
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
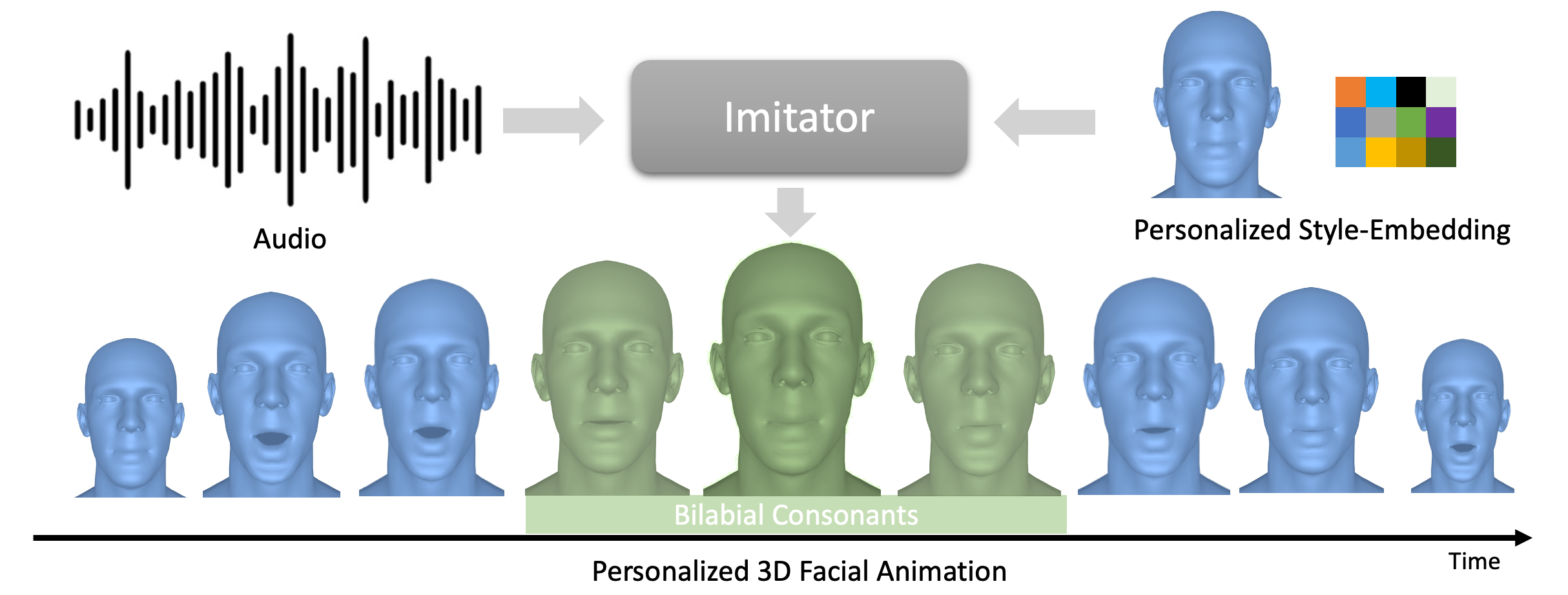
论文Imitator: 个性化语音驱动的3D面部动画
ICCV 2023

Imitator
Balamurugan Thambiraja,
Ikhsanul Habibie,
Sadegh Aliakbarian,
Darren Cosker,
Christian Theobalt,
Justus Thies
新闻
- 被ICCV 2023接收
- 2023年9月27日: 代码上传完成
- 2023年10月16日: 代码问题修复并增加对Windows的支持,感谢sihangchen97
待办事项
- 发布3个个性化模型[Boris, Kamala Harris, Trevor Noah]用于外部演员的风格适应比较。 (如果您因即将到来的CVPR 2024截稿日期而急需,请给我发邮件)
安装
Linux:
git clone https://github.com/bala1144/Imitator.git
cd Imitator
bash install.sh
Windows:
git clone https://github.com/bala1144/Imitator.git
cd Imitator
install.bat
Mac:
按照Linux命令操作并使用dowload_asset.sh。确保安装了wget,只需将install.sh的第7行改为您机器上运行的Python版本。
下载资源(预训练模型、蒙版等)
Linux和Mac:
bash download_asset.sh
Windows:
download_asset.bat
我们将更新3个预训练模型
- generalized_model_mbp (VOCAset上的通用模型)
- subj0024_stg02_04seq (FaceTalk_170731_00024_TA个性化模型)
- subj0138_stg02_04seq (FaceTalk_170731_00024_TA个性化模型)
数据准备
VOCA
下载VOCA并使用Faceformer的脚本进行准备
git clone https://github.com/EvelynFan/FaceFormer.git
cd FaceFormer/vocaset
python process_voca_data.py
cd ../..
wav2vec模型(可选,用于离线使用)
从HuggingFace下载wav2vec模型,例如wav2vec2-base-960h。
覆盖配置文件(可选)
VOCA数据集和wav2vec模型的目录可能因人而异。
如果您发现很难找到或修改配置文件(*.yaml),请设置环境变量(VOCASET_PATH, WAV2VEC_PATH)以运行上述测试脚本。
Linux:
export VOCASET_PATH=<VOCA数据集文件夹路径>
export WAV2VEC_PATH=<wav2vec模型文件夹路径(例如wav2vec2-base-960h)>
Windows:
set VOCASET_PATH=<VOCA数据集文件夹路径>
set WAV2VEC_PATH=<wav2vec模型文件夹路径(例如wav2vec2-base-960h)>
测试
外部音频测试
要评估外部音频,您可以使用assets/demo/中的演示音频
python imitator/test/test_model_external_audio.py -m pretrained_model/generalized_model_mbp_vel --audio assets/demo/audio1.wav -t FaceTalk_170731_00024_TA -c 2 -r -d
-a音频文件路径-t指定VOCA的主题-c指定用于测试的VOCA条件[0,1...7]-r将结果渲染为视频-d将预测结果转储为npy文件
VOCA测试
要评估VOCA上的通用/个性化模型
python imitator/test/test_model_voca.py -m pretrained_model/generalized_model_mbp_vel -r -d
python imitator/test/test_model_voca.py -m pretrained_model/subj0024_stg02_04seq -r -d
python imitator/test/test_model_voca.py -m pretrained_model/subj0138_stg02_04seq -r -d
-c指定数据集的配置;编辑imitator/test/data_cfg.yml以指向您的数据集路径。
训练模型
通用模型
在VOCA上训练通用模型
python main.py -b cfg/generalized_model/imitator_gen_ab_mbp_vel10.yaml --gpus 0,
个性化模型
个性化的第一阶段,我们使用通用模型优化风格代码
python main.py -b cfg/style_adaption/subj0024_stg01_04seq.yaml --gpus 0,
个性化的第二阶段,我们使用第一阶段的模型优化风格代码和位移
python main.py -b cfg/style_adaption/subj0024_stg02_04seq.yaml --gpus 0,
更多
致谢
感谢所有公开其代码和模型的人。特别是,
- 我们方法的架构受到Faceformer的启发
- 我们的代码库建立在Taming_Tranformers和Faceformer的基础上
- 相关工作Faceformer、codetalker、VOCA和Meshtalk
BibTeX
@InProceedings{Thambiraja_2023_ICCV,
author = {Thambiraja, Balamurugan and Habibie, Ikhsanul and Aliakbarian, Sadegh and Cosker, Darren and Theobalt, Christian and Thies, Justus},
title = {Imitator: Personalized Speech-driven 3D Facial Animation},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {20621-20631}
}











