
 访问官网
访问官网 Github
GithubComfyUI的TensorRT节点
此节点通过利用NVIDIA TensorRT,为NVIDIA RTX™显卡(GPU)上的Stable Diffusion提供最佳性能。
支持:
- Stable Diffusion 1.5
- Stable Diffusion 2.1
- Stable Diffusion 3.0
- SDXL
- SDXL Turbo
- Stable Video Diffusion
- Stable Video Diffusion-XT
- AuraFlow
要求:
- GeForce RTX™或NVIDIA RTX™ GPU
- 对于SDXL和SDXL Turbo,由于其规模和计算密集性,建议使用具有12 GB或更多VRAM的GPU以获得最佳性能。
- 对于Stable Video Diffusion (SVD),建议使用具有16 GB或更多VRAM的GPU。
- 对于Stable Video Diffusion-XT (SVD-XT),建议使用具有24 GB或更多VRAM的GPU。
安装
安装这些节点的推荐方式是使用ComfyUI Manager,轻松将它们安装到您的ComfyUI实例中。
您也可以通过将仓库git克隆到ComfyUI/custom_nodes文件夹并安装要求来手动安装它们,如下所示:
cd custom_nodes
git clone https://github.com/comfyanonymous/ComfyUI_TensorRT
cd ComfyUI_TensorRT
pip install -r requirements.txt
描述
NVIDIA TensorRT允许您为特定的NVIDIA RTX GPU优化AI模型的运行方式,从而释放最高性能。为此,我们需要生成特定于您的GPU的TensorRT引擎。
您可以选择构建动态或静态TensorRT引擎:
-
动态引擎支持一系列分辨率和批量大小,由最小和最大参数指定。在使用最佳(opt)分辨率和批量大小时会获得最佳性能,因此请为您最常用的分辨率和批量大小指定opt参数。
