
Dask-SQL 目前不处于活跃维护状态,更多信息请参见 #1344








dask-sql 是一个用 Python 编写的分布式 SQL 查询引擎。它允许您使用常见的 SQL 操作和 Python 代码的组合来查询和转换数据,并且在需要时可以轻松扩展计算。
- 结合 Python 和 SQL 的力量:使用 Python 加载数据,用 SQL 转换数据,用 Python 增强数据,再用 SQL 查询数据 - 或者反过来。使用
dask-sql,您可以混合使用pandas和Dask的熟悉的 Python 数据框 API 和常见的 SQL 操作,以最适合您的方式处理数据。 - 无限扩展:利用强大的
Dask生态系统,您的计算可以根据需要进行扩展 - 从笔记本电脑到超级集群 - 无需更改任何 SQL 代码。从 k8s 到云部署,从批处理系统到 YARN - 只要Dask支持,dask-sql就支持。 - 您的数据 - 您的查询:在 SQL 中使用 Python 用户定义函数(UDF),无性能损失,并使用大量 Python 库扩展您的 SQL 查询,例如机器学习、不同的复杂输入格式、复杂统计等。
- 易于安装和维护:
dask-sql只需一个 pip/conda 安装(如果您喜欢,也可以使用 docker 运行)。 - 从任何地方使用 SQL:
dask-sql可以集成到您的 Jupyter notebook、普通 Python 模块中,也可以作为独立的 SQL 服务器供任何 BI 工具使用。它甚至可以与 Apache Hue 原生集成。 - GPU 支持:
dask-sql通过利用 RAPIDS 库(如cuDF)支持在支持 CUDA 的 GPU 上运行 SQL 查询,实现 SQL 的加速计算。
在文档中了解更多信息。
