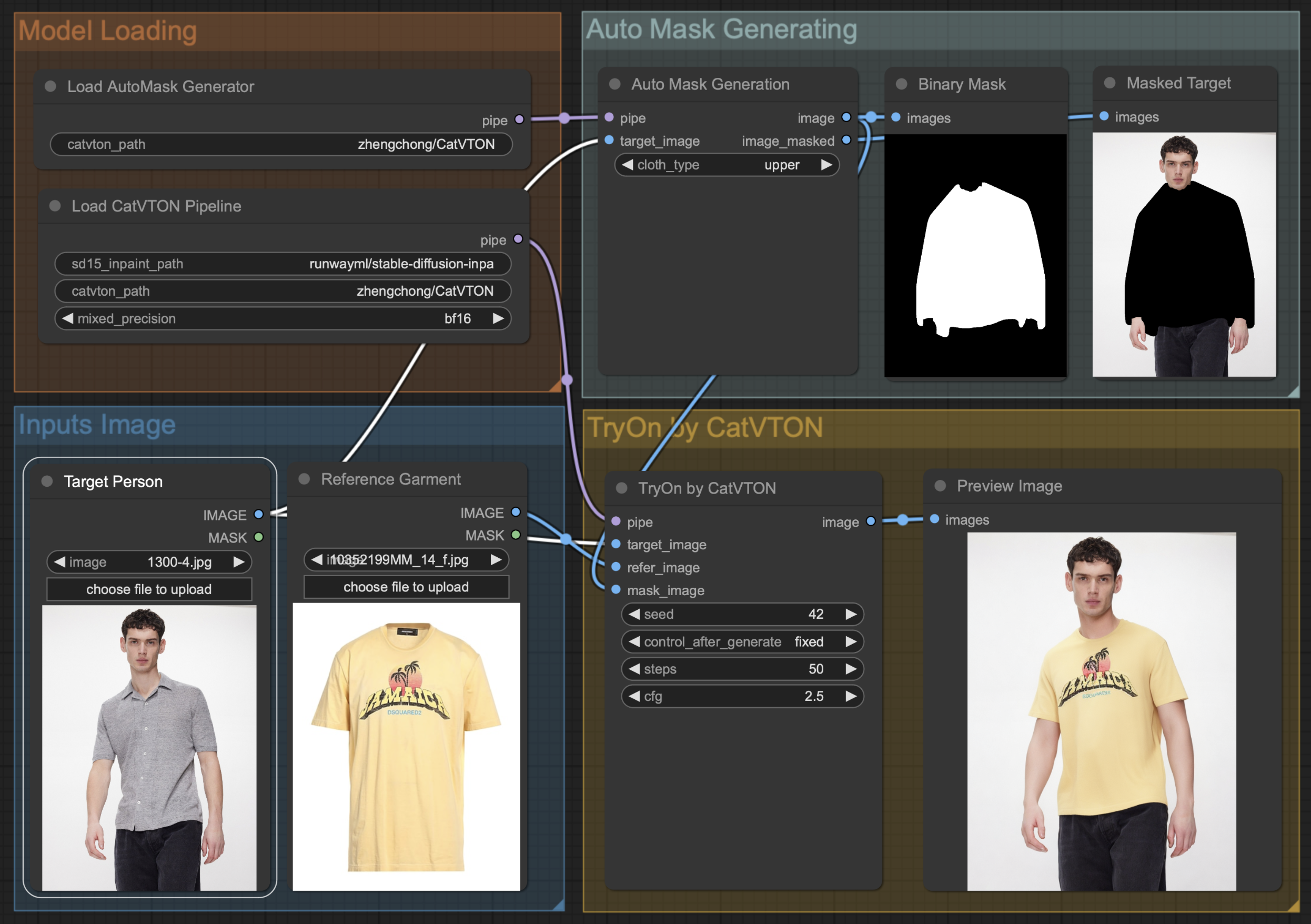
Gradio应用
要在您的机器上部署CatVTON的Gradio应用,运行以下命令,检查点将自动从HuggingFace下载。
CUDA_VISIBLE_DEVICES=0 python app.py \
--output_dir="resource/demo/output" \
--mixed_precision="bf16" \
--allow_tf32
使用bf16精度时,生成分辨率为1024x768的结果仅需约8G显存。
推理
1. 数据准备
推理前,需要下载VITON-HD或DressCode数据集。 下载数据集后,文件夹结构应如下所示:
├── VITON-HD
| ├── test_pairs_unpaired.txt
│ ├── test
| | ├── image
│ │ │ ├── [000006_00.jpg | 000008_00.jpg | ...]
│ │ ├── cloth
│ │ │ ├── [000006_00.jpg | 000008_00.jpg | ...]
│ │ ├── agnostic-mask
│ │ │ ├── [000006_00_mask.png | 000008_00.png | ...]
...
├── DressCode
| ├── test_pairs_paired.txt
| ├── test_pairs_unpaired.txt
│ ├── [dresses | lower_body | upper_body]
| | ├── test_pairs_paired.txt
| | ├── test_pairs_unpaired.txt
│ │ ├── images
│ │ │ ├── [013563_0.jpg | 013563_1.jpg | 013564_0.jpg | 013564_1.jpg | ...]
│ │ ├── agnostic_masks
│ │ │ ├── [013563_0.png| 013564_0.png | ...]
...
对于DressCode数据集,我们提供了预处理无关遮罩的脚本,运行以下命令:
CUDA_VISIBLE_DEVICES=0 python preprocess_agnostic_mask.py \
--data_root_path <DressCode数据集路径>
2. 在VTIONHD/DressCode上进行推理
要在DressCode或VITON-HD数据集上运行推理,执行以下命令,检查点将自动从HuggingFace下载。
CUDA_VISIBLE_DEVICES=0 python inference.py \
--dataset [dresscode | vitonhd] \
--data_root_path <路径> \
--output_dir <路径>
--dataloader_num_workers 8 \
--batch_size 8 \
--seed 555 \
--mixed_precision [no | fp16 | bf16] \
--allow_tf32 \
--repaint \
--eval_pair
3. 计算指标
获得推理结果后,使用以下命令计算指标:
CUDA_VISIBLE_DEVICES=0 python eval.py \
--gt_folder <真实图像文件夹路径> \
--pred_folder <预测图像文件夹路径> \
--paired \
--batch_size=16 \
--num_workers=16
--gt_folder和--pred_folder应该是只包含图像的文件夹。- 要在配对设置下评估结果,使用
--paired;对于非配对设置,只需省略该参数。 --batch_size和--num_workers应根据您的机器进行调整。
致谢
我们的代码基于Diffusers修改。我们采用Stable Diffusion v1.5 inpainting作为基础模型。我们在Gradio应用和ComfyUI工作流中使用SCHP和DensePose自动生成遮罩。感谢所有贡献者!
许可
所有材料,包括代码、检查点和演示,均在Creative Commons BY-NC-SA 4.0许可下提供。您可以自由复制、重新分发、重新混合、转换和基于该项目进行非商业目的的创作,只要您给予适当的署名并以相同的许可分发您的贡献。
引用
@misc{chong2024catvtonconcatenationneedvirtual,
title={CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models},
author={Zheng Chong and Xiao Dong and Haoxiang Li and Shiyue Zhang and Wenqing Zhang and Xujie Zhang and Hanqing Zhao and Xiaodan Liang},
year={2024},
eprint={2407.15886},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.15886},
}