-
静态引擎仅支持单一分辨率和批量大小。它们提供与动态引擎最佳设置相同的性能提升。
注意:大多数用户会更喜欢动态引擎,但如果您大部分时间使用特定的分辨率+批量大小组合,静态引擎可能会很有用。静态引擎还需要更少的VRAM;动态范围越广,消耗的VRAM就越多。
使用说明
您可以在此仓库的workflows文件夹中找到不同的工作流程。 这些.json文件可以在ComfyUI中加载。
从检查点构建TensorRT引擎
-
添加一个加载检查点节点
-
在ComfyUI中添加一个静态模型TensorRT转换节点或动态模型TensorRT转换节点
-
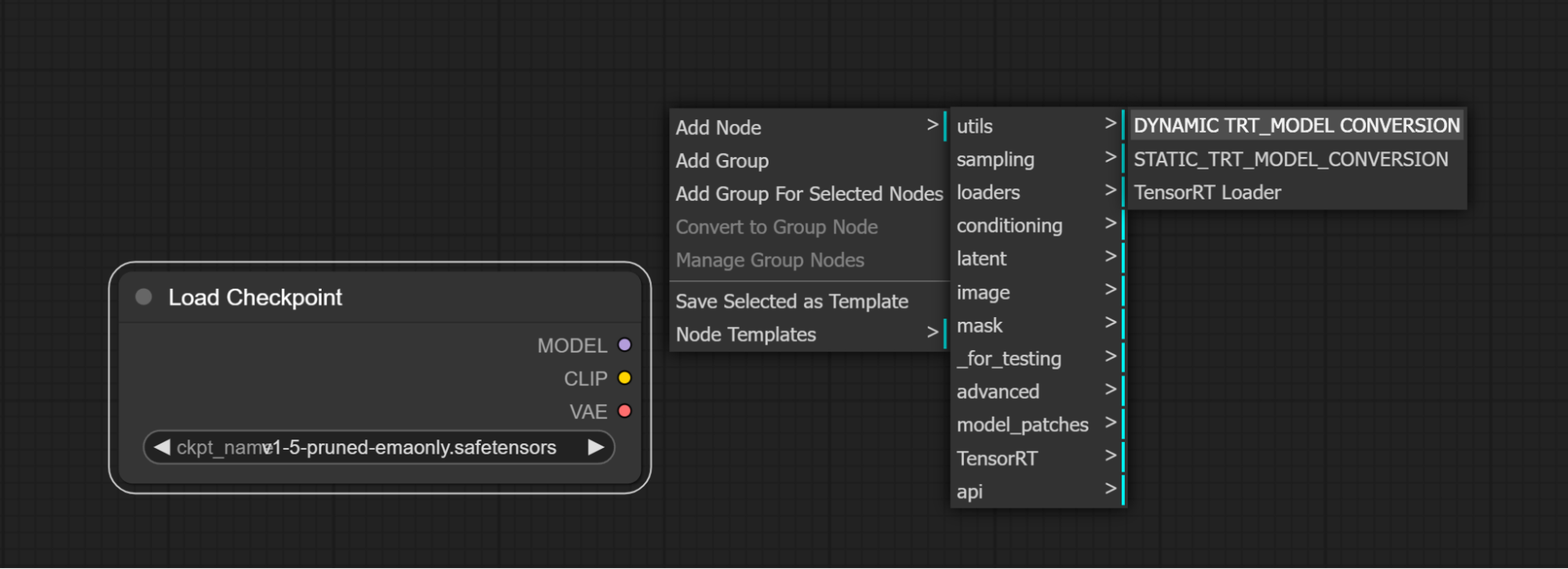
-
将加载检查点模型输出连接到TensorRT转换节点模型输入。
-
-
-
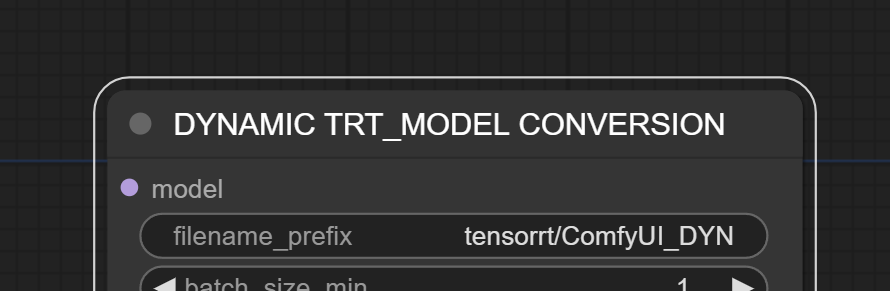
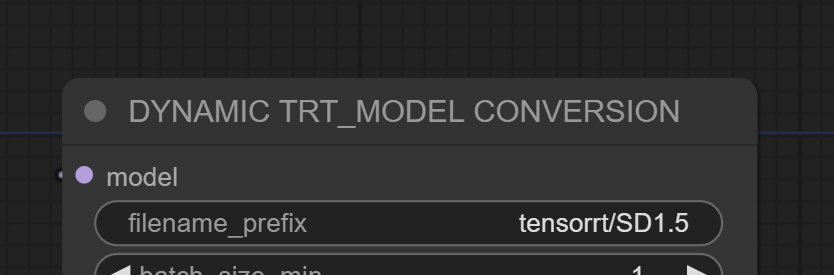
