
 访问官网
访问官网 Github
Github 文档
文档类Perplexity启发的大语言模型问答引擎
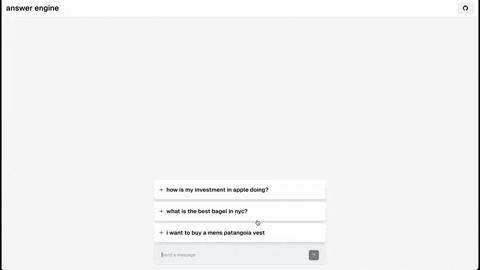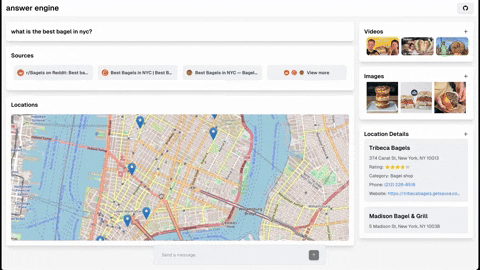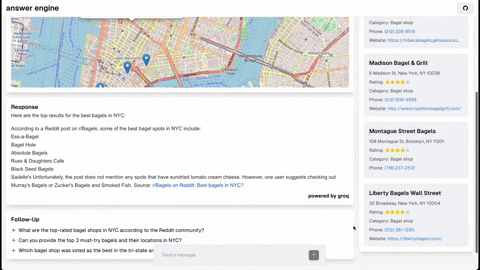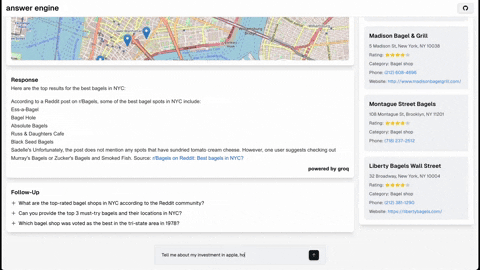
本仓库包含构建一个复杂问答引擎所需的代码和说明,该引擎利用了Groq、Mistral AI的Mixtral、Langchain.JS、Brave Search、Serper API和OpenAI的功能。该项目旨在根据用户查询高效返回来源、答案、图片、视频和后续问题,是对自然语言处理和搜索技术感兴趣的开发者的理想起点。
YouTube教程




使用的技术
- Next.js:用于构建服务器端渲染和静态网络应用的React框架。
- Tailwind CSS:一个实用优先的CSS框架,用于快速构建自定义用户界面。
- Vercel AI SDK:Vercel AI SDK是一个用于构建AI驱动的流式文本和聊天UI的库。
- Groq & Mixtral:用于处理和理解用户查询的技术。
- Langchain.JS:专注于文本操作(如文本分割和嵌入)的JavaScript库。
- Brave Search:一个注重隐私的搜索引擎,用于获取相关内容和图片。
- Serper API:用于根据用户查询获取相关视频和图片结果。
- OpenAI Embeddings:用于创建文本块的向量表示。
- Cheerio:用于HTML解析,允许从网页提取内容。
- Ollama(可选):用于流式推理和嵌入。
- Upstash Redis 限速(可选):用于为应用设置速率限制。
- Upstash 语义缓存(可选):用于缓存数据以加快响应时间。
入门指南
前提条件
- 确保您的机器上安装了Node.js和npm。
- 获取OpenAI、Groq、Brave Search和Serper的API密钥。
获取API密钥
- OpenAI API密钥:在此生成您的OpenAI API密钥。
- Groq API密钥:在此获取您的Groq API密钥。
- Brave Search API密钥:在此获取您的Brave Search API密钥。
- Serper API密钥:在此获取您的Serper API密钥。
安装
- 克隆仓库:
git clone https://github.com/developersdigest/llm-answer-engine.git - 安装所需依赖:
或npm installbun install - 在项目根目录创建一个
.env文件并添加您的API密钥:OPENAI_API_KEY=您的openai_api密钥 GROQ_API_KEY=您的groq_api密钥 BRAVE_SEARCH_API_KEY=您的brave_search_api密钥 SERPER_API=您的serper_api密钥
运行服务器
要启动服务器,执行:
npm run dev
或
bun run dev
服务器将在指定端口上监听。
编辑配置
配置文件位于app/config.tsx文件中。您可以修改以下值:
- useOllamaInference: false,
- useOllamaEmbeddings: false,
- inferenceModel: 'mixtral-8x7b-32768',
- inferenceAPIKey: process.env.GROQ_API_KEY,
- embeddingsModel: 'text-embedding-3-small',
- textChunkSize: 800,
- textChunkOverlap: 200,
- numberOfSimilarityResults: 2,
- numberOfPagesToScan: 10,
- nonOllamaBaseURL: 'https://api.groq.com/openai/v1'
- useFunctionCalling: true
- useRateLimiting: false
- useSemanticCache: false
- usePortkey: false
函数调用支持(测试版)
目前,函数调用支持以下功能:
- 地图和位置(Serper位置API)
