
 Github
Github Huggingface
Huggingface 文档
文档 论文
论文StreamDiffusion
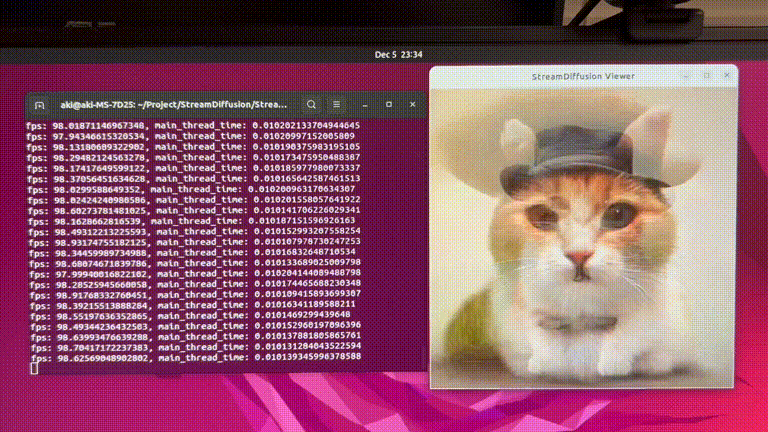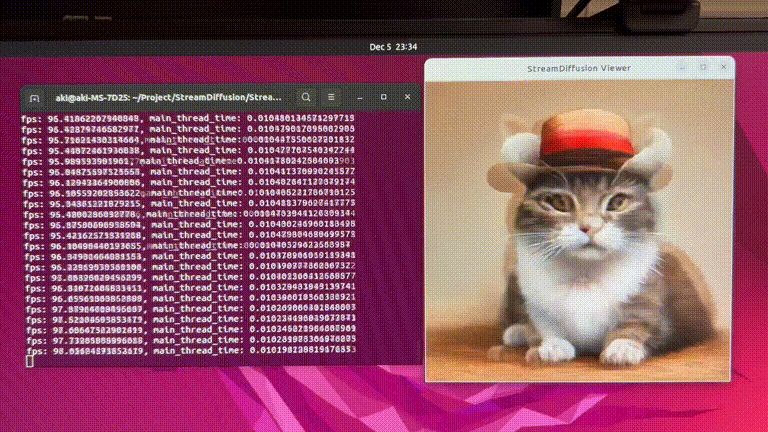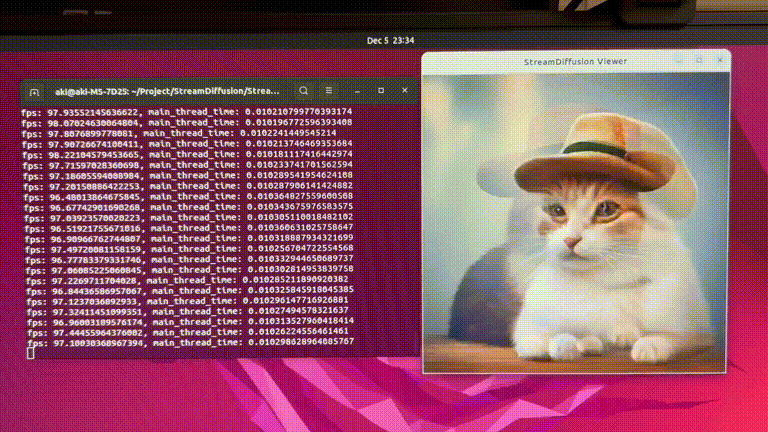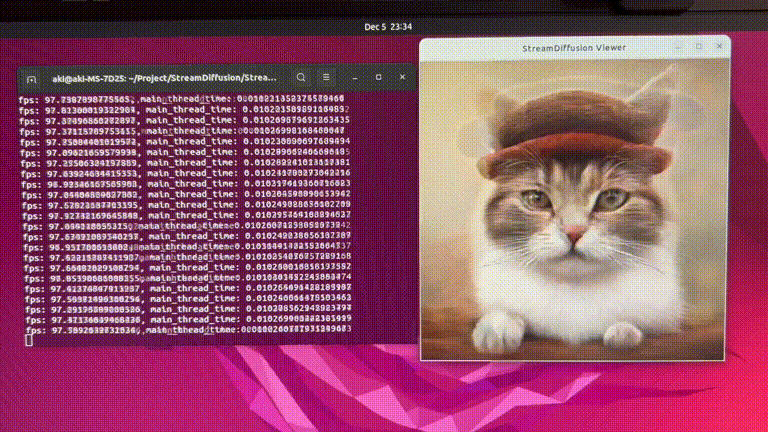
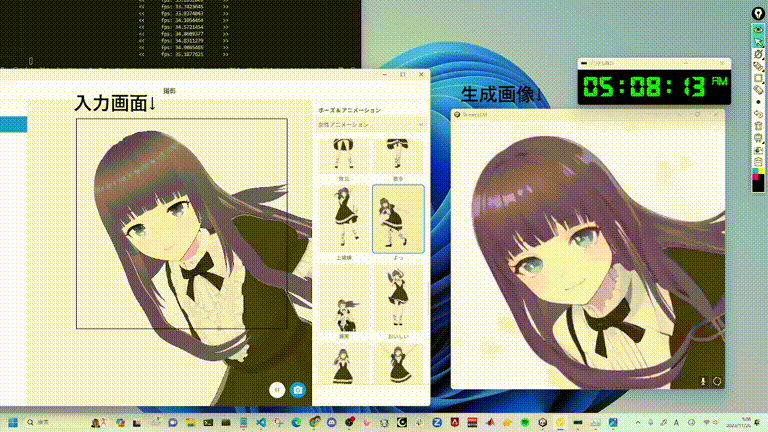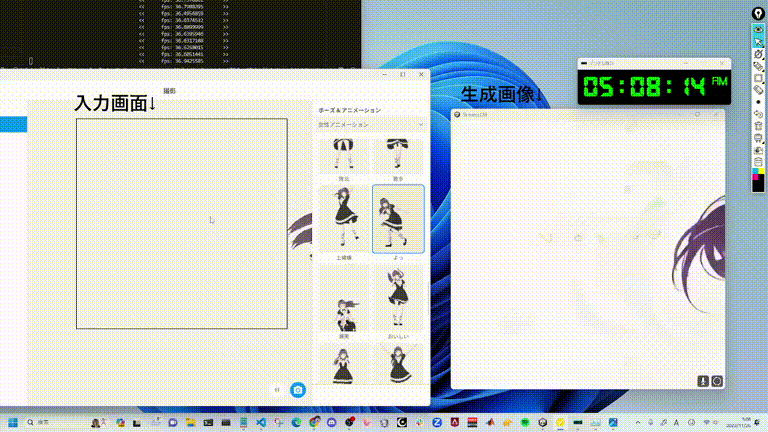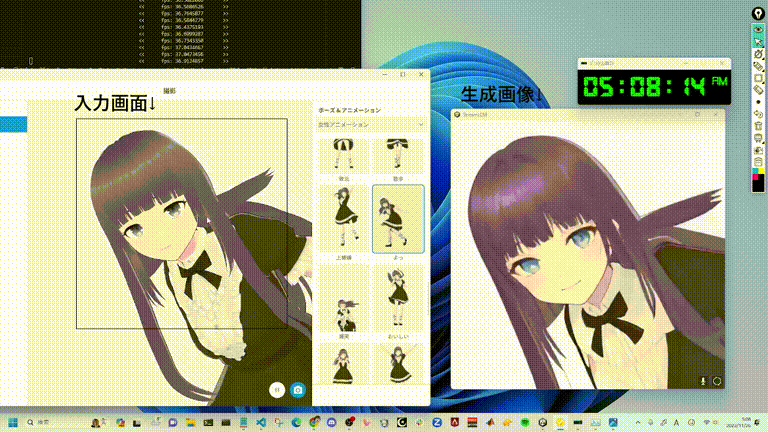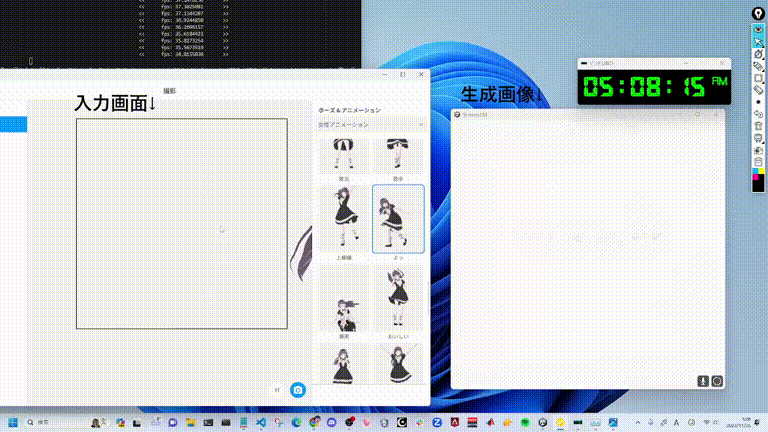
StreamDiffusion: 一种用于实时交互式生成的流水线级解决方案
作者: Akio Kodaira, Chenfeng Xu, Toshiki Hazama, Takanori Yoshimoto, Kohei Ohno, Shogo Mitsuhori, Soichi Sugano, Hanying Cho, Zhijian Liu, Kurt Keutzer
StreamDiffusion是一种创新的扩散流水线,专为实时交互式生成而设计。它为当前基于扩散的图像生成技术带来了显著的性能提升。

我们衷心感谢Taku Fujimoto、Radamés Ajna和Hugging Face团队提供的宝贵反馈、热情支持和深刻见解。
主要特点
-
Stream Batch
- 通过高效的批处理操作简化数据处理。
-
残差无分类器引导 - 了解更多
- 改进的引导机制,最大限度地减少计算冗余。
-
随机相似性过滤器 - 了解更多
- 通过先进的过滤技术提高GPU利用效率。
-
IO队列
- 高效管理输入和输出操作,实现更流畅的执行。
-
KV缓存预计算
- 优化缓存策略以加速处理。
-
