
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文











ClearML
前身为 Allegro Trains
ClearML 是一个机器学习/深度学习开发和生产套件。它包含五个主要模块:
- 实验管理器 - 自动魔法般的实验跟踪、环境和结果
- MLOps/LLMOps - 机器学习/深度学习/生成式AI工作的编排、自动化和流水线解决方案(Kubernetes/云/裸金属)
- 数据管理 - 在对象存储之上完全可微的数据管理和版本控制解决方案 (S3 / GS / Azure / NAS)
- 模型服务 - 云准备好的可扩展模型服务解决方案!
- 在5分钟内部署新模型端点
- 包含由 Nvidia-Triton 支持的优化 GPU 服务支持
- 内置模型监控
- 报告 - 创建和共享支持嵌入在线内容的丰富 Markdown 文档
- :fire: 编排仪表板 - 实时丰富的仪表板,用于您的整个计算集群(云/Kubernetes/本地)
- 新功能 💥 分数GPUs - 基于容器的、驱动级 GPU 内存限制 🙀 !!!
配备这些组件的是 ClearML-server,请参见自托管 和 免费托管

| 实验管理 | 数据集 |
 |  |
| 编排 | 流水线 |
 |  |
ClearML 实验管理器
在代码中添加仅两行代码即可获得以下功能
- 完整的实验设置日志
- 完整的源代码控制信息,包括未提交的本地更改
- 执行环境(包括特定的软件包和版本)
- 超参数
- 使用
argparse/Click/PythonFire管理命令行参数及其当前使用的值 - 显式参数字典
- Tensorflow 定义(absl-py)
- Hydra 配置和覆盖
- 使用
- 完整的实验输出自动捕获
- 标准输出和标准错误
- 资源监控(CPU/GPU使用率、温度、IO、网络等)
- 模型快照(可选自动上传到中央存储:共享文件夹、S3、GS、Azure、Http)
- 工件日志和存储(共享文件夹,S3,GS,Azure,Http)
- Tensorboard/TensorboardX 标量、指标、直方图、图像、音频和视频样本
- Matplotlib & Seaborn
- ClearML Logger 界面,提供完全的灵活性。
- 广泛的平台支持和集成
- 支持的ML/DL框架:PyTorch(包括ignite / lightning),Tensorflow,Keras,AutoKeras,FastAI,XGBoost,LightGBM,MegEngine和Scikit-Learn
- 无缝集成(包括版本控制)Jupyter Notebook 和 PyCharm 远程调试
开始使用 ClearML
-
免费注册ClearML 托管服务(或者,您可以设置自己的服务器,参见此处)。
ClearML 演示服务器: ClearML 默认情况下不再使用演示服务器。要启用演示服务器,请设置
CLEARML_NO_DEFAULT_SERVER=0> 环境变量。无需凭证,但在演示服务器上启动的实验是公开的,因此请确保不使用演示服务器启动敏感实验。 -
安装
clearmlpython包:pip install clearml -
通过创建凭证将 ClearML SDK 连接到服务器,然后执行以下命令并按照说明操作:
clearml-init -
在代码中添加两行:
from clearml import Task task = Task.init(project_name='examples', task_name='hello world')
完成了!现在,您的处理输出的一切内容都会自动记录到 ClearML 中。
接下来,自动化!了解更多关于 ClearML 的一键自动化 这里。
ClearML 架构
ClearML 运行时组件:
