
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文SMPLer-X:扩展表现力丰富的人体姿态和形状估计
有用链接
新闻
- [2024-03-29] 发布了SMPLer-X-H32的更新版本,修复了在3DPW类似数据上的相机估计问题。
- [2024-02-29] HuggingFace演示上线!
- [2023-10-23] 支持通过SMPL-X网格叠加进行可视化,并添加推理Docker。
- [2023-10-02] arXiv预印本上线!
- [2023-09-28] 主页和视频上线!
- [2023-07-19] 预训练模型发布。
- [2023-06-15] 训练和测试代码发布。
展示
 |  |  |
|---|---|---|
 |  |  |

安装
conda create -n smplerx python=3.8 -y
conda activate smplerx
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch -y
pip install mmcv-full==1.7.1 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.12.0/index.html
pip install -r requirements.txt
# 安装mmpose
cd main/transformer_utils
pip install -v -e .
cd ../..
Docker支持(初期阶段)
docker pull wcwcw/smplerx_inference:v0.2
docker run --gpus all -v <视频输入文件夹>:/smplerx_inference/vid_input \
-v <视频输出文件夹>:/smplerx_inference/vid_output \
wcwcw/smplerx_inference:v0.2 --vid <视频名称>.mp4
# 目前任何自定义需要应用到 /smplerx_inference/smplerx/inference_docker.py
- 我们最近在Docker Hub上开发了一个用于推理的Docker镜像。
- 这个Docker镜像使用SMPLer-X-H32作为推理基线,并在RTX3090和WSL2(Ubuntu 20.04)上进行了测试。
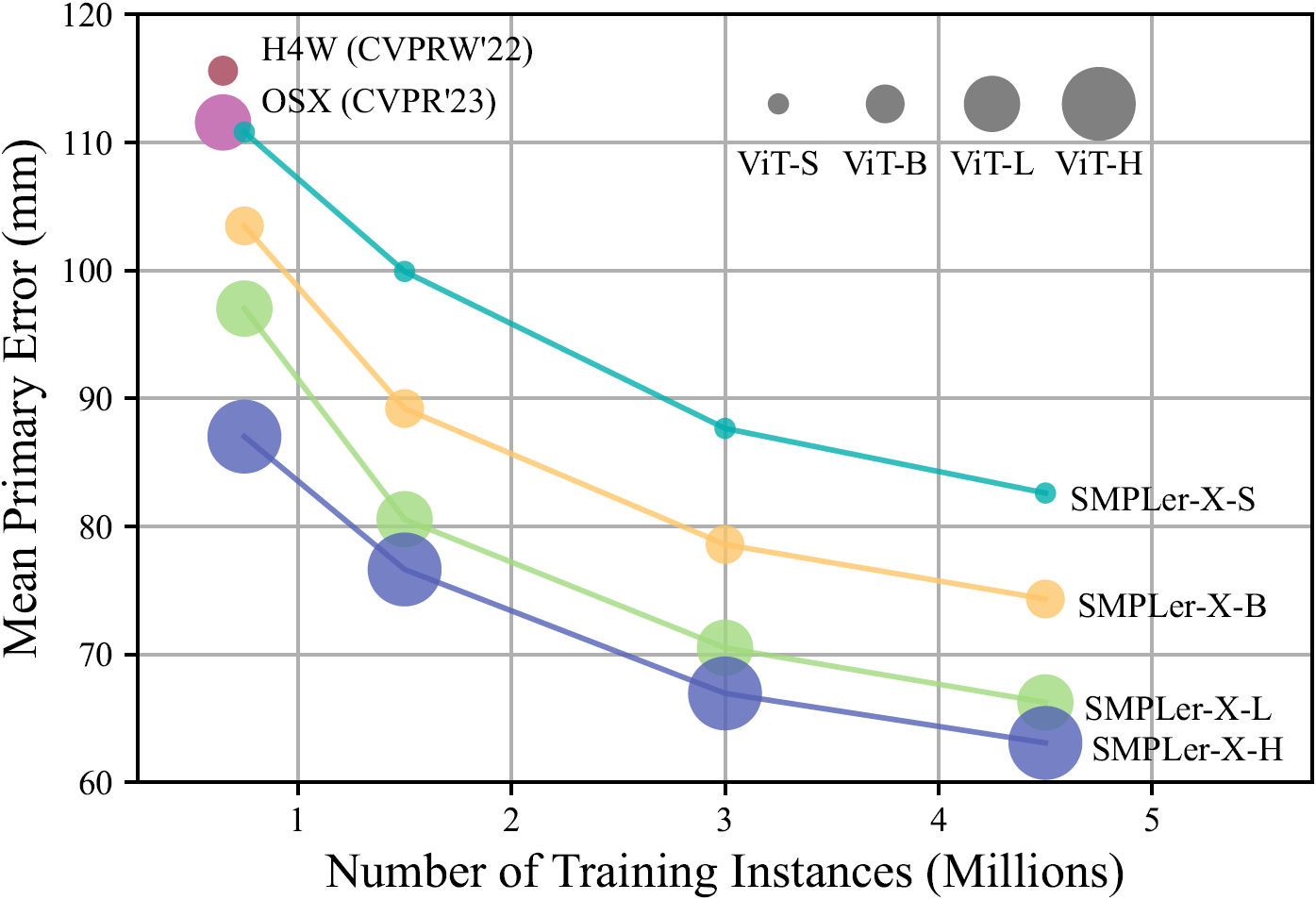
预训练模型
| 模型 | 骨干网络 | 数据集数量 | 实例数 | 参数量 | MPE | 下载链接 | 帧率 |
|---|---|---|---|---|---|---|---|
| SMPLer-X-S32 | ViT-S | 32 | 450万 | 3200万 | 82.6 | 模型 | 36.17 |
| SMPLer-X-B32 | ViT-B | 32 | 450万 | 1.03亿 | 74.3 | 模型 | 33.09 |
| SMPLer-X-L32 | ViT-L | 32 | 450万 | 3.27亿 | 66.2 | 模型 | 24.44 |
| SMPLer-X-H32 | ViT-H | 32 | 450万 | 6.62亿 | 63.0 | 模型 | 17.47 |
| SMPLer-X-H32* | ViT-H | 32 | 450万 | 6.62亿 | 59.7 | 模型 | 17.47 |
- MPE(平均主要误差):五个基准数据集(AGORA、EgoBody、UBody、3DPW和EHF)上主要误差的平均值
