
 访问官网
访问官网 Github
Github 文档
文档HarvestText
HarvestText : A Toolkit for Text Mining and Preprocessing

![]()

![]()
![]()
在Github和码云Gitee上同步。如果在Github上浏览/下载速度慢的话可以转到码云上操作。
用途
HarvestText是一个专注无(弱)监督方法,能够整合领域知识(如类型,别名)对特定领域文本进行简单高效地处理和分析的库。适用于许多文本预处理和初步探索性分析任务,在小说分析,网络文本,专业文献等领域都有潜在应用价值。
使用案例:
- 分析《三国演义》中的社交网络(实体分词,文本摘要,关系网络等)
- 2018中超舆情展示系统(实体分词,情感分析,新词发现[辅助绰号识别]等)
相关文章:一文看评论里的中超风云
【注:本库仅完成实体分词和情感分析,可视化使用matplotlib】
- 近代史纲要信息抽取及问答系统(命名实体识别,依存句法分析,简易问答系统)
本README包含各个功能的典型例子,部分函数的详细用法可在文档中找到:
具体功能如下:
-
基本处理
- 精细分词分句
- 可包含指定词和类别的分词。充分考虑省略号,双引号等特殊标点的分句。
- 文本清洗
- 处理URL, email, 微博等文本中的特殊符号和格式,去除所有标点等
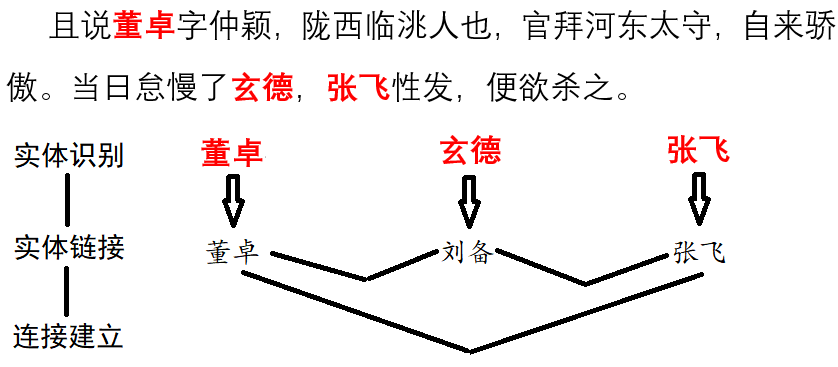
- 实体链接
- 把别名,缩写与他们的标准名联系起来。
- 命名实体识别
- 找到一句句子中的人名,地名,机构名等命名实体。
- 实体别名自动识别(更新!)
- 依存句法分析
- 分析语句中各个词语(包括链接到的实体)的主谓宾语修饰等语法关系,
- 内置资源
- 通用停用词,通用情感词,IT、财经、饮食、法律等领域词典。可直接用于以上任务。
- 信息检索
- 统计特定实体出现的位置,次数等。
- 新词发现
- 利用统计规律(或规则)发现语料中可能会被传统分词遗漏的特殊词汇。也便于从文本中快速筛选出关键词。
- 字符拼音纠错(调整)
- 把语句中有可能是已知实体的错误拼写(误差一个字符或拼音)的词语链接到对应实体。
- 自动分段
- 使用TextTiling算法,对没有分段的文本自动分段,或者基于已有段落进一步组织/重新分段
- 存取消除
- 可以本地保存模型再读取复用,也可以消除当前模型的记录。
- 英语支持
- 本库主要旨在支持对中文的数据挖掘,但是加入了包括情感分析在内的少量英语支持
- 精细分词分句
-
高层应用
用法
首先安装, 使用pip
pip install --upgrade harvesttext
或进入setup.py所在目录,然后命令行:
python setup.py install
随后在代码中:
from harvesttext import HarvestText
ht = HarvestText()
即可调用本库的功能接口。
注意:部分功能需要安装额外的库,但有一定可能安装失败,故需要的话请手动安装
# 部分英语功能
pip install pattern
# 命名实体识别、句法分析等功能,需要python <= 3.8
pip install pyhanlp
实体链接
给定某些实体及其可能的代称,以及实体对应类型。将其登录到词典中,在分词时优先切分出来,并且以对应类型作为词性。也可以单独获得语料中的所有实体及其位置:
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
entity_mention_dict = {'武磊':['武磊','武球王'],'郜林':['郜林','郜飞机'],'前锋':['前锋'],'上海上港':['上港'],'广州恒大':['恒大'],'单刀球':['单刀']}
entity_type_dict = {'武磊':'球员','郜林':'球员','前锋':'位置','上海上港':'球队','广州恒大':'球队','单刀球':'术语'}
ht.add_entities(entity_mention_dict,entity_type_dict)
print("\nSentence segmentation")
print(ht.seg(para,return_sent=True)) # return_sent=False时,则返回词语列表
上港 的 武磊 和 恒大 的 郜林 , 谁 是 中国 最好 的 前锋 ? 那 当然 是 武磊 武球王 了, 他 是 射手榜 第一 , 原来 是 弱点 的 单刀 也 有 了 进步
采用传统的分词工具很容易把“武球王”拆分为“武 球王”