模型加速工具
- 利用各种工具进行模型优化和性能提升。
当在GPU: RTX 4090、CPU: Core i9-13900K和操作系统: Ubuntu 22.04.3 LTS的环境中使用我们提出的StreamDiffusion流水线生成图像时。
| 模型 | 去噪步骤 | 文本生图fps | 图像生图fps |
|---|---|---|---|
| SD-turbo | 1 | 106.16 | 93.897 |
| LCM-LoRA + KohakuV2 | 4 | 38.023 | 37.133 |
请随意点击提供的链接探索每个功能,以了解更多关于StreamDiffusion的功能。如果您觉得它有帮助,请考虑引用我们的工作:
@article{kodaira2023streamdiffusion,
title={StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation},
author={Akio Kodaira and Chenfeng Xu and Toshiki Hazama and Takanori Yoshimoto and Kohei Ohno and Shogo Mitsuhori and Soichi Sugano and Hanying Cho and Zhijian Liu and Kurt Keutzer},
year={2023},
eprint={2312.12491},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
安装
步骤0: 克隆此仓库
git clone https://github.com/cumulo-autumn/StreamDiffusion.git
步骤1: 创建环境
您可以通过pip、conda或Docker(解释如下)安装StreamDiffusion。
conda create -n streamdiffusion python=3.10
conda activate streamdiffusion