为了帮助识别转换后的TensorRT模型,提供一个有意义的文件名前缀,将此文件名添加在"tensorrt/"之后
-

-
点击队列提示开始构建TensorRT引擎
-


在构建TensorRT引擎时,模型转换节点将被突出显示。
有关模型转换过程的其他信息可以在控制台中看到。

首次为检查点生成引擎将需要一段时间。之后为同一检查点生成的额外引擎将会快得多。生成引擎可能需要3-10分钟用于图像生成模型,10-25分钟用于SVD。SVD-XT是一个极其庞大的模型 - 引擎构建时间可能需要长达一小时。
使用TensorRT引擎加速图像生成
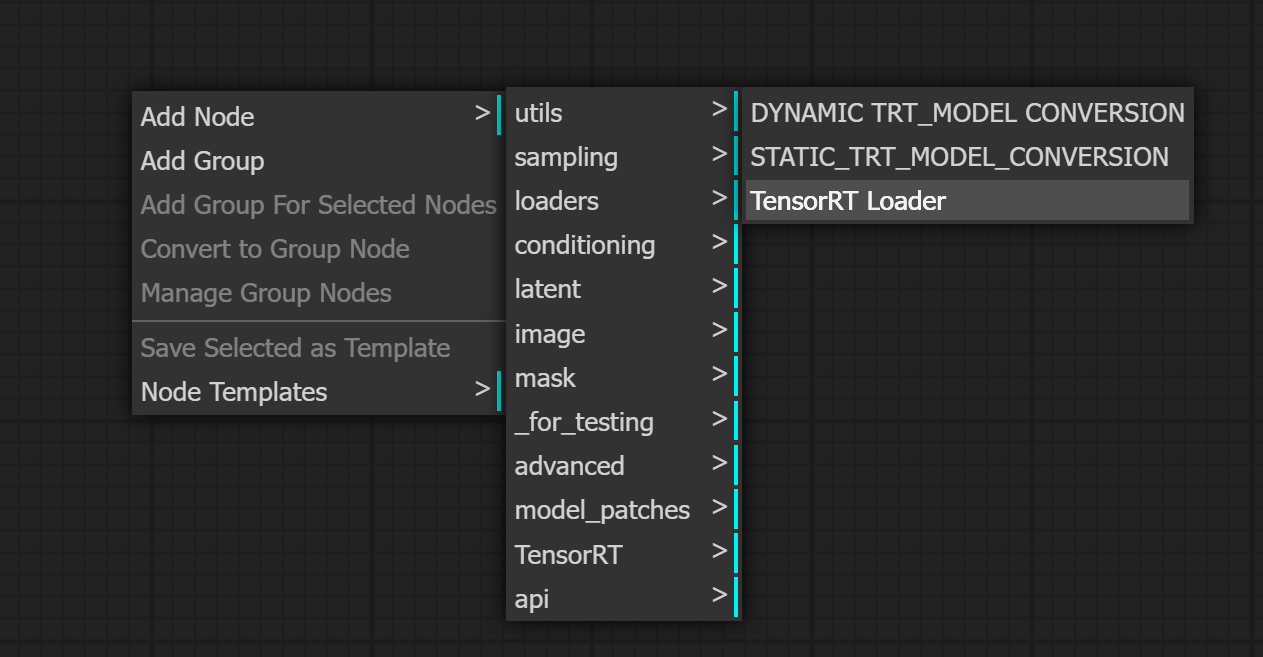
TensorRT引擎使用TensorRT加载器节点加载。
常见问题/限制
ComfyUI TensorRT引擎目前还不兼容ControlNets或LoRAs。在未来的更新中将启用兼容性。
-
添加一个TensorRT加载器节点
-
注意,如果在ComfyUI会话期间创建了TensorRT引擎,在刷新ComfyUI界面之前,它不会显示在TensorRT加载器中(F5刷新浏览器)。
