
 访问官网
访问官网 Github
Github 文档
文档 论文
论文
一种用于图数据存储和检索的开源标准数据文件格式
![]()
![]()

![]()

GraphAr是什么?
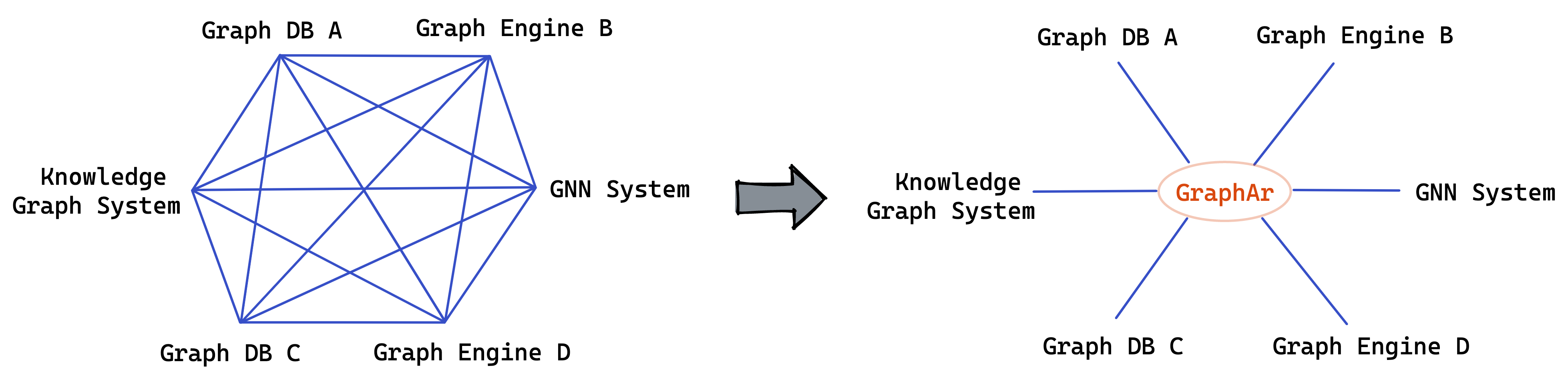
图处理是多种现实应用的基本构建模块,如社交网络分析、数据挖掘、网络路由和科学计算等。
GraphAr("Graph Archive"的缩写)是一个旨在让各种应用和系统(包括内存和外存储、数据库、图计算系统和交互式图查询框架)能够方便高效地构建和访问图数据的项目。
它可用于图数据的导入/导出和持久存储,从而减轻系统协作时的负担。此外,它还可以作为图处理应用的直接数据源。
为实现这一目标,GraphAr项目提供:
- GraphAr格式:一种用于存储图数据的标准化、与系统无关的格式
- 库:一套用于读取、写入和转换GraphAr格式数据的库
通过使用GraphAr,您可以:
- 以与系统无关的方式使用GraphAr格式存储和持久化您的图数据
- 使用库轻松访问和生成GraphAr格式数据
- 利用Apache Spark快速操作和转换您的GraphAr格式数据
GraphAr格式
GraphAr格式专为存储属性图而设计。它使用元数据记录图的所有必要信息,并以分块方式维护实际数据。
属性图由顶点和边组成,每个顶点包含一个唯一标识符和:
- 描述顶点类型的文本标签。
- 一组属性,每个属性可以用键值对表示。
每条边包含一个唯一标识符和:
- 出发顶点(源点)。
- 到达顶点(目标点)。