或者
python -m venv .venv
# Windows
.\.venv\Scripts\activate
# Linux
source .venv/bin/activate
步骤2: 安装PyTorch
选择适合您系统的版本。
CUDA 11.8
pip3 install torch==2.1.0 torchvision==0.16.0 xformers --index-url https://download.pytorch.org/whl/cu118
CUDA 12.1
pip3 install torch==2.1.0 torchvision==0.16.0 xformers --index-url https://download.pytorch.org/whl/cu121
步骤3: 安装StreamDiffusion
对于用户
安装StreamDiffusion
#最新版本(推荐)
pip install git+https://github.com/cumulo-autumn/StreamDiffusion.git@main#egg=streamdiffusion[tensorrt]
#或者
#稳定版本
pip install streamdiffusion[tensorrt]
安装TensorRT扩展
python -m streamdiffusion.tools.install-tensorrt
(仅限Windows)如果您安装了稳定版本(pip install streamdiffusion[tensorrt]),可能还需要额外安装pywin32。
pip install --force-reinstall pywin32
对于开发者
python setup.py develop easy_install streamdiffusion[tensorrt]
python -m streamdiffusion.tools.install-tensorrt
Docker安装(TensorRT就绪)
git clone https://github.com/cumulo-autumn/StreamDiffusion.git
cd StreamDiffusion
docker build -t stream-diffusion:latest -f Dockerfile .
docker run --gpus all -it -v $(pwd):/home/ubuntu/streamdiffusion stream-diffusion:latest
快速开始
您可以在examples目录中尝试StreamDiffusion。
 |  |
|---|---|
 |  |
实时文本生成图像演示
在demo/realtime-txt2img目录中有一个交互式文本生成图像演示!

实时图像生成图像演示
在demo/realtime-img2img目录中有一个使用网络摄像头实时视频或屏幕捕捉的图像生成图像演示!

使用示例
我们提供了一个简单的StreamDiffusion使用示例。有关更详细的示例,请参阅examples目录。
图像到图像
import torch
from diffusers import AutoencoderTiny, StableDiffusionPipeline
from diffusers.utils import load_image
from streamdiffusion import StreamDiffusion
from streamdiffusion.image_utils import postprocess_image
# 您可以使用diffuser的StableDiffusionPipeline加载任何模型
pipe = StableDiffusionPipeline.from_pretrained("KBlueLeaf/kohaku-v2.1").to(
device=torch.device("cuda"),
dtype=torch.float16,
)
# 用StreamDiffusion包装流水线
stream = StreamDiffusion(
