
 访问官网
访问官网 Github
Github 文档
文档批处理网关
批处理网关使在Kubernetes上运行Spark服务变得简单。 它允许用户通过直观的API调用在Kubernetes上提交、查看和删除Spark应用程序,而无需过多关心背后的细节。 它还可以配置多个Spark集群以实现服务的水平扩展。
概述
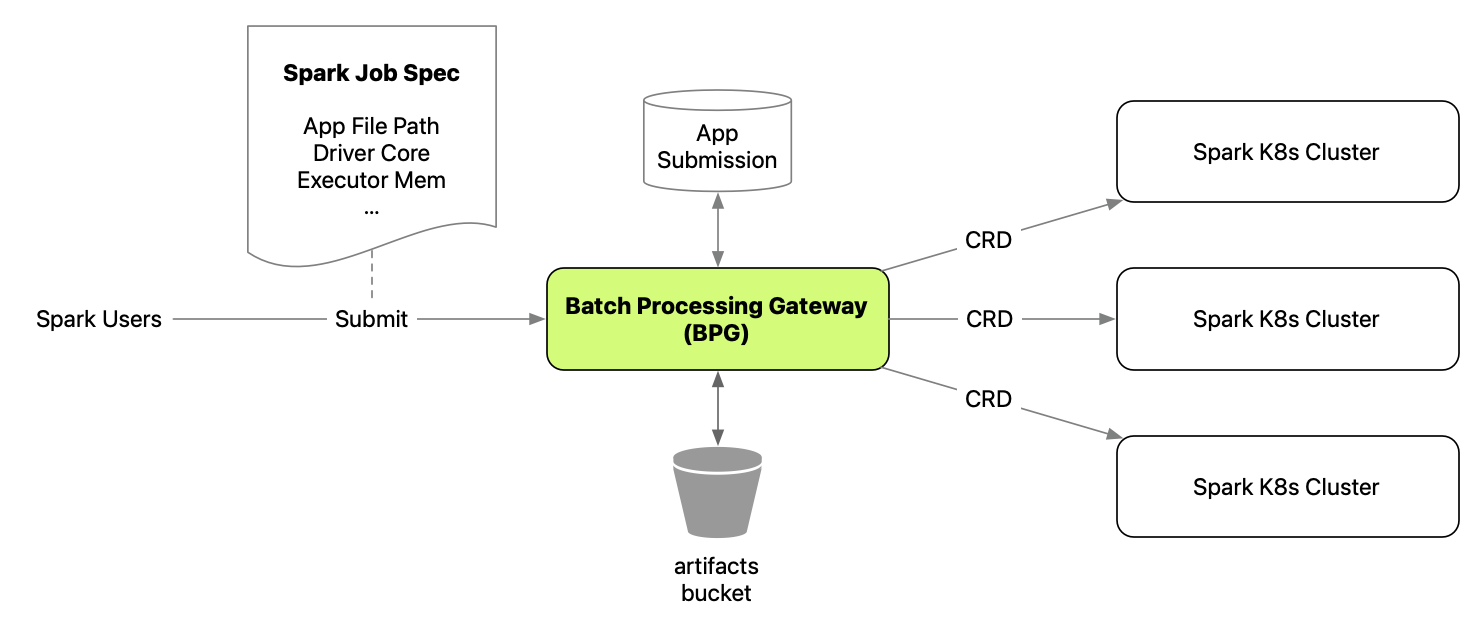
批处理网关(BPG)是整个Spark服务堆栈的前端,通常包括一个网关实例和多个Spark K8s集群。
Spark应用程序提交的典型流程:
- Spark用户将应用程序制品(.jar、.py、.zip等)发布到S3制品存储桶
- 用户编写作业规范,包括作业路径、驱动程序核心、执行器内存等关键信息,并将其提交到REST端点
- BPG解析请求,将其转换为Spark on K8s Operator支持的自定义资源定义(CRD)
- 使用基于队列和权重的配置,BPG选择一个Spark K8s集群并向其提交CRD
- Spark on K8s Operator处理CRD并使用
spark-submit提交Spark应用程序
制品存储桶
S3存储桶用于存放所有应用程序制品,包括主应用程序文件、依赖项等。 BPG提供上传API,供用户在启动Spark应用程序之前上传制品。
应用程序提交数据库
BPG生成一个提交ID作为已提交应用程序的唯一标识符。
当应用程序提交到Spark K8s集群时,Spark将生成一个应用程序ID,这也是一个唯一标识符。
应用程序提交数据库维护ID映射,因此用户可以使用提交ID和应用程序ID来查找应用程序。
数据库中还维护了应用程序的其他几个元数据字段,以启用某些功能。