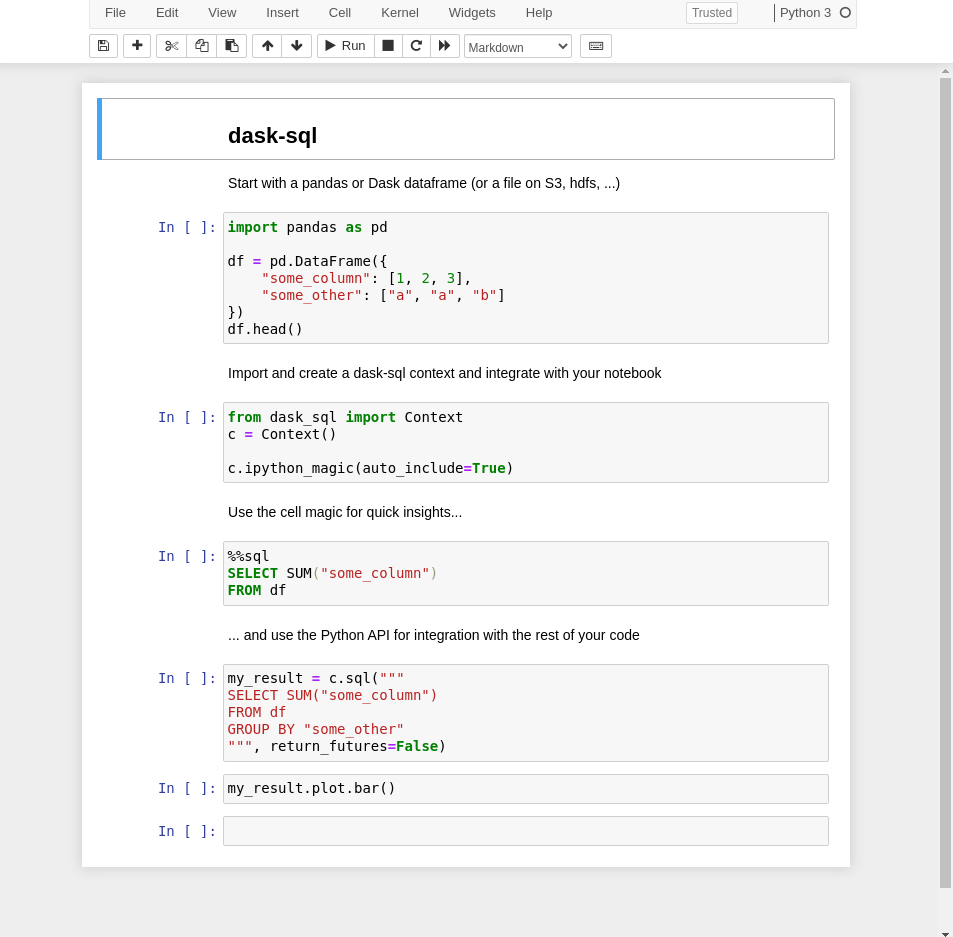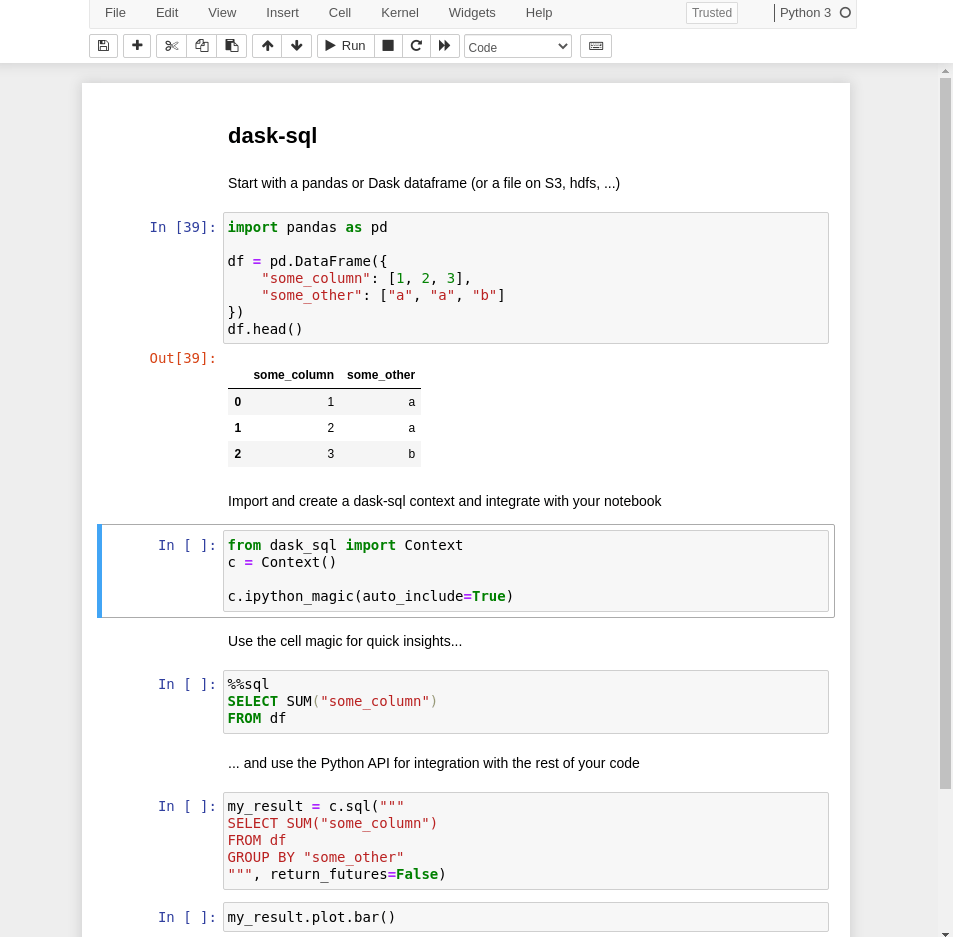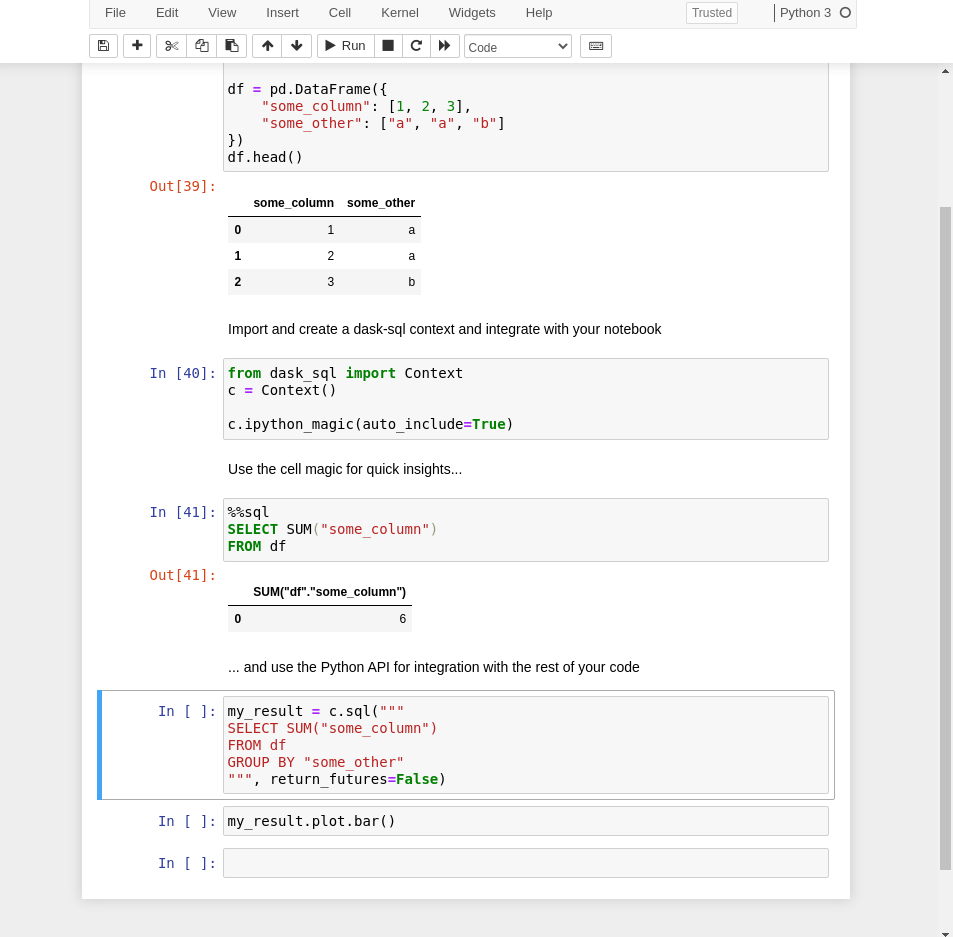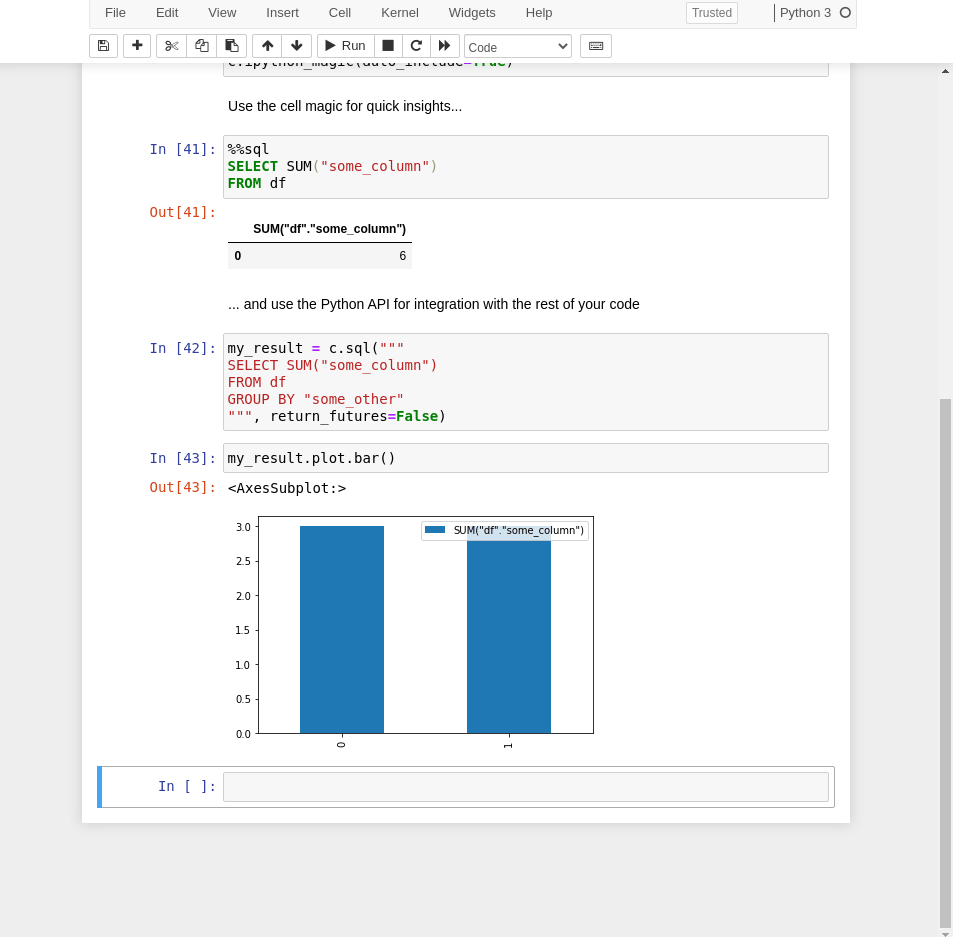
示例
在这个示例中,我们使用从磁盘加载的一些数据,并在 Python 代码中使用 SQL 命令查询它们。任何 pandas 或 dask 数据框都可以作为输入,dask-sql 可以理解大量格式(csv、parquet、json 等)和位置(s3、hdfs、gcs 等)。
import dask.dataframe as dd
from dask_sql import Context
# 创建一个上下文来保存注册的表
c = Context()
# 加载数据并在上下文中注册
# 这将为表指定一个名称,我们可以在查询中使用
df = dd.read_csv("...")