- FPS(每秒帧数):在单个Tesla V100 GPU上的平均推理速度,批量大小为1
- SMPLer-X-H32*是SMPLer-X-H32的更新版本,修复了3DPW类数据上的相机估计问题。
准备工作
- 下载所有数据集
- 将所有数据集处理成HumanData格式,除了以下几个:
- AGORA、MSCOCO、MPII、Human3.6M、UBody。
- 这5个数据集的准备请按照OSX的方法进行。
- 按照OSX的方法准备预训练的ViTPose模型。从这里下载ViT-small和ViT-huge的ViTPose预训练权重。
- 下载SMPL-X和SMPL人体模型。
- 下载mmdet预训练的模型和配置文件用于推理。 文件结构应如下所示:
SMPLer-X/
├── common/
│ └── utils/
│ └── human_model_files/ # 人体模型
│ ├── smpl/
│ │ ├──SMPL_NEUTRAL.pkl
│ │ ├──SMPL_MALE.pkl
│ │ └──SMPL_FEMALE.pkl
│ └── smplx/
│ ├──MANO_SMPLX_vertex_ids.pkl
│ ├──SMPL-X__FLAME_vertex_ids.npy
│ ├──SMPLX_NEUTRAL.pkl
│ ├──SMPLX_to_J14.pkl
│ ├──SMPLX_NEUTRAL.npz
│ ├──SMPLX_MALE.npz
│ └──SMPLX_FEMALE.npz
├── data/
├── main/
├── demo/
│ ├── videos/
│ ├── images/
│ └── results/
├── pretrained_models/ # 预训练的ViT-Pose、SMPLer_X和mmdet模型
│ ├── mmdet/
│ │ ├──faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
│ │ └──mmdet_faster_rcnn_r50_fpn_coco.py
│ ├── smpler_x_s32.pth.tar
│ ├── smpler_x_b32.pth.tar
│ ├── smpler_x_l32.pth.tar
│ ├── smpler_x_h32.pth.tar
│ ├── vitpose_small.pth
│ ├── vitpose_base.pth
│ ├── vitpose_large.pth
│ └── vitpose_huge.pth
└── dataset/
├── AGORA/
├── ARCTIC/
├── BEDLAM/
├── Behave/
├── CHI3D/
├── CrowdPose/
├── EgoBody/
├── EHF/
├── FIT3D/
├── GTA_Human2/
├── Human36M/
├── HumanSC3D/
├── InstaVariety/
├── LSPET/
├── MPII/
├── MPI_INF_3DHP/
├── MSCOCO/
├── MTP/
├── MuCo/
├── OCHuman/
├── PoseTrack/
├── PROX/
├── PW3D/
├── RenBody/
├── RICH/
├── SPEC/
├── SSP3D/
├── SynBody/
├── Talkshow/
├── UBody/
├── UP3D/
└── preprocessed_datasets/ # HumanData文件
推理
- 将需要推理的视频放在
SMPLer-X/demo/videos下 - 准备用于推理的预训练模型,放在