要了解应用程序提交数据库是如何填充的,请参阅应用程序监视器部分。
application_submission模式(部分)
| 字段 | 类型 | 填充者 | 说明 |
|---|---|---|---|
| submission_id | varchar(255) | 提交 | BPG生成的唯一ID |
| user | varchar(255) | 提交 | 提交应用程序的用户 |
| app_name | varchar(255) | 监视器 | 应用程序规范中指定的应用程序名称 |
| spark_version | varchar(255) | 提交 | 应用程序规范中指定的Spark版本 |
| queue | varchar(255) | 提交 | 应用程序规范中指定的队列 |
| status | varchar(255) | 监视器 | 应用程序的最新状态 |
| app_id | varchar(255) | 监视器 | Spark K8s集群生成的唯一ID |
| request_body | text | 提交 | 用户指定的原始请求主体 |
| created_time | timestamp | 提交 | 使用系统当前时间戳(GMT)作为默认值 |
| start_time | timestamp | 监视器 | 应用程序开始运行的时间(GMT) |
有关BPG中关键组件的更多详细信息,请参阅关键组件。
REST端点
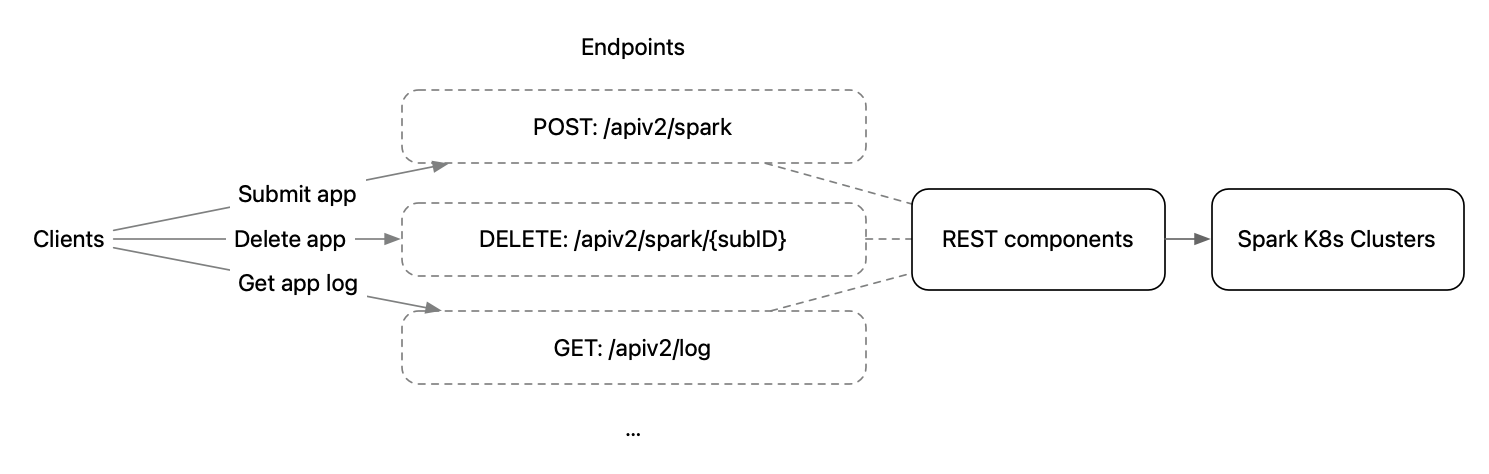
BPG为最终用户/客户端提供Spark应用程序的REST端点,例如POST /apiv2/spark用于提交Spark应用程序。
REST组件接收用户请求,在必要时操作请求,并通过fabric8 Kubernetes客户端与Spark集群交互。
