
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文StarCoder2-Instruct:完全透明且许可的自对齐代码生成
⭐️ 关于 | 🚀 快速开始 | 📚 数据生成管道 | 🧑💻 训练细节 | 📊 评估 | ⚠️ 限制

关于
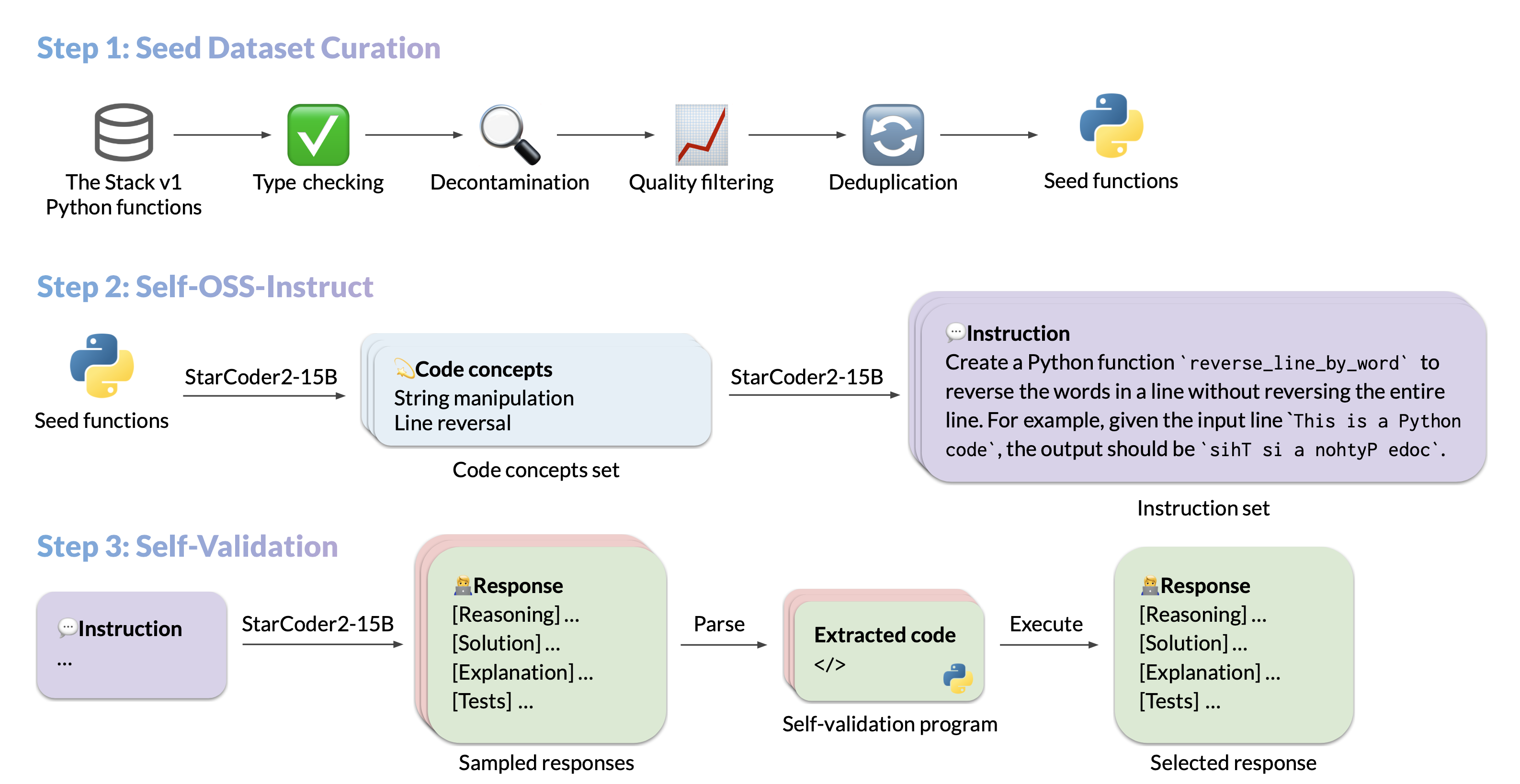
我们介绍了 StarCoder2-15B-Instruct-v0.1,这是第一个完全自对齐的代码大语言模型(LLM),通过完全许可和透明的管道进行训练。我们的开源管道使用 StarCoder2-15B 生成数千对指令-响应对,这些对用于微调 StarCoder-15B 本身,而不需要人类注释或来自巨大的专有 LLM 的提取数据。
- 模型: bigcode/starcoder2-15b-instruct-v0.1
- 代码: bigcode-project/starcoder2-self-align
- 数据集: bigcode/self-oss-instruct-sc2-exec-filter-50k
- 作者: Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Harm de Vries, Leandro von Werra, Arjun Guha, Lingming Zhang.
