
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文MFTCoder:高精度高效率的多任务微调框架




目录
新闻
🔥🔥🔥 [2024/05/20] 我们发布了MFTCoder v0.4,主要针对MFTCoder加速。它支持QLoRA + DeepSpeed Zero3和QLoRA + FSDP作为选项,允许您训练非常大的模型。它现在支持新的模型,如Qwen2、Qwen2-MoE、Starcoder2、Gemma等。
🔥🔥🔥 [2024/05/20] 我们的论文MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning已被KDD2024接收。
🔥🔥🔥 [2024/05/20] CodeFuse-StarCoder2-15B已发布,在HumanEval上达到73.2%的pass@1(贪婪解码)分数。
🔥🔥 [2024/01/30] 使用MFTCoder微调的模型CodeFuse-DeepSeek-33B在HuggingFace Big Code Models LeaderBoard上排名第一。
🔥🔥 [2024/01/17] 我们发布了MFTCoder v0.3.0,主要针对MFTCoder加速。它现在支持新的模型,如Mixtral(MoE)、DeepSeek-coder、chatglm3。它支持FSDP作为一个选项。它还支持自适应步长损失作为多任务微调中收敛平衡的解决方案。
🔥🔥 [2024/01/17] CodeFuse-DeepSeek-33B已发布,在HumanEval上达到78.7%的pass@1(贪婪解码)分数。它在胜率方面列为Bigcode排行榜上的顶级LLM,官方结果将在稍后公布。
🔥🔥 [2024/01/17] CodeFuse-Mixtral-8x7B已发布,在HumanEval上达到56.1%的pass@1(贪婪解码)分数。
🔥🔥 [2023/11/07] MFTCoder论文已在Arxiv上发布,披露了多任务微调的技术细节。
🔥🔥 [2023/10/20] CodeFuse-QWen-14B已发布,在HumanEval上达到48.8%的pass@1(贪婪解码)分数,相比基础模型Qwen-14b绝对提升了16%。
🔥🔥 [2023/09/27] CodeFuse-StarCoder-15B已发布,在HumanEval上达到54.9%的pass@1(贪婪解码)分数。
🔥🔥 [2023/09/26] 我们很高兴宣布发布CodeFuse-CodeLlama-34B的4位量化版本。尽管经过量化处理,该模型在HumanEval pass@1指标上仍然达到了73.8%的显著准确率(贪婪解码)。
🔥🔥 [2023/09/07] 我们发布了CodeFuse-CodeLlama-34B,它在HumanEval基准测试上达到了74.4%的Python Pass@1(贪婪解码),超越了GPT4(2023/03/15)和ChatGPT-3.5。
🔥🔥 [2023/08/26] 我们发布了MFTCoder-v0.1.0,它支持使用LoRA/QLoRA对Code Llama、Llama、Llama2、StarCoder、ChatGLM2、CodeGeeX2、Qwen和GPT-NeoX模型进行微调。
HumanEval 性能
| 模型 | HumanEval(Pass@1) | 日期 |