身份验证
BPG没有内置的身份验证。它确实有一个简单的基于配置的用户列表授权器。
如果您需要身份验证或更复杂的授权,可以考虑构建一个与BPG容器并行运行的边车容器,并在成功验证后将用户名传递给它。 这可以使身份验证逻辑解耦,以提高可维护性。
BPG支持两种传入用户的方式:
- 基本身份验证:常见的头部
Authorization: Basic <base64-encoded string username:password> - 头部
USER_HEADER_KEY:当身份验证由其他进程完成时,这提供了更大的灵活性
Spark集群路由
BPG本质上接收请求,并将它们作为CRD路由到Spark K8s集群。 为了根据业务需求利用Spark集群,它提供了基于队列和权重将请求路由到特定命名空间的灵活性。
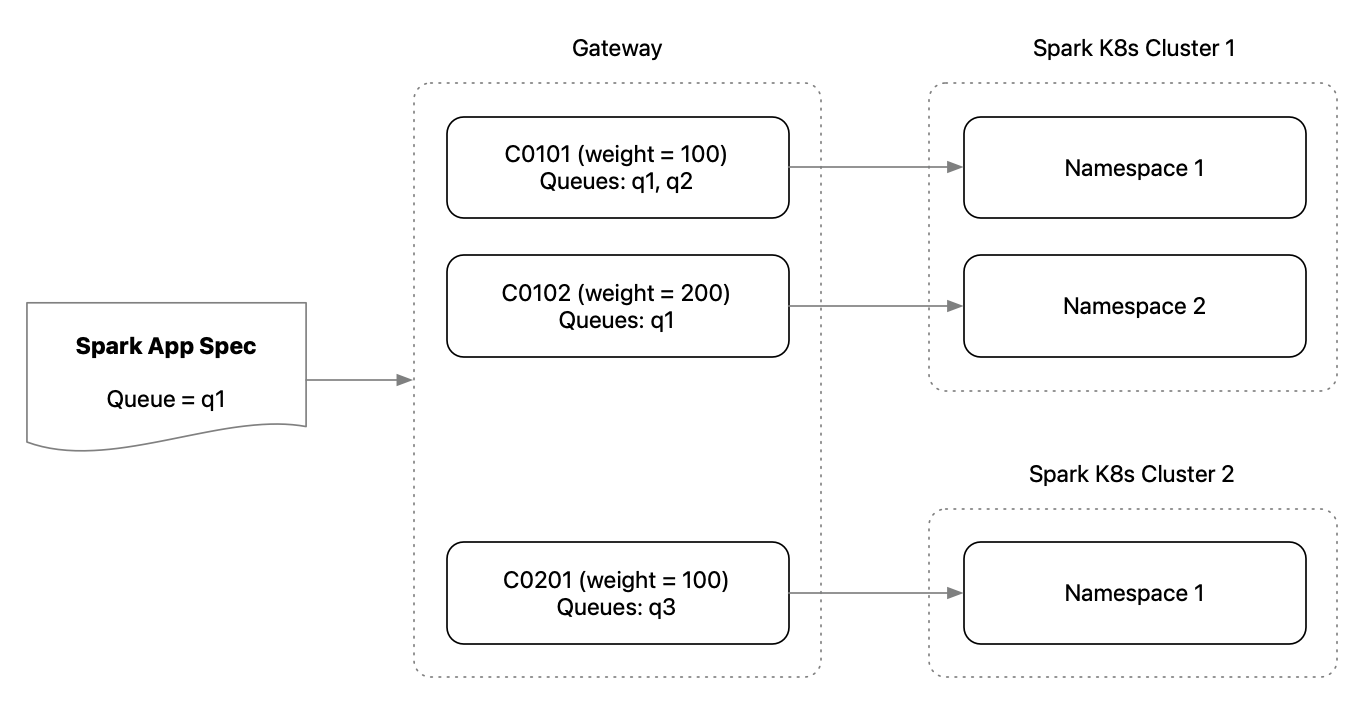
基于命名空间的集群配置
BPG中配置的每个Spark集群都映射到实际Spark K8s集群中的一个命名空间。 换句话说,您可以配置多个Spark集群条目,每个条目映射到单个Spark K8s集群中的一个命名空间。 Spark作业将作为CRD提交到特定的命名空间。 这为资源分配提供了更大的灵活性。
队列配置
每个配置的Spark集群都有一个队列列表,Spark应用程序可以提交到这些队列中。 当没有指定队列时,BPG默认会尝试提交到"poc"队列。
当有多个Spark集群支持一个队列时,它会根据权重计算选择一个集群。
基于权重的集群选择
假设当一个Spark应用程序提交到队列"q1"时,集群"c01"、"c02"和"c03"都支持"q1"。 集群的选择取决于集群权重和一些随机性:
c01被选中的概率 =