- ClearML Python 包 - 通过添加仅两行代码,将 ClearML 集成到您的现有脚本中,并可选地通过 ClearML 的强大而多功能的类和方法集扩展您的实验和其他工作流。
- ClearML 服务器 - 用于存储实验、模型和工作流数据;支持 Web UI 实验管理器和 MLOps 自动化,以实现可重复性和调优。它作为托管服务和开源软件提供,您可以部署自己的 ClearML 服务器。
- ClearML 代理 - 用于 MLOps 协同、实验和工作流的可重复性和可扩展性。
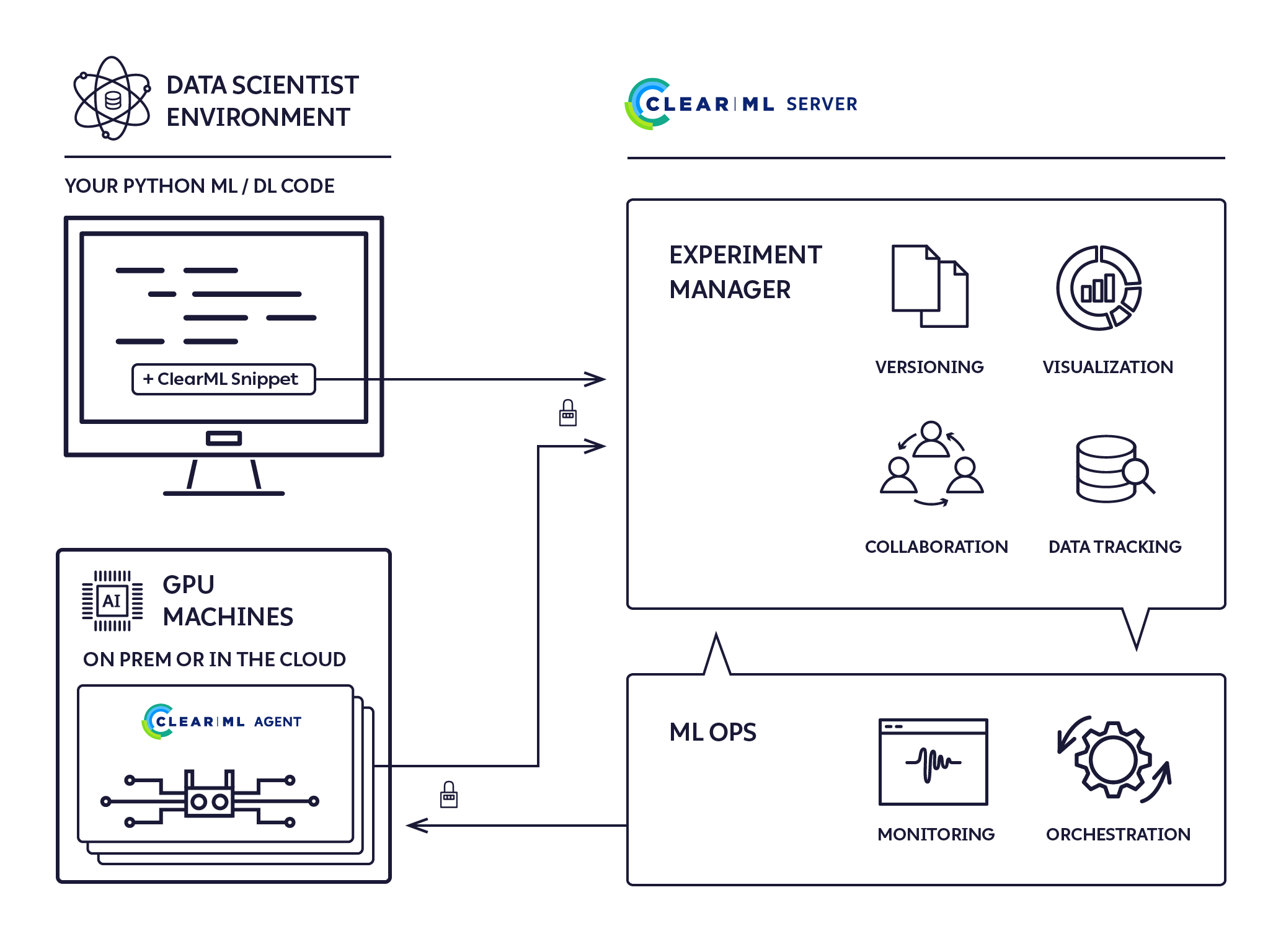
其他模块
- clearml-session - 在任何 docker 内启动远程 JupyterLab / VSCode-server,无论是云端还是本地机器
- clearml-task - 在远程机器上运行任意代码库,记录完整的远程日志,包括 Tensorboard,Matplotlib 和控制台输出
- clearml-data - CLI 用于管理和版本化您的数据集,包括从 S3/GS/Azure/NAS 创建/上传/下载数据
- AWS 自动扩展器 - 根据您的工作负载自动启动 EC2 实例,并具有预配置的预算!无需 AKE!
- 超参数优化 - 使用黑盒方法和最先进的贝叶斯优化算法优化任意代码
- 自动化管道 - 基于现有实验/任务构建管道,支持构建管道的管道!
- Slack 集成 - 将实验进度/失败直接报告给 Slack(完全可定制!)
为什么选择 ClearML?
ClearML 是我们的解决方案,它解决了我们与众多机器学习/深度学习研究人员和开发人员共享的一个问题:训练生产级深度学习模型是一个光荣但混乱的过程。ClearML 通过关联代码版本控制、研究项目、性能指标和模型出处来跟踪和控制这个过程。
我们专门设计了 ClearML,以实现轻松集成,使团队可以保留现有的方法和实践。
- 日常使用它,以提升团队的协作和可见性
- 一键从任何实验创建远程任务
- 自动化流程并创建管道,以收集您的实验日志、输出和数据
- 使用最简单的界面,将所有数据存储在任何对象存储解决方案中
- 通过在 ClearML 平台上编目所有数据,使您的数据透明化
我们相信 ClearML 是具有突破性的。我们希望建立一个新标准,真正无缝集成实验管理、MLOps 和数据管理。
我们是谁
ClearML 得到了您的支持以及clear.ml 团队的支持,团队帮助企业公司构建可扩展的 MLOps。
我们构建 ClearML,以跟踪和控制训练生产级深度学习模型这个光荣但混乱的过程。我们致力于积极支持和扩展 ClearML 的功能。
我们承诺始终保持向后兼容,确保所有日志、数据和管道始终随您升级。
许可证
Apache 许可证,版本 2.0(更多信息请参见许可证)
如果 ClearML 是您开发过程/项目/出版物的一部分,请引用我们 :heart: :
@misc{clearml,
title = {ClearML - 您的完整 MLOps 堆栈的开源工具},
year = {2023},
note = {软件可从 http://github.com/allegroai/clearml 获得},
url={https://clear.ml/},
author = {ClearML},
}
文档、社区和支持
有关更多信息,请参见 官方文档 和 YouTube 上的视频。
如果您有任何问题,请在我们的Slack 频道上发帖,或者在 stackoverflow 上使用 'clearml' 标签 (之前的 trains 标签) 标记您的问题。
有关功能请求或错误报告,请使用 GitHub issues。
此外,您始终可以通过 info@clear.ml 联系我们。
贡献
欢迎提交 PR :heart: 详细信息请参见 ClearML 贡献指南。
May the force (and the goddess of learning rates) be with you!