|---|---|---|
| CodeFuse-DeepSeek-33B | 78.7% | 2024/01 |
| CodeFuse-CodeLlama-34B | 74.4% | 2023/09 |
| CodeFuse-CodeLlama-34B-4bits | 73.8% | 2023/09 |
| CodeFuse-StarCoder2-15B | 73.2% | 2023/05 |
| WizardCoder-Python-34B-V1.0 | 73.2% | 2023/08 |
| GPT-4(零样本) | 67.0% | 2023/03 |
| PanGu-Coder2 15B | 61.6% | 2023/08 |
| CodeFuse-Mixtral-8x7B | 56.1% | 2024/01 |
| CodeFuse-StarCoder-15B | 54.9% | 2023/08 |
| CodeLlama-34b-Python | 53.7% | 2023/08 |
| CodeFuse-QWen-14B | 48.8% | 2023/10 |
| CodeLlama-34b | 48.8% | 2023/08 |
| GPT-3.5(零样本) | 48.1% | 2022/11 |
| OctoCoder | 46.2% | 2023/08 |
| StarCoder-15B | 33.6% | 2023/05 |
| QWen-14B | 32.3% | 2023/10 |
文章
MFTCoder: 通过多任务微调提升代码大语言模型性能 (KDD2024)
简介
高精度高效率的代码大语言模型多任务微调框架。
MFTCoder 是 CodeFuse 的一个开源项目,用于大语言模型(尤其是代码任务大语言模型)的高精度高效率多任务微调(MFT)。 此外,我们还开源了代码大语言模型和代码相关数据集,与 MFTCoder 框架一同发布。
在 MFTCoder 中,我们发布了两个用于微调大语言模型的代码库:
MFTCoder-accelerate是一个基于 accelerate 和 DeepSpeed/FSDP 的框架。所有技术栈都是开源且活跃的。我们强烈建议您尝试这个框架,让您的微调过程更加精确高效。MFTCoder-atorch基于 ATorch 框架,这是一个快速的分布式 LLM 训练框架。
该项目旨在促进合作并分享大语言模型领域的进展,特别是在代码开发领域。
框架
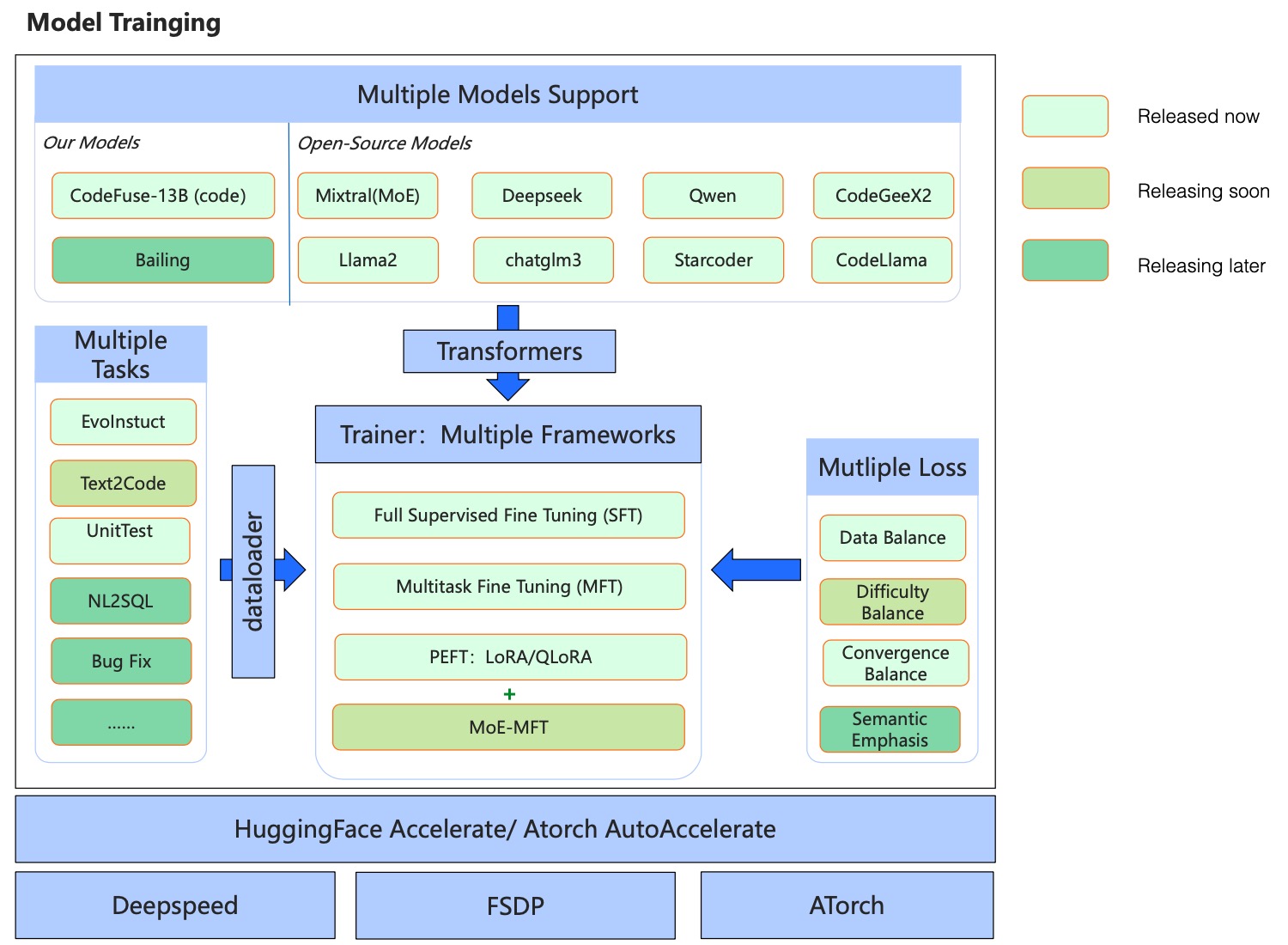
亮点
:white_check_mark: 多任务:在多个任务上训练模型,同时保持它们之间的平衡。模型甚至可以泛化到新的、以前未见过的任务。
:white_check_mark: 多模型:集成了最先进的开源模型,如 gpt-neox、llama、llama-2、baichuan、Qwen、chatglm2 等。(这些微调后的模型将在不久的将来发布。)
:white_check_mark: 多框架:同时支持 Accelerate(配合 Deepspeed 和 FSDP)和 ATorch
:white_check_mark: 高效微调:支持 LoRA、QLoRA 以及全参数训练,能够以最少的资源微调大型模型。训练速度满足几乎所有微调场景的需求。
该项目的主要组成部分包括:
- 同时支持 SFT(监督微调)和 MFT(多任务微调)。当前的 MFTCoder 实现了多个任务之间的数据平衡,未来的版本将在训练过程中实现任务难度和收敛速度之间的平衡。
- 支持 QLoRA 指令微调、LoRA 微调以及全参数微调。
- 支持大多数主流开源大模型,尤其是与代码大语言模型相关的模型,如 DeepSeek-coder、Mistral、Mixtral、Chatglm3、Code-LLaMA、Starcoder、Codegeex2、Qwen、GPT-Neox 等。
- 支持 LoRA 适配器和基础模型之间的权重合并,简化推理过程。
- 发布了 2 个高质量的代码相关指令微调数据集:Evol-instruction-66k 和 CodeExercise-Python-27k。
- 发布了多个代码大语言模型,请参阅以下组织:huggingface 上的 codefuse-ai 或 modelscope 上的 codefuse-ai。
要求
首先,确保您已成功安装 CUDA(版本 >= 11.4,最好是 12.1)以及必要的驱动程序。此外,确保您已安装 torch(版本 >= 2.1.0)。
接下来,我们提供了一个 init_env.sh 脚本来简化所需包的安装。执行以下命令运行脚本:
sh init_env.sh
我们强烈建议使用 flash attention(版本 >= 2.3.0)进行训练,请参考以下链接获取安装说明:https://github.com/Dao-AILab/flash-attention
训练
如上所述,我们开源了两个训练框架。您可以参考它们各自的 README 获取更多详细信息。
如果您熟悉开源的 transformers、DeepSpeed 或 FSDP,我们强烈建议您尝试:
🚀🚀 MFTCoder-accelerate:用于 MFT(多任务微调)的 Accelerate + Deepspeed/FSDP 代码库
如果您想探索一些新框架,如 atorch,可以查看:
🚀 MFTCoder-atorch:用于 MFT(多任务微调)的 Atorch 代码库
模型
我们很高兴发布以下两个由 MFTCoder 训练的代码大语言模型,现已在 HuggingFace 和 ModelScope 上同时提供:
| 模型 | HuggingFace 链接 | ModelScope 链接 | 基础模型 | 训练样本数 | 批量大小 | 序列长度 |
|---|---|---|---|---|---|---|
| 🔥 CodeFuse-DeepSeek-33B | h-链接 | m-链接 | DeepSeek-coder-33B | 60万 | 80 | 4096 |
| 🔥 CodeFuse-Mixtral-8x7B | h-链接 | m-链接 | Mixtral-8x7B | 60万 | 80 | 4096 |
| 🔥 CodeFuse-CodeLlama-34B | h-链接 | m-链接 | CodeLlama-34b-Python | 60万 | 80 | 4096 |
| 🔥 CodeFuse-CodeLlama-34B-4bits | h-链接 | m-链接 | CodeLlama-34b-Python | 4096 | ||
| 🔥 CodeFuse-StarCoder-15B | h-链接 | m-链接 | StarCoder-15B | 60万 | 80 | 4096 |