- 描述两个顶点之间关系的文本标签。
- 一组属性。
以下是一个包含两种类型顶点("person"和"comment")和三种类型边的属性图示例。

GraphAr中的顶点
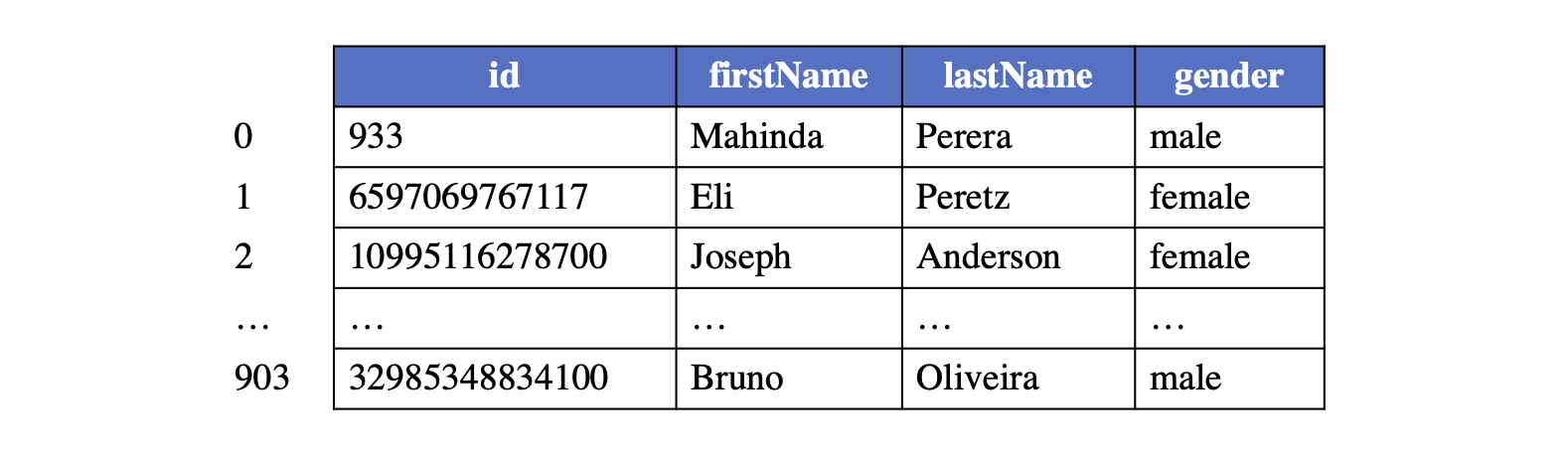
顶点逻辑表
每种类型的顶点(具有相同标签)构成一个逻辑顶点表,每个顶点在该类型内分配一个从0开始的全局索引(称为内部顶点ID),对应于顶点在逻辑顶点表中的行号。下面提供了一个标签为"person"的顶点逻辑表布局示例供参考。
给定内部顶点ID和顶点标签,可以唯一识别一个顶点,并从该表中访问其相应的属性。内部顶点ID进一步用于在维护图拓扑时识别源顶点和目标顶点。
顶点物理表
逻辑顶点表将被分割成多个连续的顶点块,以提高读写效率。为了保持随机访问能力,同一标签的顶点块大小是固定的。为了支持访问所需属性而避免从文件中读取所有属性,并且能够在不修改现有文件的情况下为顶点添加属性,逻辑表的列将被划分为几个列组。
以person顶点表为例,如果块大小设置为500,逻辑表将被分成500行的子逻辑表,最后一个可能少于500行。用于维护属性的列也将被划分为不同的组(例如,我们的示例中为2组)。因此,为存储示例逻辑表,共创建了4个物理顶点表,如下图所示。

[!注意] 为了高效利用Parquet等负载文件格式的过滤下推功能,内部顶点ID作为一列存储在负载文件中。由于内部顶点ID是连续的,负载文件格式可以对内部顶点ID列使用差分编码,这不会给存储带来太多开销。
GraphAr中的边