c.create_table("my_data", df)
# 现在执行一个 SQL 查询。结果仍然是 dask 数据框。
result = c.sql("""
SELECT
my_data.name,
SUM(my_data.x)
FROM
my_data
GROUP BY
my_data.name
""", return_futures=False)
# 显示结果
print(result)
快速开始
dask-sql目前正在开发中,到目前为止还不能理解所有的 SQL 命令(但已经支持很大一部分)。 我们正在积极寻求反馈、改进和贡献者!
安装
dask-sql 可以通过 conda(首选)或 pip 安装 - 或在开发环境中安装。
使用 conda
创建一个新的 conda 环境或使用您已有的环境:
conda create -n dask-sql
conda activate dask-sql
从 conda-forge 通道安装软件包:
conda install dask-sql -c conda-forge
使用 pip
您可以使用以下命令安装软件包:
pip install dask-sql
用于开发
如果您想要最新(未发布)的 dask-sql 版本,或者计划对 dask-sql 进行开发,您也可以从源代码安装软件包。
git clone https://github.com/dask-contrib/dask-sql.git
创建一个新的 conda 环境并安装开发环境:
conda env create -f continuous_integration/environment-3.9.yaml
不建议使用 pip 代替 conda 进行环境设置。
之后,您可以在开发模式下安装软件包:
pip install -e ".[dev]"
Rust DataFusion 绑定作为 pip install 的一部分构建。
请注意,如果对 src/ 中的 Rust 源代码进行了更改,必须再次运行构建以重新编译绑定。
这个仓库使用 pre-commit 钩子。要安装它们,请调用:
pre-commit install
测试
安装后,您可以使用以下命令运行测试:
pytest tests
GPU 特定的测试需要 continuous_integration/gpuci/environment.yaml 中指定的额外依赖项。
可以通过运行以下命令将这些依赖项添加到开发环境中:
conda env update -n dask-sql -f continuous_integration/gpuci/environment.yaml
可以使用以下命令运行 GPU 特定的测试:
pytest tests -m gpu --rungpu
SQL 服务器
dask-sql 附带了一个小型测试实现的 SQL 服务器。
我们没有重新构建完整的 ODBC 驱动程序,而是重用了 presto 线协议。
到目前为止,这只是开发的起点,缺少重要的概念,如身份验证。
您可以通过在一个终端中运行以下命令来测试 SQL presto 服务器(安装后):
dask-sql-server
或使用创建的 docker 镜像:
docker run --rm -it -p 8080:8080 nbraun/dask-sql
这将在端口 8080(默认)上启动一个服务器,对任何 presto 客户端来说,它看起来类似于普通的 presto 数据库。
您可以使用默认的 presto 客户端 进行测试:
presto --server localhost:8080
现在您可以执行简单的 SQL 查询(由于默认情况下没有加载数据):
=> SELECT 1 + 1;
EXPR$0
--------
2
(1 row)
您可以在文档中找到更多信息。
CLI
您还可以运行 CLI dask-sql 来快速测试 SQL 命令:
dask-sql --load-test-data --startup
(dask-sql) > SELECT * FROM timeseries LIMIT 10;
它是如何工作的?
dask-sql 的核心做了两件事:
- 使用 DataFusion 将 SQL 查询转换为关系代数,表示为逻辑查询计划 - 类似于许多其他 SQL 引擎(Hive、Flink 等)
- 将这个查询描述转换为 dask API 调用(并执行它们)- 返回一个 dask 数据框。
对于第一步,Arrow DataFusion 需要知道 dask 数据框的列和类型,因此在 dask_planner 中定义了一些 Rust 代码来存储这些信息。
完成关系代数的转换后(使用 DaskSQLContext.logical_relational_algebra),dask_sql.physical 中定义的 Python 方法将其转换为物理 dask 执行计划,逐一转换关系代数的每个部分。