词性标注,包括指定的特殊类型。
print("\nPOS tagging with entity types")
for word, flag in ht.posseg(para):
print("%s:%s" % (word, flag),end = " ")
上港:球队 的:uj 武磊:球员 和:c 恒大:球队 的:uj 郜林:球员 ,:x 谁:r 是:v 中国:ns 最好:a 的:uj 前锋:位置 ?:x 那:r 当然:d 是:v 武磊:球员 武球王:球员 了:ul ,:x 他:r 是:v 射手榜:n 第一:m ,:x 原来:d 是:v 弱点:n 的:uj 单刀:术语 也:d 有:v 了:ul 进步:d
for span, entity in ht.entity_linking(para):
print(span, entity)
[0, 2] ('上海上港', '#球队#') [3, 5] ('武磊', '#球员#') [6, 8] ('广州恒大', '#球队#') [9, 11] ('郜林', '#球员#') [19, 21] ('前锋', '#位置#') [26, 28] ('武磊', '#球员#') [28, 31] ('武磊', '#球员#') [47, 49] ('单刀球', '#术语#')
这里把“武球王”转化为了标准指称“武磊”,可以便于标准统一的统计工作。
分句:
print(ht.cut_sentences(para))
['上港的武磊和恒大的郜林,谁是中国最好的前锋?', '那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步']
如果手头暂时没有可用的词典,不妨看看本库内置资源中的领域词典是否适合你的需要。
如果同一个名字有多个可能对应的实体("打球的李娜和唱歌的李娜不是一个人"),可以设置keep_all=True来保留多个候选,后面可以再采用别的策略消歧,见el_keep_all()
如果连接到的实体过多,其中有一些明显不合理,可以采用一些策略来过滤,这里给出了一个例子filter_el_with_rule()
本库能够也用一些基本策略来处理复杂的实体消歧任务(比如一词多义【"老师"是指"A老师"还是"B老师"?】、候选词重叠【xx市长/江yy?、xx市长/江yy?】)。 具体可见linking_strategy()
文本清洗
可以处理文本中的特殊字符,或者去掉文本中不希望出现的一些特殊格式。
包括:微博的@,表情符;网址;email;html代码中的 一类的特殊字符;网址内的%20一类的特殊字符;繁体字转简体字
例子如下:
print("各种清洗文本")
ht0 = HarvestText()
# 默认的设置可用于清洗微博文本
text1 = "回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]"
print("清洗微博【@和表情符等】")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1))
各种清洗文本
清洗微博【@和表情符等】
原: 回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]
清洗后: 杨大哥
# URL的清理
text1 = "【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ"
print("清洗网址URL")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, remove_url=True))
清洗网址URL
原: 【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ
清洗后: 【#赵薇#:正筹备下一部电影 但不是青春片....
# 清洗邮箱
text1 = "我的邮箱是abc@demo.com,欢迎联系"
print("清洗邮箱")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, email=True))
清洗邮箱
原: 我的邮箱是abc@demo.com,欢迎联系
清洗后: 我的邮箱是,欢迎联系
# 处理URL转义字符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print("URL转正常字符")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, norm_url=True,