- 购物(Serper购物API)
- TradingView股票数据(免费小部件)
- Spotify(免费API)
- 如果您希望在此看到任何其他功能,请开启一个问题或提交PR。
- 要启用函数调用和条件流式UI(目前处于测试阶段),请确保在配置文件中将useFunctionCalling设置为true。
Ollama 支持(部分支持)
目前,Ollama 支持流式文本响应,但尚不支持后续问题。
Ollama 支持嵌入,但在同时使用本地嵌入模型和本地流式推理模型时,首次令牌响应时间可能较长。建议减少 app/config.tsx 文件中指定的 RAG 值,以减少使用 Ollama 时的首次令牌响应时间。
开始使用时,请确保在本地机器上运行 Ollama 模型,并在配置中设置您想使用的模型,同时将 useOllamaInference 和/或 useOllamaEmbeddings 设置为 true。
注意:当 'useOllamaInference' 设置为 true 时,模型将用于文本生成,但使用 Ollama 时会跳过后续问题推理步骤。
更多信息:https://ollama.com/blog/openai-compatibility
路线图
- [] 添加文档上传 + RAG 用于文档搜索/检索
- [] 添加设置组件,允许用户从 UI 选择模型、嵌入模型和其他参数
- [] 添加使用 Ollama 时的后续问题支持
- [已完成] 添加扩散模型支持(从 Fal.AI SD3 开始),通过 '@ 提及' 访问
- [已完成] 添加 AI 网关以支持多个模型和嵌入(OpenAI、Azure OpenAI、Anyscale、Google Gemini & Palm、Anthropic、Cohere、Together AI、Perplexity、Mistral、Nomic、AI21、Stability AI、DeepInfra、Ollama 等)
https://github.com/Portkey-AI/gateway - [已完成] 添加语义缓存支持以提高响应时间
- [已完成] 根据用户查询添加动态和条件渲染的 UI 组件支持
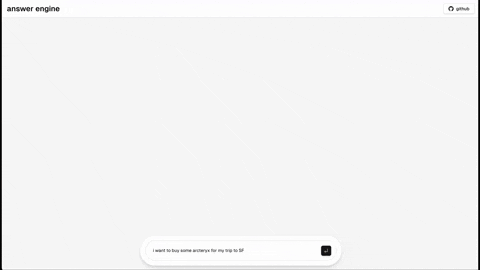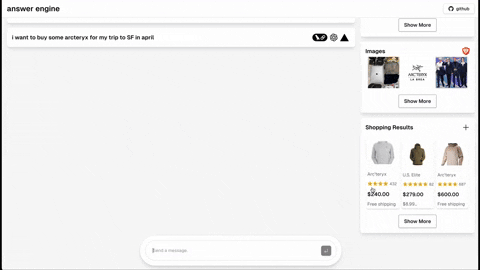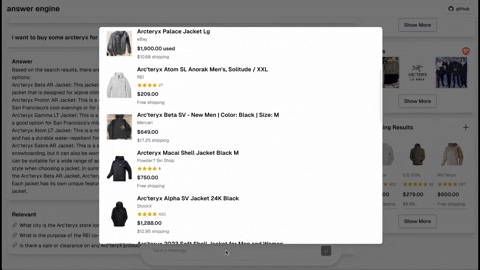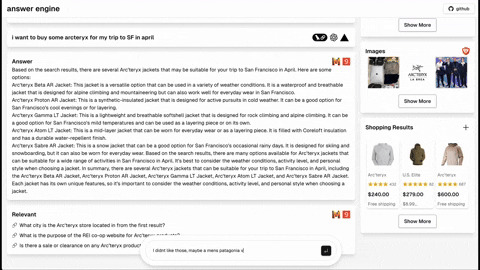
- [已完成] 根据用户系统偏好添加深色模式支持
后端 + 仅 Node 的 Express API
在此观看 Express 教程,获取有关设置和运行此项目的详细指南。 除了 Next.JS 版本的项目外,还有一个仅使用 Node.js 和 Express 的后端版本,位于 'express-api' 目录中。这是项目的独立版本,可作为构建类似 API 的参考。'express-api' 目录中还有一个 readme 文件,解释了如何运行后端版本。
Upstash Redis 速率限制
在此观看 Upstash Redis 速率限制教程,获取有关设置和运行此项目的详细指南。 Upstash Redis 速率限制是一项免费服务,允许您为应用程序设置速率限制。它提供了一个简单易用的界面,用于配置和管理速率限制。使用 Upstash,您可以轻松设置每个用户、IP 地址或其他标准的请求数量限制。这有助于防止滥用并确保您的应用程序不会被请求淹没。
贡献
欢迎对项目做出贡献。随时 fork 仓库,进行更改,并提交拉取请求。您也可以开设问题以提出改进建议或报告错误。
许可证
本项目采用 MIT 许可证。
我是 Developers Digest 背后的开发者。如果您觉得我的工作有帮助或喜欢我所做的,请考虑支持我。以下是几种支持方式:
- Patreon:在 patreon.com/DevelopersDigest 上支持我
- Buy Me A Coffee:您可以在 buymeacoffee.com/developersdigest 给我买杯咖啡
- 网站:访问我的网站 developersdigest.tech
- Github:在 GitHub 上关注我 github.com/developersdigest
- Twitter:在 Twitter 上关注我 twitter.com/dev__digest