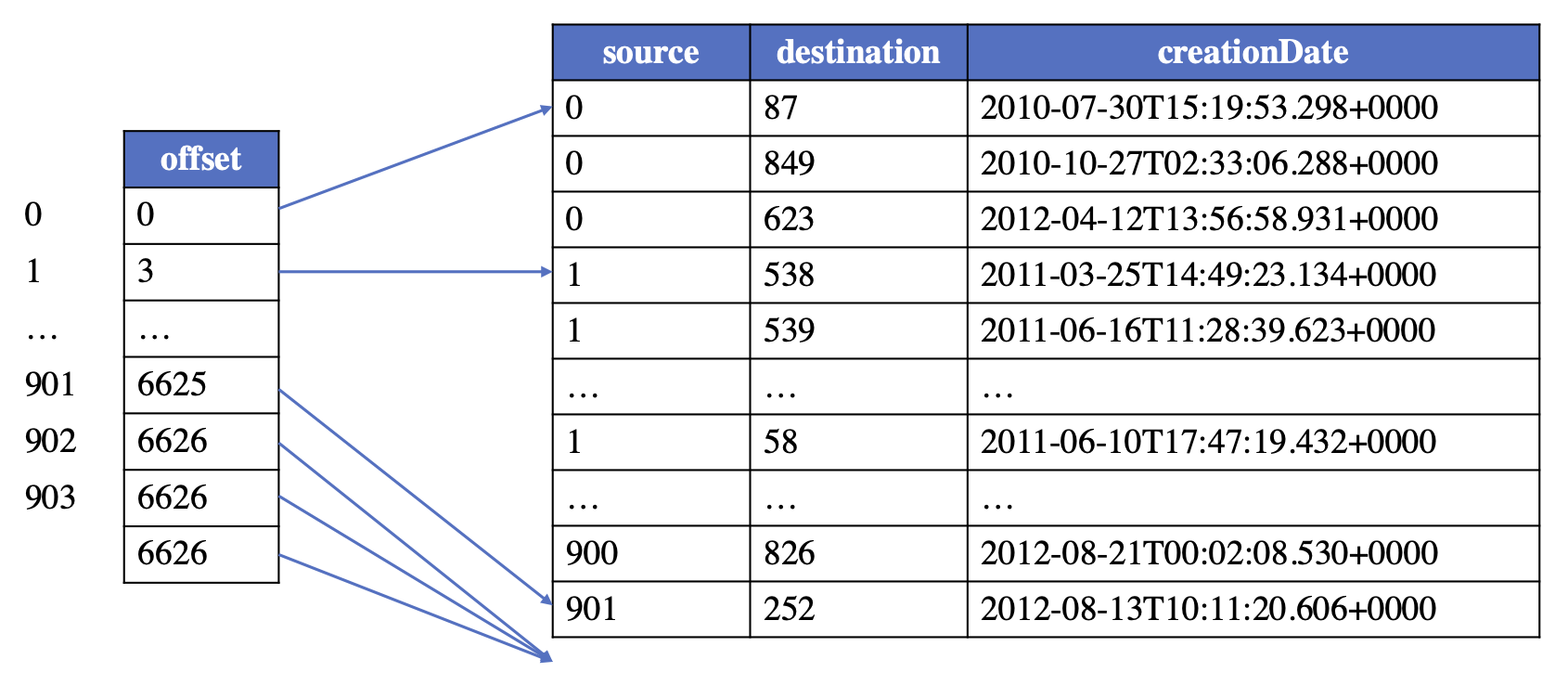
边逻辑表
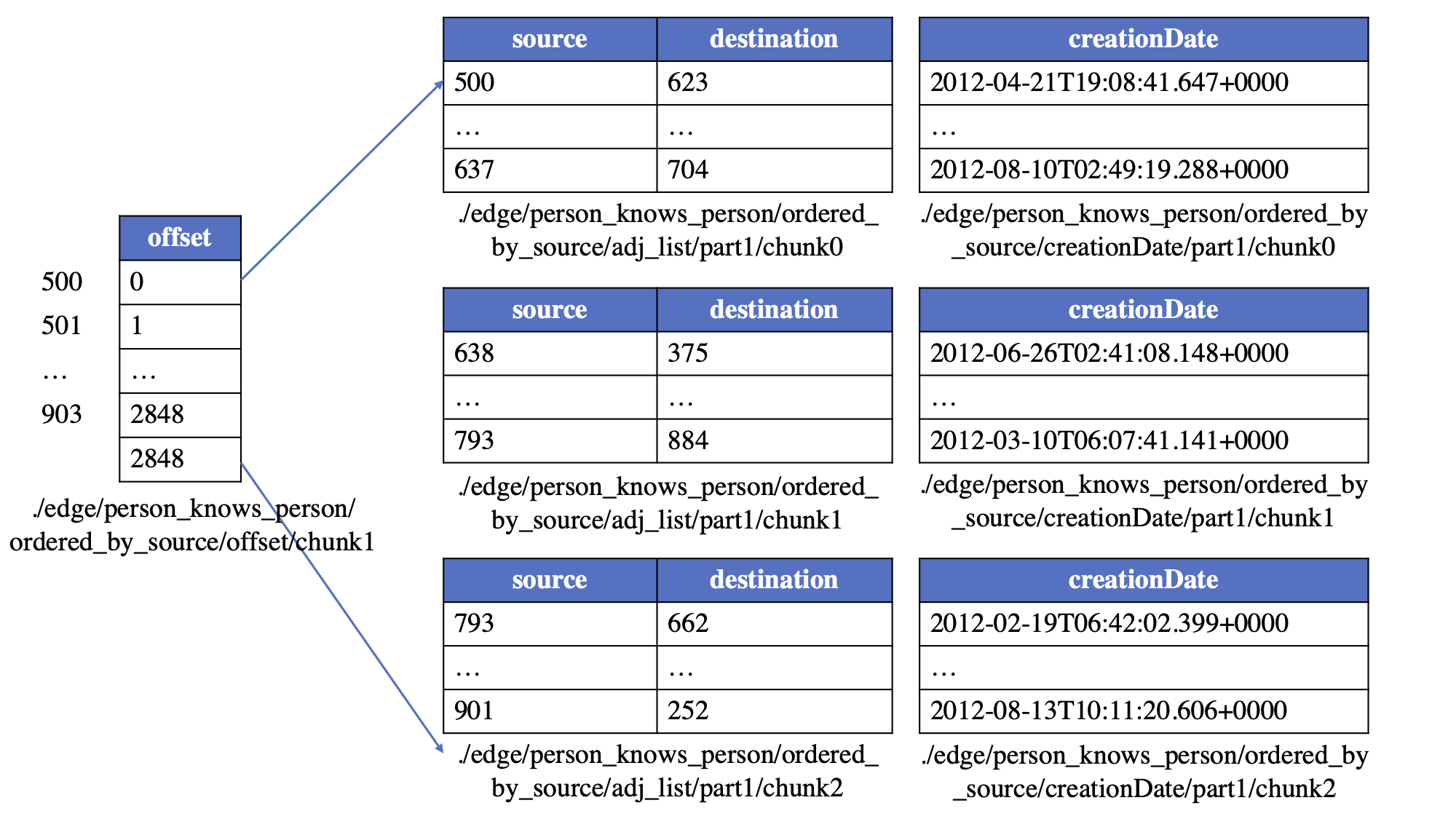
为了维护一种类型的边(具有相同的源标签、边标签和目标标签的三元组),建立了一个逻辑边表。为了支持从图存储文件快速创建图,逻辑边表可以以类似于CSR/CSC的方式维护拓扑信息,即边按源或目标的内部顶点ID排序。这样,需要一个偏移表来存储每个顶点的边的起始偏移,具有相同源/目标的边将连续存储在逻辑表中。
以person knows person边的逻辑表为例,逻辑边表如下所示:
边物理表
与顶点表一样,逻辑边表也被分割成一些子逻辑表,每个子逻辑表包含源(或目标)顶点在同一顶点块中的边。根据分区策略和边的顺序,边可以按照以下四种类型之一在GraphAr中存储:
- ordered_by_source:逻辑表中的所有边按源顶点的内部ID排序并进一步分区,可视为CSR格式。
- ordered_by_dest:逻辑表中的所有边按目标顶点的内部ID排序并进一步分区,可视为CSC格式。
- unordered_by_source:使用源顶点的内部ID作为分区键将边分到不同的子逻辑表中,每个子逻辑表中的边是无序的,可视为COO格式。
- unordered_by_dest:使用目标顶点的内部ID作为分区键将边分到不同的子逻辑表中,每个子逻辑表中的边是无序的,也可视为COO格式。
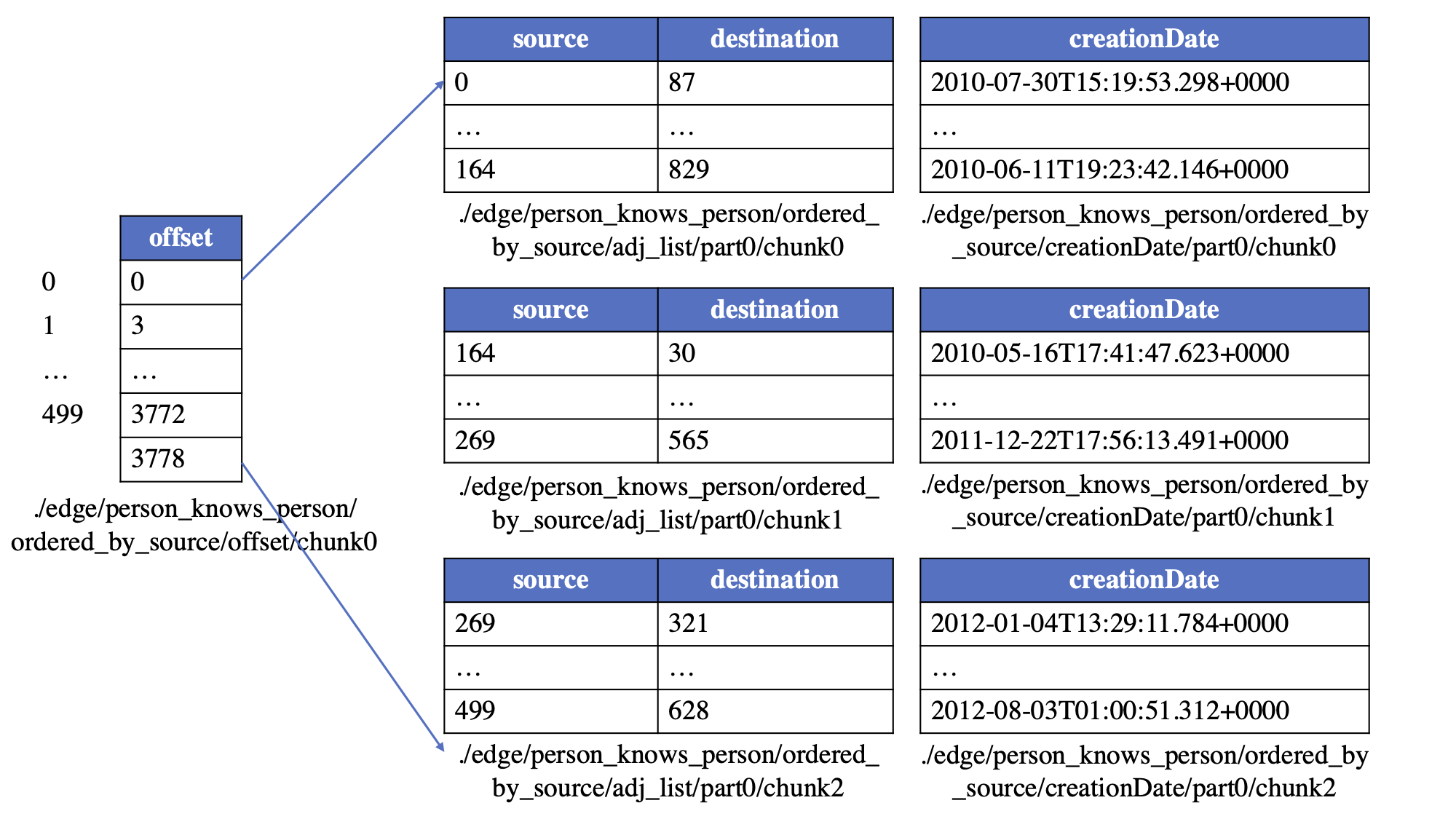
之后,子逻辑表进一步划分为预定义固定行数(称为边块大小)的边块。最终,边块以如下方式分离成物理表:
- 邻接表(仅包含两列:源顶点和目标顶点的内部ID)。
- 0个或多个边属性表,每个表包含一组属性。
此外,对于ordered_by_source或ordered_by_dest的边,还会有一个偏移表。偏移表用于记录每个顶点的边的起始点。偏移表的分区应与相应的顶点表分区一致。每个偏移块的第一行始终为0,表示相应边子逻辑表的起始点。
以"人认识人"的边为例。假设顶点块大小设为500,边块大小为1024,且边按ordered_by_source排序,则边可以保存在以下物理表中:
库
GraphAr提供了一系列用于读取、写入和转换文件的库。目前,以下库可用,并计划扩展支持更多编程语言。
C++库
有关C++库的构建详情,请参阅GraphAr C++库。
Scala with Spark库
有关Scala with Spark库的详情,请参阅GraphAr Spark库。
Java库
[!注意] Java库正在开发中。
GraphAr Java库通过绑定C++库(当前版本v0.10.0)创建,使用Alibaba-FastFFI实现。有关Java库的构建详情,请参阅GraphAr Java库。
Python with PySpark库
[!注意] Python with PySpark库正在开发中。
PySpark库作为GraphAr Spark库的绑定开发。有关PySpark库的详情,请参阅GraphAr PySpark库。
贡献
许可证
GraphAr在Apache许可证2.0下分发。请注意,第三方库可能与GraphAr的许可证不同。
出版物
- Xue Li, Weibin Zeng, Zhibin Wang, Diwen Zhu, Jingbo Xu, Wenyuan Yu, Jingren Zhou. 通过GraphAr增强数据湖:使用专用存储方案实现高效图数据管理[J]。arXiv预印本arXiv:2312.09577,2023。
@article{li2023enhancing,
author = {Xue Li and Weibin Zeng and Zhibin Wang and Diwen Zhu and Jingbo Xu and Wenyuan Yu and Jingren Zhou},
title = {Enhancing Data Lakes with GraphAr: Efficient Graph Data Management with a Specialized Storage Scheme},
year = {2023},
url = {https://doi.org/10.48550/arXiv.2312.09577},
doi = {10.48550/ARXIV.2312.09577},
eprinttype = {arXiv},
eprint = {2312.09577},
biburl = {https://dblp.org/rec/journals/corr/abs-2312-09577.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}