快速开始
以下是使用 transformers 库快速入门 StarCoder2-15B-Instruct-v0.1 的示例:
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
数据生成管道
运行
pip install -e .首先在本地安装这个包。查看 seed_gathering 了解我们如何收集种子数据的详细信息。
我们使用 vLLM 的 OpenAI 兼容服务器 进行数据生成。因此,在运行以下命令之前,请确保 vLLM 服务器正在运行,并设置相关的 openai 环境变量。
例如,您可以使用 docker 启动 vLLM 服务器:
docker run --gpus '"device=0"' \
-v $HF_HOME:/root/.cache/huggingface \
-p 10000:8000 \
--ipc=host \
vllm/vllm-openai:v0.3.3 \
--model bigcode/starcoder2-15b \
--tensor-parallel-size 1 --dtype bfloat16
然后设置环境变量如下:
export OPENAI_API_KEY="EMPTY"
export OPENAI_BASE_URL="http://localhost:10000/v1/"
从片段到概念生成
python src/star_align/self_ossinstruct.py \
--instruct_mode "S->C" \
--seed_data_files /path/to/seeds.jsonl \
--max_new_data 50000 \
--tag concept_gen \
--temperature 0.7 \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 8 \
--num_batched_requests 32 \
--num_sample_per_request 1
从概念到指令生成
python src/star_align/self_ossinstruct.py \
--instruct_mode "C->I" \
--seed_data_files /path/to/concepts.jsonl \
--max_new_data 50000 \
--tag instruction_gen \
--temperature 0.7 \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 8 \
--num_sample_per_request 1 \
--num_batched_request 32
从指令到响应(带自验证代码)生成
python src/star_align/self_ossinstruct.py \
--instruct_mode "I->R" \
--seed_data_files path/to/instructions.jsonl \
--max_new_data 50000 \
--tag response_gen \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 1 \
--num_batched_request 8 \
--num_sample_per_request 10 \
--temperature 0.7
执行筛选
警告: 尽管我们实现了可靠性保护,还是强烈建议在沙箱环境中运行执行。以下命令默认不提供沙箱功能。
python src/star_align/execution_filter.py --response_path /path/to/response.jsonl --result_path /path/to/filtered.jsonl
# 当前实现可能导致死锁。
# 如果遇到死锁,手动执行 `ps -ef | grep execution_filter` 然后杀死卡住的进程。
# 请注意,filtered.jsonl 可能包含多个相同指令的通过样本,需要进一步选择。
要使用 Docker 容器执行代码,您首先需要 git submodule update --init --recursive 克隆服务器,然后运行:
pushd ./src/star_align/code_exec_server
./build_and_run.sh
popd
python src/star_align/execution_filter.py --response_path /path/to/response.jsonl --result_path /path/to/filtered.jsonl --container_server http://127.0.0.1:8000
数据清理和选择
RAW=1 python src/star_align/sanitize_data.py /path/to/filtered.jsonl /path/to/sanitized.jsonl
python src/star_align/clean_data.py --data_files /path/to/sanitized.jsonl --output_file /path/to/sanitized.jsonl --diversify_func_names
SMART=1 python src/star_align/sanitize_data.py /path/to/sanitized.jsonl /path/to/sanitized.jsonl
训练细节
运行
pip install -e .首先安装这个包。并安装 Flash Attention 以加速训练。
超参数
- 优化器: Adafactor
- 学习率: 1e-5
- 周期: 4
- 批次大小: 64
- 预热比: 0.05
- 调度器: 线性
- 序列长度: 1280
- 丢弃率:未应用
硬件
1 x NVIDIA A100 80GB。是的,只需要一个 A100 就能微调 StarCoder2-15B!
