
 访问官网
访问官网 Github
Github 论文
论文
CaskDB - 基于磁盘的日志结构哈希表存储





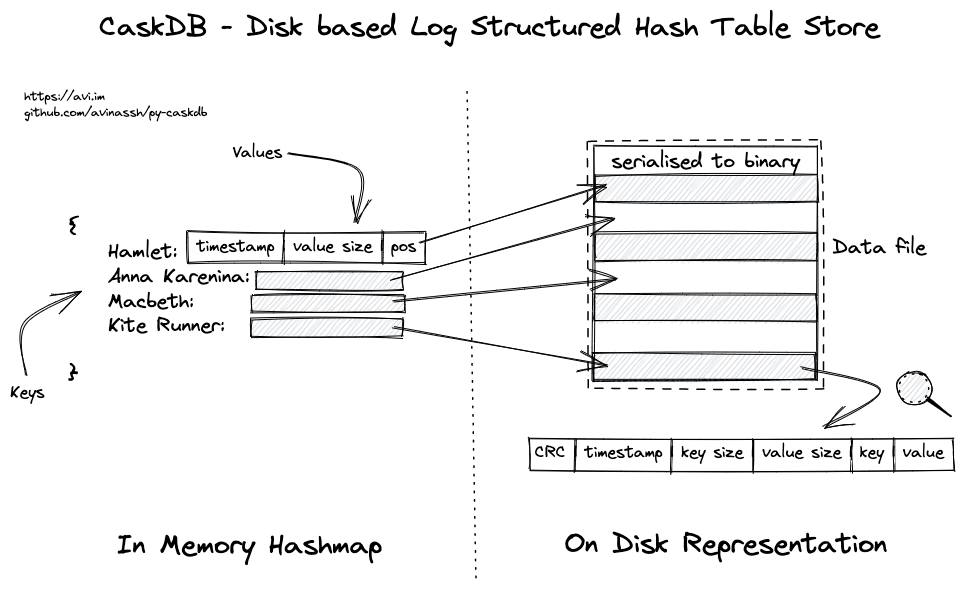
CaskDB是一个基于Riak的bitcask论文的磁盘式、嵌入式、持久化的键值存储,使用Python编写。它更注重教育功能而非生产环境使用。文件格式与平台、机器和编程语言无关。例如,在macOS上用Python创建的数据库文件应该与Windows上的Rust兼容。
本项目旨在帮助任何人,即使是数据库初学者,也能在几小时内构建一个持久化数据库。没有外部依赖,只需使用Python标准库即可。
如果你有兴趣自己编写数据库,请前往workshop部分。
特性
- 读写延迟低
- 高吞吐量
- 易于备份/恢复
- 简单易懂
- 可存储超过RAM容量的数据
局限性
以下大多数局限性属于CaskDB。然而,有些是由Bitcask论文的设计约束导致的。
- 单个文件存储所有数据,已删除的键仍占用空间
- CaskDB不提供范围扫描
- CaskDB需要将所有键保存在内部内存中。当键数量很多时,RAM使用量会很高
- 启动时间较慢,因为需要将所有键加载到内存中
社区

考虑加入Discord社区,与同行一起构建和学习KV存储。
依赖
CaskDB不需要任何外部库即可运行。对于本地开发,请从requirements_dev.txt安装软件包:
pip install -r requirements_dev.txt
安装
CaskDB尚未使用PyPi(问题#5),你需要通过克隆直接从仓库安装。
使用方法
disk: DiskStorage = DiskStorage(file_name="books.db")
disk.set(key="othello", value="shakespeare")
author: str = disk.get("othello")
# 还支持字典风格的API:
disk["hamlet"] = "shakespeare"
先决条件
本workshop面向中级至高级程序员。了解Python不是必需的,你可以使用任何你喜欢的语言构建数据库。
不确定你的水平?如果你在任何语言中完成了以下操作,那么你就已经准备好了:
- 使用过字典或哈希表数据结构
- 将对象(类、结构体或字典)转换为JSON,并将JSON转换回对象
- 打开文件以写入或读取任何内容。常见任务是将字典内容转储到磁盘并重新读取
Workshop
**注意:**我近期没有安排workshop。请在Twitter上关注我以获取更新。如果你希望为你的团队/公司安排workshop,请给我发邮件。
CaskDB配备了完整的测试套件和各种工具,帮助你快速编写数据库。Github action提供了自动化测试运行器、代码格式化工具、代码检查器、类型检查器和静态分析器。fork仓库,推送代码,并通过测试!
在整个workshop中,你将实现以下内容:
- 序列化方法:将一系列对象序列化为字节。同时,将一系列字节反序列化回对象。
- 设计一种包含头部和数据的数据格式,用于将字节存储在磁盘上。头部将包含元数据,如时间戳、键大小和值。
- 在磁盘上存储和检索数据
- 读取现有的CaskDB文件以加载所有键
任务
- 阅读论文。fork此仓库并检出
start-here分支 - 实现固定大小的头部,可以同时编码时间戳(无符号整数,4字节)、键大小(无符号整数,4字节)、值大小(无符号整数,4字节)
- 实现键、值序列化器,并通过
test_format.py中的测试 - 找出如何在磁盘上存储数据以及在内存中存储行指针。实现get/set操作。相关测试在
test_disk_store.py中 - 任务#2和#3中的代码应该足以读取现有的CaskDB文件并将键加载到内存中
使用make lint运行mypy、black和pytype静态分析器。运行make test在本地运行测试。将代码推送到Github,测试将在不同的操作系统上运行:ubuntu、mac和windows。
不确定如何继续?查看hints文件,其中包含更多关于任务的详细信息和提示。
提示
- 查看Python中struct.pack的文档,了解序列化方法
- 不确定如何设计文件格式?阅读format模块中的注释
下一步?
我经常收到关于基本实现之后该做什么的问题。以下是一些挑战(难度不同)
第1级:
- 崩溃安全:bitcask论文在行中存储CRC,在获取行时验证数据
- 键删除:CaskDB没有删除API。阅读论文并实现它
- 不使用哈希表,而是使用红黑树等数据结构来支持范围扫描
- CaskDB只接受字符串作为键和值。使其通用,接受其他数据结构,如整数或字节
- 当前实现在启动时将值加载到内存中。这是不必要的,可以避免。只需跳过值字节,只读取键就足以构建KeyDir
第2级:
- 提示文件以改善启动时间。论文中有更多详细信息
- 实现内部缓存,存储一些键值对。你可以探索和尝试不同的缓存淘汰策略,如LRU、LFU、FIFO等
- 当文件达到特定容量时,将数据拆分为多个文件
第3级:
- 支持多进程
- 垃圾收集器:更新和删除的键仍然存在于文件中并占用空间。编写垃圾收集器以删除这些过时数据
- 添加SQL查询引擎层
- 在值中存储JSON,探索将CaskDB作为文档数据库(如MongoDB)
- 通过探索raft、paxos或一致性哈希等算法,使CaskDB分布式化
名称
这个项目最初命名为cdb,现在改名为CaskDB。
代码行数
$ tokei -f format.py disk_store.py
===============================================================================
语言 文件数 行数 代码 注释 空行
===============================================================================
Python 2 391 261 103 27
-------------------------------------------------------------------------------
disk_store.py 204 120 70 14
format.py 187 141 33 13
===============================================================================
总计 2 391 261 103 27
===============================================================================
贡献
欢迎所有贡献。请查看CONTRIBUTING.md了解更多详情。
许可证
MIT许可证。请查看LICENSE文件了解更多详情。