weight(c01) / (c01.weight + c02.weight + c03.weight)
因此,如果你希望某个集群在同一队列中被更频繁地选择,只需增加该集群的权重即可。
应用程序日志
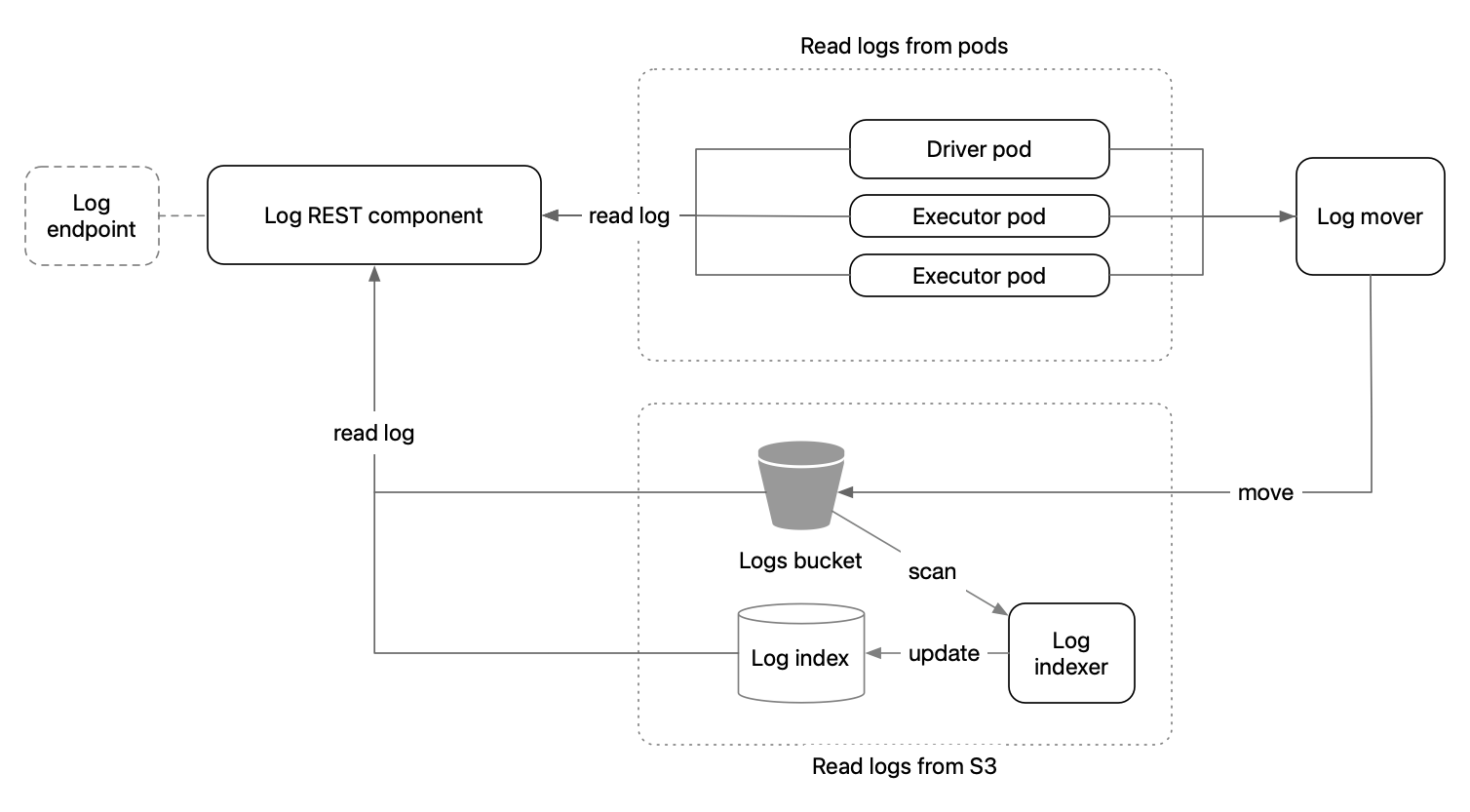
当Spark应用程序在Spark K8s集群上运行时,驱动程序和执行器的应用程序日志会写入到pod的本地存储中。 然而,当应用程序完成后pod消失时,日志也会随之消失。 保存日志的一般方法是将它们移动到S3存储桶中。
当用户通过日志端点请求驱动程序/执行器日志时,BPG首先会尝试从驱动程序/执行器pod加载日志。 如果pod已经消失或日志不可用,它会从预先配置的S3存储桶中读取。
为了使S3日志存储正常工作,需要满足两个条件:
- 一个"日志移动器",持续将Spark应用程序日志从pod移动到S3
- 数据库中的"日志索引"和一个"索引器"进程,用于跟踪日志文件的S3前缀
目前,"日志移动器"和"索引器"不在项目范围内。 服务维护人员需要启动自己的进程来使用S3日志功能。 对于"日志移动器",一种解决方案是采用fluentbit。
logindex模式(部分)
| 字段 | 类型 | 说明 |
|---|---|---|
| logs3key | varchar(500) | S3上日志文件的完整路径 |
| date | date | 作业创建的日期 |
| hour | char(2) | 作业创建的小时 |
| containerId | varchar(60) | 格式为<提交ID>-<驱动程序/执行器索引> |
贡献
有关如何贡献的详细信息,请参阅CONTRIBUTING。要开始开发,请参考入门指南。
部署
在生产环境中,通常Spark应用程序会在不同的Spark K8s集群上运行,因为Spark应用程序可能需要大量资源。 BPG在Kubernetes上的部署可以通过Helm chart管理。
Spark集群故障排除
有时如果Batch Processing Gateway连接到底层Spark集群出现问题,你可以使用这个工具SparkClusterTest
来再次检查是否可以连接到Spark集群中的Kubernetes API服务器。例如:
java -cp target/bpg-release.jar com.apple.spark.tools.SparkClusterTest -api-server https://xxx -namespace spark-operator -user spark-operator-api-user -token xxx
构建工具
Batch Processing Gateway使用了以下工具(不限于):
- Dropwizard - 用于REST API的Web框架
- Maven - 依赖管理
- fabric8 K8s Client - Kubernetes客户端
- Micrometer - 指标注册表
- Swagger - OpenAPI和Swagger UI支持
- AWS SDK for Java - S3上传支持
公开演讲
在会议上解释Batch Processing Gateway在云原生数据平台中的角色和最佳实践的公开演讲:
- KubeCon北美2022 - 超越实验:Kubernetes上的Spark
- KubeCon欧洲2022 - Kubernetes上的Spark - Elastic的故事
许可证
更多信息请参阅LICENSE。