脚本
以下脚本从基础 StarCoder2-15B 模型微调 StarCoder2-15B-Instruct-v0.1。/path/to/dataset.jsonl 是我们生成的 50k 数据集 的 JSONL 格式。您可以将数据集转储为 JSONL 以适合训练脚本。
点击查看训练脚本
注意:StarCoder2-15B 默认设置丢弃率值为 0.1。我们在微调中没有应用丢弃,因此设置为 0.0。
MODEL_KEY=bigcode/starcoder2-15b
LR=1e-5
EPOCH=4
SEQ_LEN=1280
WARMUP_RATIO=0.05
OUTPUT_DIR=/path/to/output_model
DATASET_FILE=/path/to/50k-dataset.jsonl
accelerate launch -m star_align.train \
--model_key $MODEL_KEY \
--model_name_or_path $MODEL_KEY \
--use_flash_attention True \
--datafile_paths $DATASET_FILE \
--output_dir $OUTPUT_DIR \
--bf16 True \
--num_train_epochs $EPOCH \
--max_training_seq_length $SEQ_LEN \
--pad_to_max_length False \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 64 \
--group_by_length False \
--ddp_find_unused_parameters False \
--logging_steps 1 \
--log_level info \
--optim adafactor \
--max_grad_norm -1 \
--warmup_ratio $WARMUP_RATIO \
--learning_rate $LR \
--lr_scheduler_type linear \
--attention_dropout 0.0 \
--residual_dropout 0.0 \
--embedding_dropout 0.0
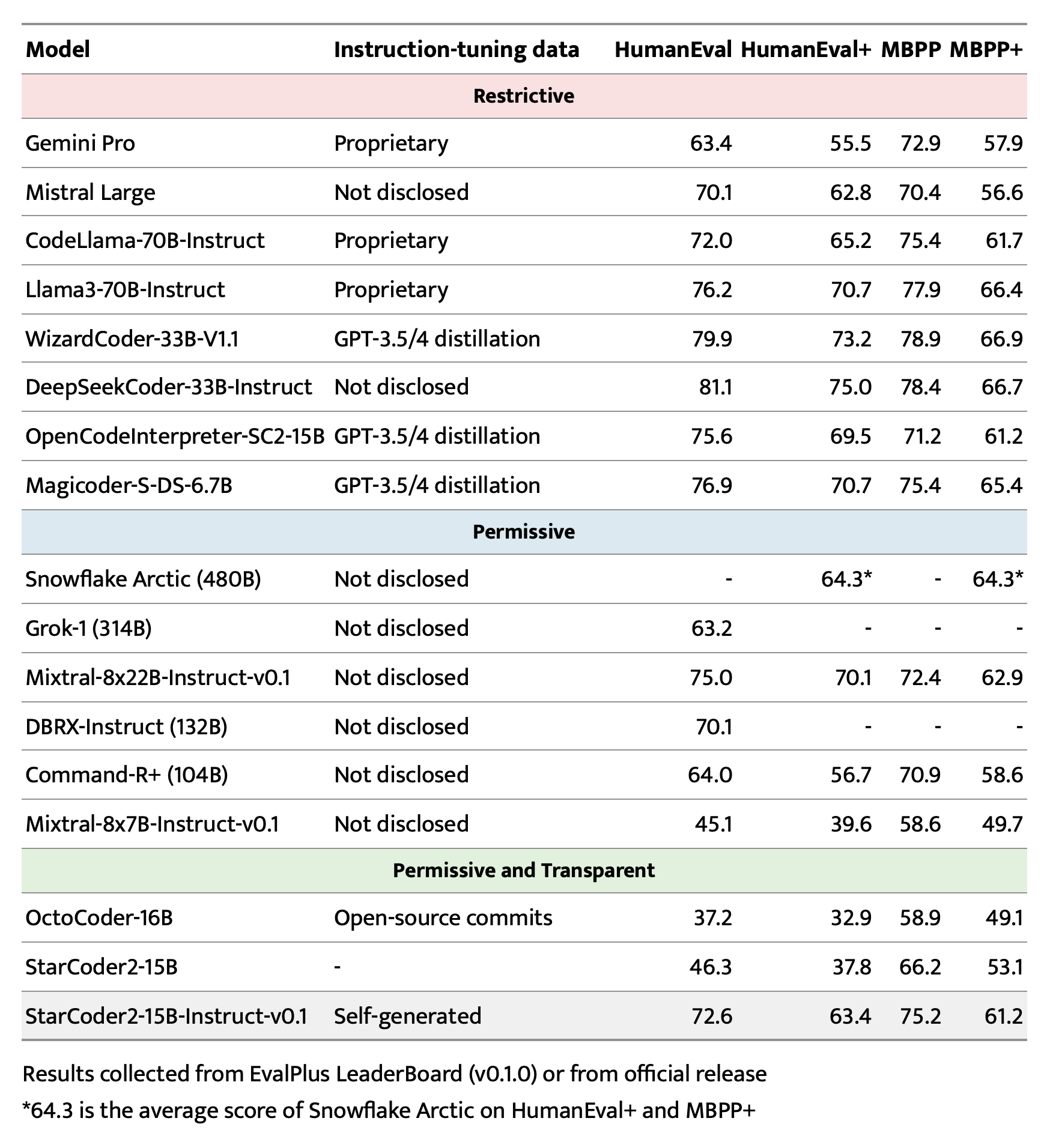
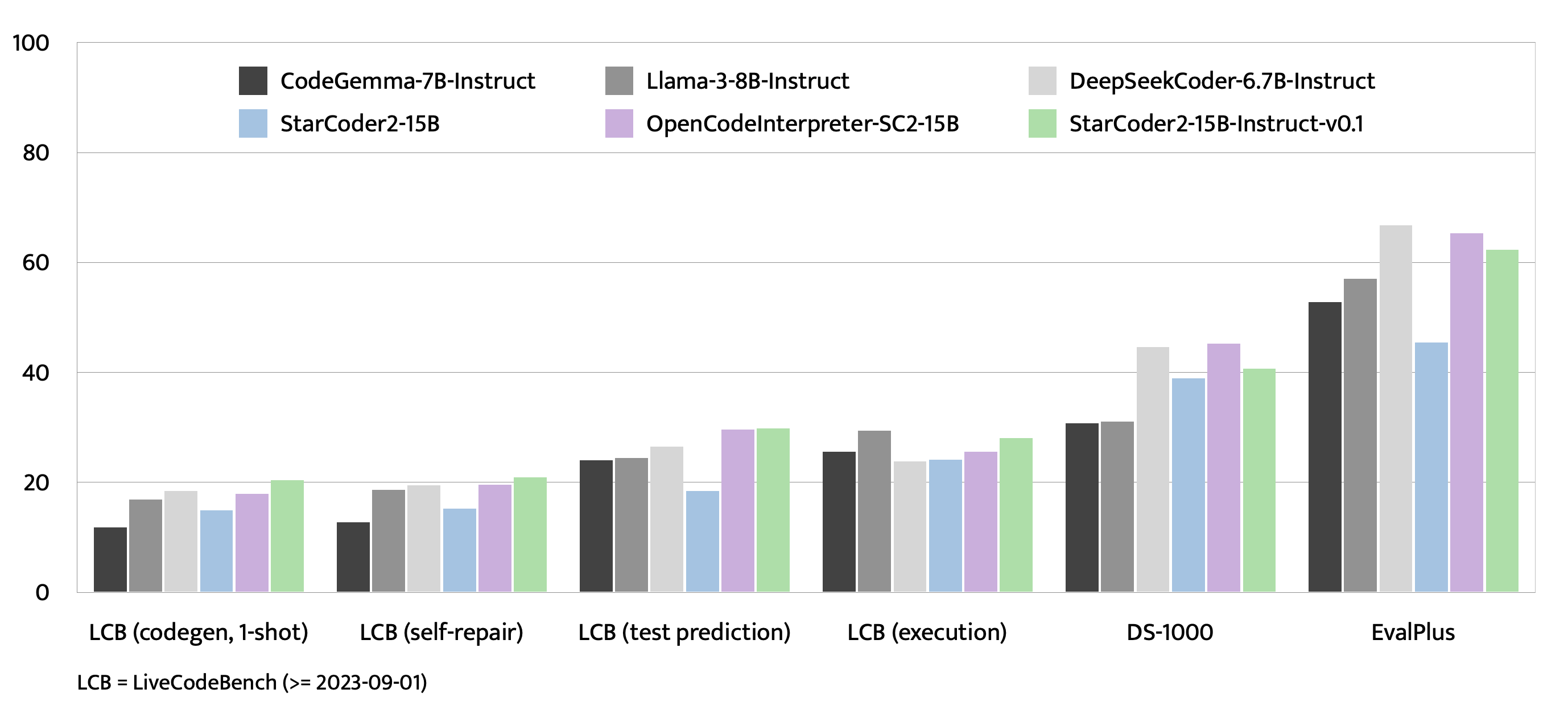
EvalPlus、LiveCodeBench 和 DS-1000 上的评估
查看 评估 了解更多细节。
偏见、风险和限制
StarCoder2-15B-Instruct-v0.1 主要针对 Python 代码生成任务进行了微调,这些任务可以通过执行来验证,这可能导致某些偏见和限制。例如,模型可能不会严格遵守指令中规定的输出格式。在这些情况下,提供一个 响应前缀 或 一次示例 可以帮助引导模型的输出。此外,模型在其他编程语言和域外代码任务上可能存在局限性。
该模型还继承了其基础模型 StarCoder2-15B 的偏见、风险和限制。了解更多信息,请参阅 StarCoder2-15B 模型卡。