pipe,
t_index_list=[32, 45],
torch_dtype=torch.float16,
)
# 如果加载的模型不是LCM,则合并LCM
stream.load_lcm_lora()
stream.fuse_lora()
# 使用Tiny VAE进一步加速
stream.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd").to(device=pipe.device, dtype=pipe.dtype)
# 启用加速
pipe.enable_xformers_memory_efficient_attention()
prompt = "1girl with dog hair, thick frame glasses"
# 准备流
stream.prepare(prompt)
# 准备图像
init_image = load_image("assets/img2img_example.png").resize((512, 512))
# 预热 >= len(t_index_list) x frame_buffer_size
for _ in range(2):
stream(init_image)
# 无限运行流
while True:
x_output = stream(init_image)
postprocess_image(x_output, output_type="pil")[0].show()
input_response = input("按Enter继续或输入'stop'退出:")
if input_response == "stop":
break
文本到图像
import torch
from diffusers import AutoencoderTiny, StableDiffusionPipeline
from streamdiffusion import StreamDiffusion
from streamdiffusion.image_utils import postprocess_image
# 您可以使用diffuser的StableDiffusionPipeline加载任何模型
pipe = StableDiffusionPipeline.from_pretrained("KBlueLeaf/kohaku-v2.1").to(
device=torch.device("cuda"),
dtype=torch.float16,
)
# 用StreamDiffusion包装流水线
# 文本到图像需要更长的步骤(len(t_index_list))
# 建议在文本到图像时使用cfg_type="none"
stream = StreamDiffusion(
pipe,
t_index_list=[0, 16, 32, 45],
torch_dtype=torch.float16,
cfg_type="none",
)
如果加载的模型不是LCM,则合并LCM
stream.load_lcm_lora() stream.fuse_lora()
使用Tiny VAE进一步加速
stream.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd").to(device=pipe.device, dtype=pipe.dtype)
启用加速
pipe.enable_xformers_memory_efficient_attention()
prompt = "戴着厚框眼镜的狗耳朵女孩"
准备流
stream.prepare(prompt)
预热 >= len(t_index_list) x frame_buffer_size
for _ in range(4): stream()
无限运行流
while True: x_output = stream.txt2img() postprocess_image(x_output, output_type="pil")[0].show() input_response = input("按回车继续或输入'stop'退出:") if input_response == "stop": break