-
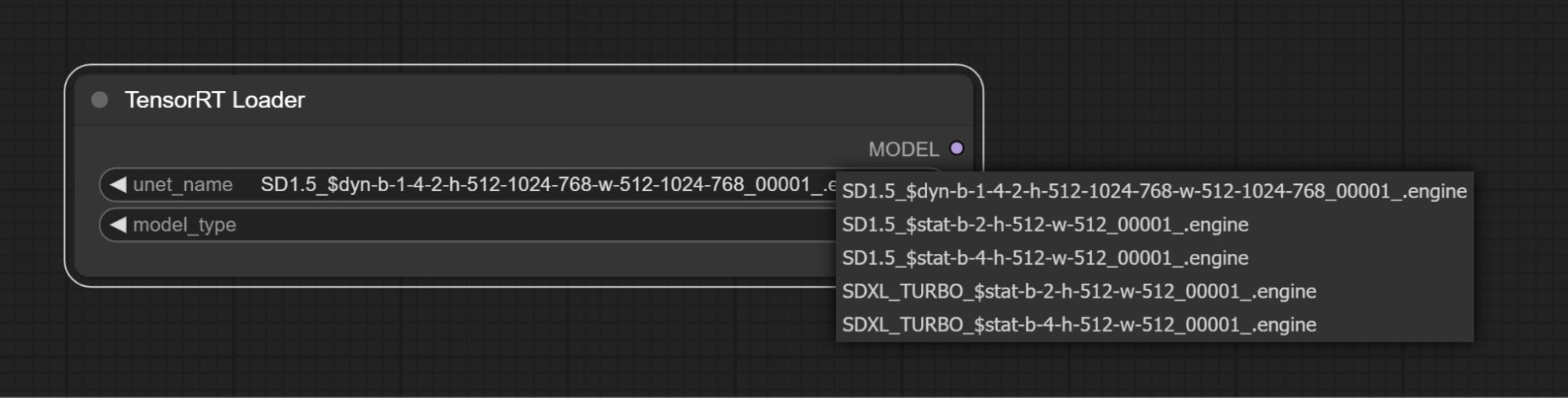
-
从unet_name下拉列表中选择一个TensorRT引擎
-
动态引擎将使用以下文件名格式:
-
dyn-b-min-max-opt-h-min-max-opt-w-min-max-opt
-
dyn=动态,b=批量大小,h=高度,w=宽度
-
静态引擎将使用以下文件名格式:
-
stat-b-opt-h-opt-w-opt
-
stat=静态,b=批量大小,h=高度,w=宽度
-
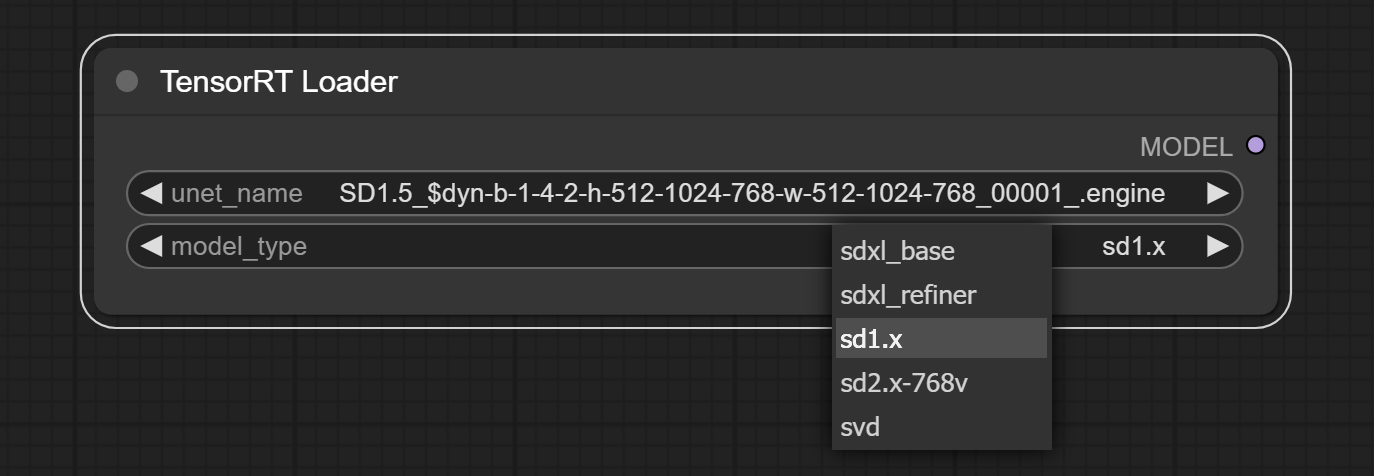
-
model_type必须与TensorRT引擎的模型类型匹配。
-
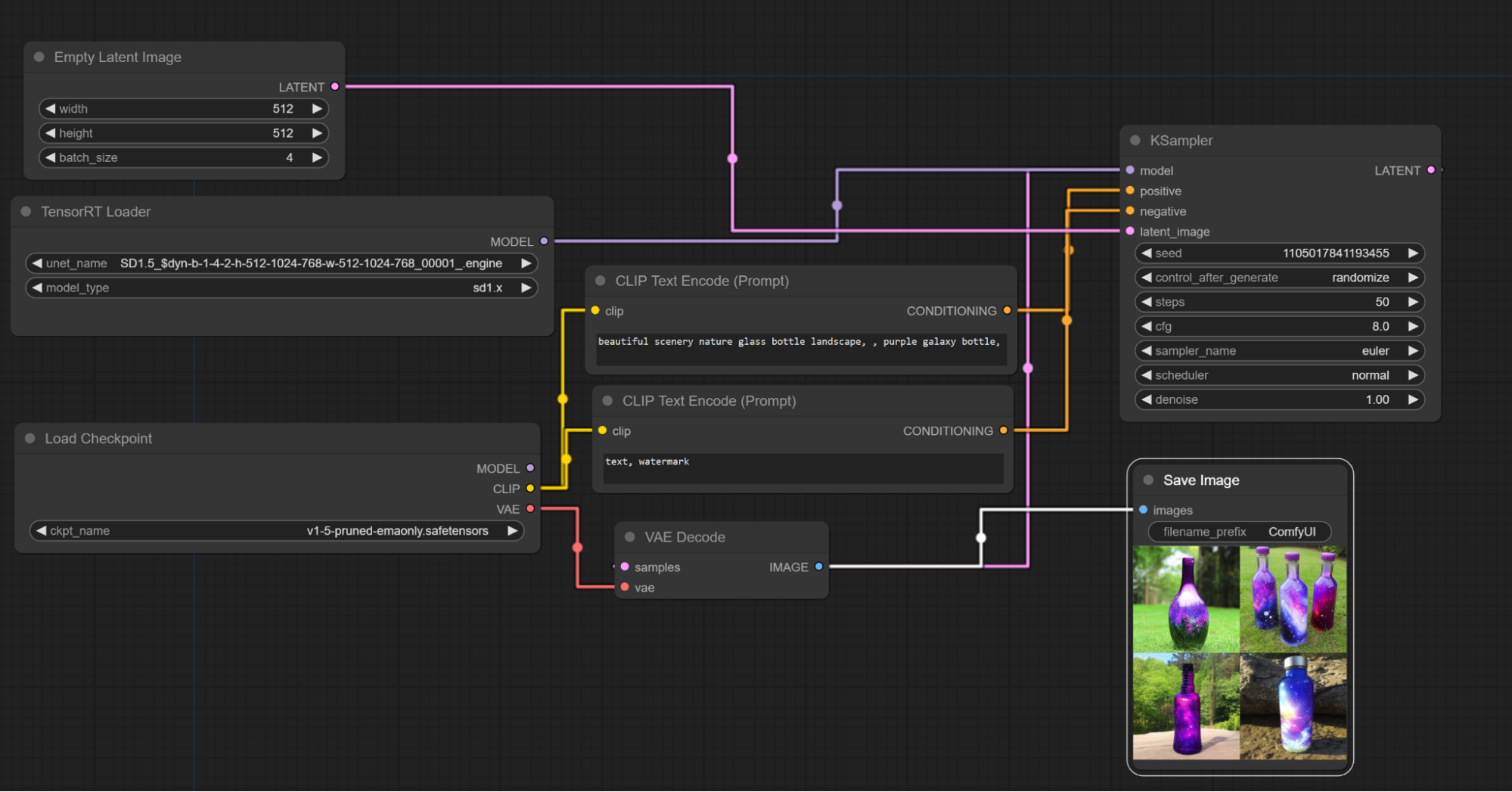
-
工作流程的CLIP和VAE需要从原始模型检查点使用,TensorRT加载器的MODEL输出将连接到采样器。