SMPLer-X/pretrained_models下 - 准备mmdet预训练模型和配置文件,放在
SMPLer-X/pretrained_models下 - 推理输出将保存在
SMPLer-X/demo/results中
cd main
sh slurm_inference.sh {视频文件} {格式} {帧率} {预训练检查点}
# 使用smpler_x_h32对test_video.mp4(24FPS)进行推理
sh slurm_inference.sh test_video mp4 24 smpler_x_h32
2D Smplx 叠加
我们提供了一个基于pyrender的轻量级网格叠加可视化脚本。
- 使用ffmpeg将视频分割成图像
- 可视化脚本以推理结果(见上文)作为输入。
ffmpeg -i {视频文件} -f image2 -vf fps=30 \
{SMPLERX推理目录}/{视频名(不含扩展名)}/orig_img/%06d.jpg \
-hide_banner -loglevel error
cd main && python render.py \
--data_path {SMPLERX推理目录} --seq {视频名} \
--image_path {SMPLERX推理目录}/{视频名} \
--render_biggest_person False
训练
cd main
sh slurm_train.sh {任务名} {GPU数量} {配置文件}
# 使用16个GPU训练SMPLer-X-H32
sh slurm_train.sh smpler_x_h32 16 config_smpler_x_h32.py
- 配置文件是
SMPLer-X/main/config下的文件名 - 日志和检查点将保存到
SMPLer-X/output/train_{任务名}_{日期_时间}
测试
# 评估模型 ../output/{训练输出目录}/model_dump/snapshot_{检查点ID}.pth.tar
# 使用配置文件 ../output/{训练输出目录}/code/config_base.py
cd main
sh slurm_test.sh {任务名} {GPU数量} {训练输出目录} {检查点ID}
- 建议测试时使用1个GPU
- 日志和结果将保存到
SMPLer-X/output/test_{任务名}_ep{检查点ID}_{测试数据集}
常见问题
-
RuntimeError: Subtraction, the '-' operator, with a bool tensor is not supported. If you are trying to invert a mask, use the '~' or 'logical_not()' operator instead.按照这个帖子的指示修改
torchgeometry -
KeyError: 'SinePositionalEncoding is already registered in position encoding'或任何其他由于重复模块注册导致的类似KeyError。在
main/transformer_utils/mmpose/models/utils下的相应模块注册中手动添加force=True,例如在这个文件中添加@POSITIONAL_ENCODING.register_module(force=True) -
我如何用SMPLer-X的输出来制作虚拟角色动画(像演示视频中那样)?
- 我们正在努力,请保持关注! 目前,此仓库支持SMPL-X估计和简单的可视化(SMPL-X顶点的叠加)。