你可以使用SD-Turbo让它更快。
### 更快的生成
在上面的例子中替换以下代码:
```python
pipe.enable_xformers_memory_efficient_attention()
替换为:
from streamdiffusion.acceleration.tensorrt import accelerate_with_tensorrt
stream = accelerate_with_tensorrt(
stream, "engines", max_batch_size=2,
)
这需要TensorRT扩展和时间来构建引擎,但会比上面的例子更快。
可选项
随机相似度过滤器
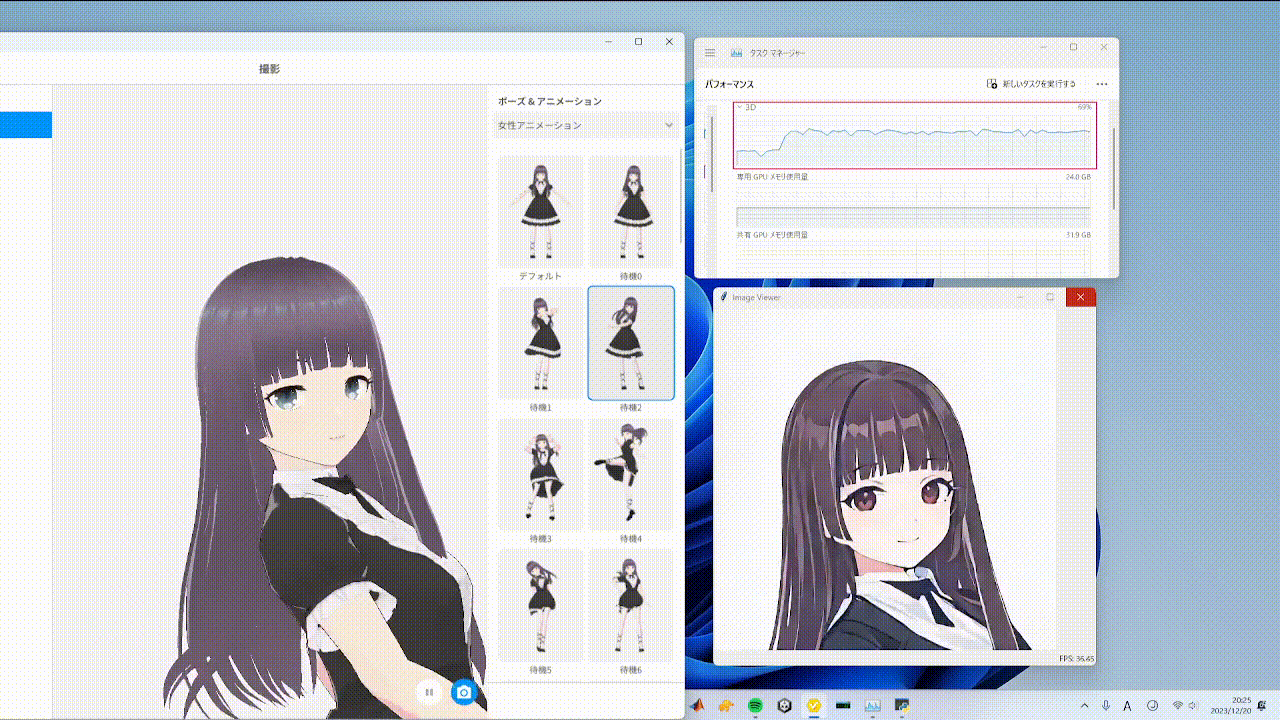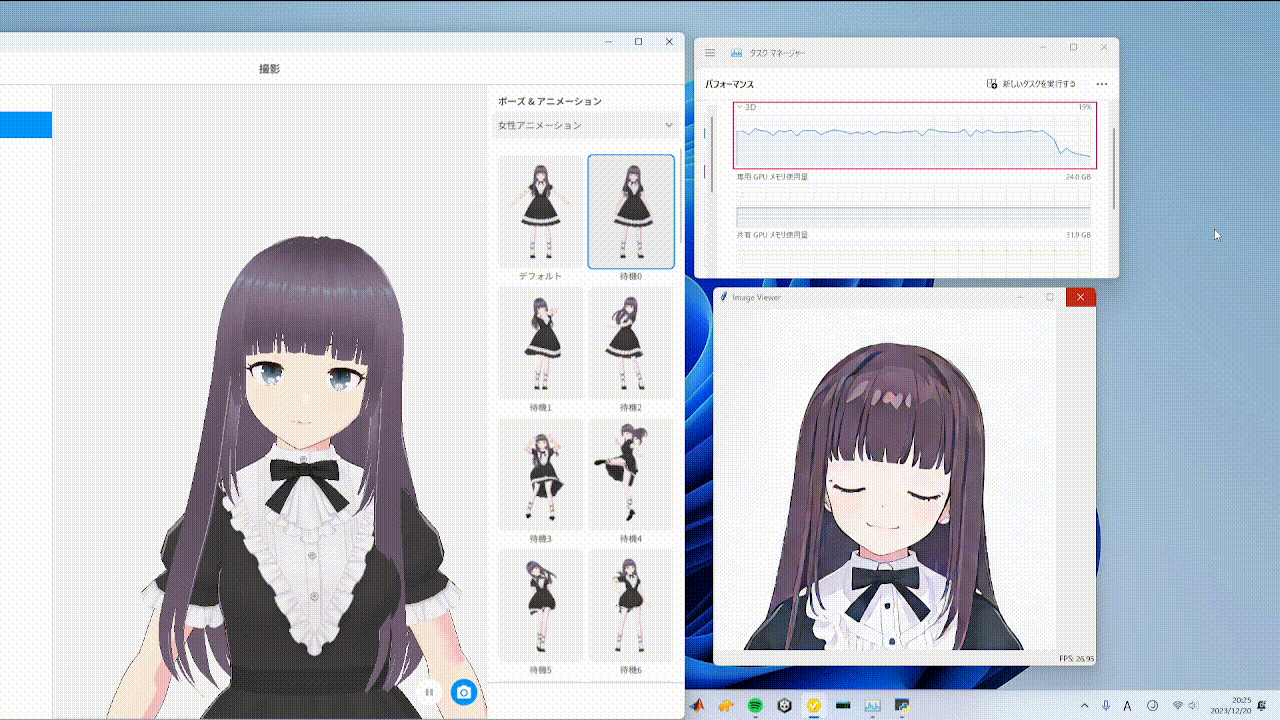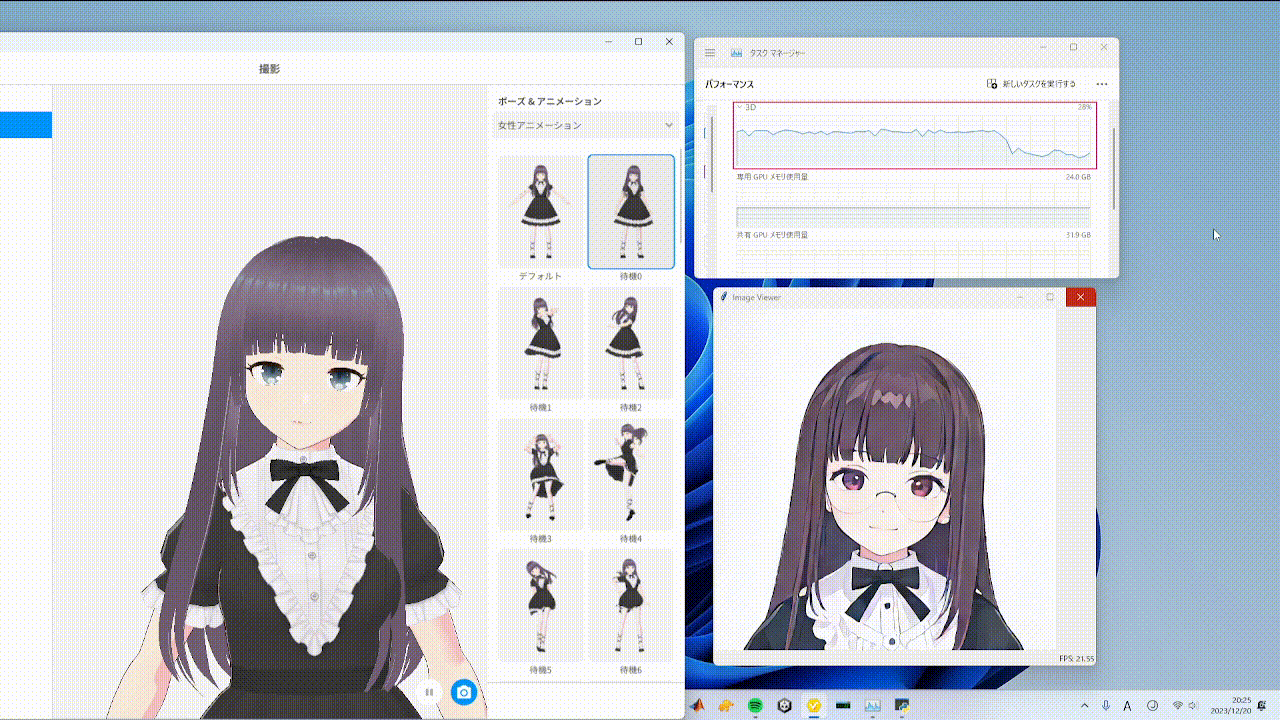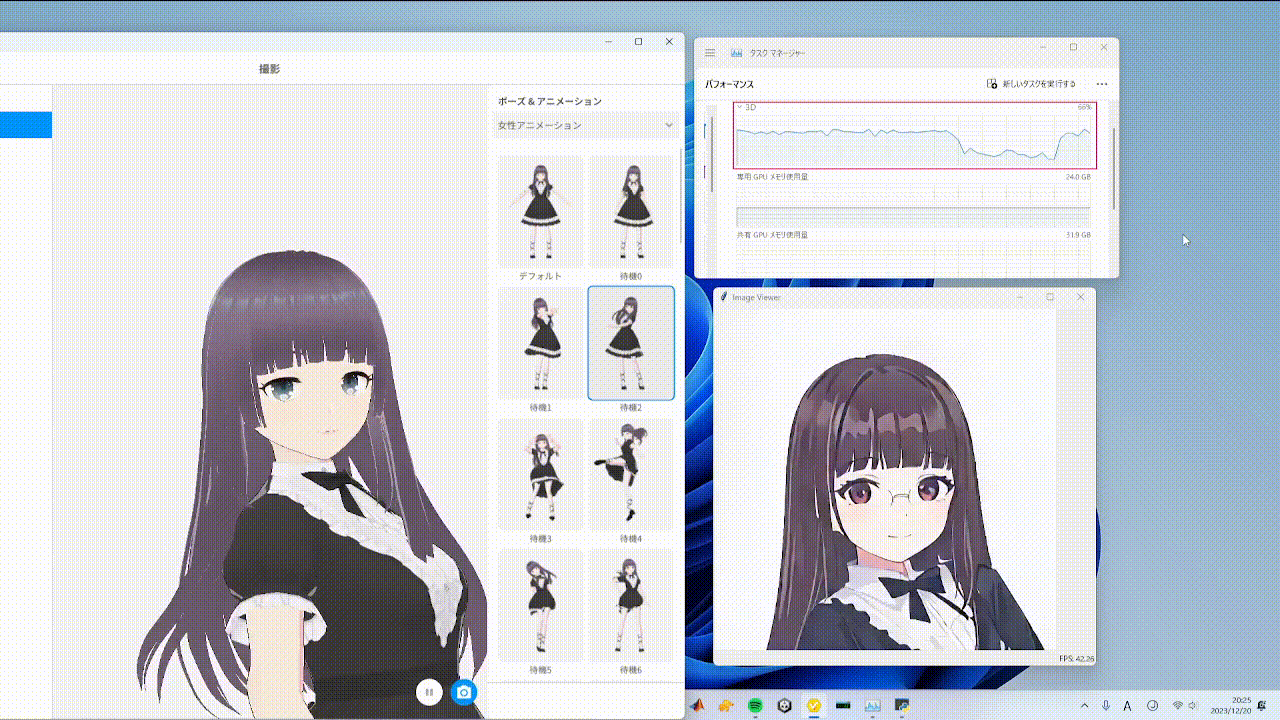
随机相似度过滤器通过在与前一帧变化不大时最小化转换操作,从而减少视频输入时的处理,缓解GPU处理负载,如上面GIF中的红框所示。使用方法如下:
stream = StreamDiffusion(
pipe,
[32, 45],
torch_dtype=torch.float16,
)
stream.enable_similar_image_filter(
similar_image_filter_threshold,
similar_image_filter_max_skip_frame,
)
可以在函数中设置以下参数:
similar_image_filter_threshold
- 前一帧和当前帧之间相似度的阈值,低于此值时处理暂停。
similar_image_filter_max_skip_frame