| 🔥 CodeFuse-QWen-14B | h-链接 | m-链接 | Qwen-14b | 110万 | 256 | 4096 |
| 🔥 CodeFuse-CodeGeex2-6B | h-链接 | m-链接 | CodeGeex2-6B | 110万 | 256 | 4096 |
| 🔥 CodeFuse-StarCoder2-15B | h-链接 | m-链接 | Starcoder2-15B | 70万 | 128 | 4096 |
数据集
我们很高兴发布两个精心筛选的代码相关指令数据集,这些数据集来自各种数据源,用于多任务训练。未来,我们将继续发布涵盖各种代码相关任务的更多指令数据集。
| 数据集 | 描述 |
|---|---|
| ⭐ Evol-instruction-66k | 基于open-evol-instruction-80k,过滤掉质量低、重复和与HumanEval相似的指令,从而得到高质量的代码指令数据集。 |
| ⭐ CodeExercise-Python-27k | Python代码练习指令数据集 |
贡献
欢迎贡献!如果您有任何建议、想法、错误报告或新的模型/功能支持,请提出问题或提交拉取请求。
引用
如果您发现我们的工作对您的研发工作有用或有帮助,请随时按以下方式引用我们的论文。
@article{mftcoder2023,
title={MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning},
author={Bingchang Liu and Chaoyu Chen and Cong Liao and Zi Gong and Huan Wang and Zhichao Lei and Ming Liang and Dajun Chen and Min Shen and Hailian Zhou and Hang Yu and Jianguo Li},
year={2023},
journal={arXiv preprint arXiv},
archivePrefix={arXiv},
eprint={2311.02303}
}
星标历史
加入我们
我们是蚂蚁集团平台技术事业群内的AI Native团队,致力于蚂蚁集团平台工程的智能化。我们的团队成立已超过三年,在支持蚂蚁集团云计算基础设施的智能运维方面发挥了关键作用。我们的使命是通过世界级的技术创新和影响力,构建具有广泛用户基础的算法服务和平台,支持内外部产品和业务的落地。
我们的团队秉持创新驱动的理念,不仅支持业务落地,还推动技术影响力。在过去三年里,我们在ICLR、NeurIPS、KDD和ACL等顶级会议上发表了20多篇论文。我们的创新业务成果为我们赢得了两项蚂蚁科技最高级别的T-Star奖和一项蚂蚁集团SuperMA奖。截至2024年2月,我们的开源项目CodeFuse已获得4K星标,我们的模型在Huggingface和Modelscope上的下载量超过150万次。
我们正在寻找顶尖人才加入我们充满活力的团队!如果您渴望在一个充满能量、创新和追求卓越文化的环境中发展事业,我们欢迎您探索我们面向校园和社会招聘的职业机会。加入我们,成为创造行业下一个里程碑的一份子。
社会招聘:https://talent.antgroup.com/off-campus-position?positionId=1933830