- 暂停期间恢复转换前的最大间隔。
残差CFG(RCFG)

RCFG是一种近似实现CFG的方法,与不使用CFG的情况相比,具有竞争性的计算复杂度。可以通过StreamDiffusion中的cfg_type参数指定。RCFG有两种类型:一种是没有指定负面提示的RCFG自负面,另一种是可以指定负面提示的RCFG一次性负面。在计算复杂度方面,如果不使用CFG的复杂度为N,使用常规CFG的复杂度为2N,那么RCFG自负面可以在N步内计算,而RCFG一次性负面可以在N+1步内计算。
使用方法如下:
# 不使用CFG
cfg_type = "none"
# CFG
cfg_type = "full"
# RCFG自负面
cfg_type = "self"
# RCFG一次性负面
cfg_type = "initialize"
stream = StreamDiffusion(
pipe,
[32, 45],
torch_dtype=torch.float16,
cfg_type=cfg_type,
)
stream.prepare(
prompt="1girl, purple hair",
guidance_scale=guidance_scale,
delta=delta,
)
delta参数对RCFG的效果有调节作用。
开发团队
Aki、 Ararat、 Chenfeng Xu、 ddPn08、 kizamimi、 ramune、 teftef、 Tonimono、 Verb
(*按字母顺序排列)
致谢
本GitHub仓库中的视频和图像演示是使用LCM-LoRA + KohakuV2和SD-Turbo生成的。
特别感谢LCM-LoRA作者提供LCM-LoRA,Kohaku BlueLeaf (@KBlueleaf)提供KohakuV2模型,以及Stability AI提供SD-Turbo。
KohakuV2模型可以从Civitai和Hugging Face下载。
SD-Turbo也可在Hugging Face Space上获取。











