
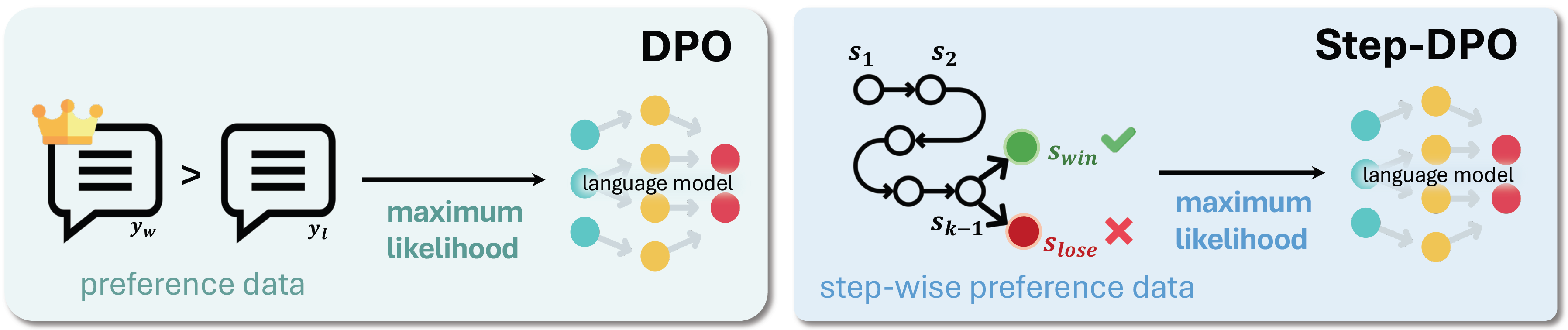
Step-DPO:大型语言模型长链推理的逐步偏好优化
Xin Lai、 Zhuotao Tian、 Yukang Chen、 Senqiao Yang、 Xiangru Peng、 Jiaya Jia


本仓库提供了Step-DPO的实现,这是一种简单、有效且数据高效的方法,用于提升大型语言模型的长链推理能力,同时还提供了一个数据构建流程,可生成包含1万对逐步偏好对的高质量数据集。
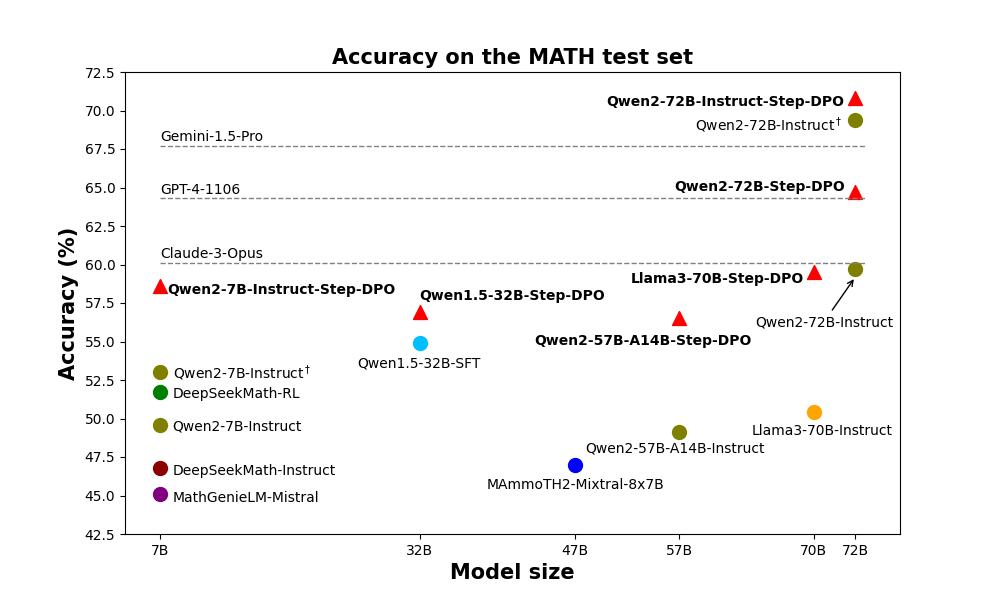
值得注意的是,Step-DPO仅使用1万条数据和数百步训练就将Qwen2-7B-Instruct在MATH上的性能从53.0%提升到58.6%,在GSM8K上从85.5%提升到87.9%!
此外,Step-DPO应用于Qwen2-72B-Instruct后,在MATH和GSM8K测试集上分别达到了**70.8%和94.0%**的得分,超越了一系列闭源模型,包括GPT-4-1106、Claude-3-Opus和Gemini-1.5-Pro,而且无需任何额外技巧。
目录
新闻
- [2024.7.7] 我们发布了数据构建流程的脚本!你可以使用这些脚本自行构建数据集!
- [2024.7.1] 我们发布了模型Qwen2-7B-Instruct-Step-DPO的演示。欢迎在演示上试用!
- [2024.6.28] 我们发布了Step-DPO的预印本和此GitHub仓库,包括训练/评估脚本、预训练模型和数据。
数据集
我们为Step-DPO构建了一个包含1万条数学偏好数据的数据集,可从以下链接下载。
| 数据集 | 大小 | 链接 |
|---|---|---|
| xinlai/Math-Step-DPO-10K | 10,795 | 🤗 Hugging Face |
模型
值得注意的是,Qwen2-72B-Instruct + Step-DPO模型在MATH和GSM8K测试集上分别达到了**70.8%和94.0%**的成绩。Step-DPO还为各种模型带来了显著的改进,如下所示。欢迎下载使用。
| 模型 | 大小 | MATH | GSM8K | Odyssey-MATH | 链接 |
|---|---|---|---|---|---|
| Qwen2-7B-Instruct | 7B | 53.0 | 85.5 | - | - |
| Qwen2-7B-Instruct + Step-DPO | 7B | 58.6 (+5.6) | 87.9 (+2.4) | - | 🤗 HF |
| DeepSeekMath-RL | 7B | 51.7 | 88.2 | - | - |
| DeepSeekMath-RL + Step-DPO | 7B | 53.2 (+1.5) | 88.7 (+0.5) | - | 🤗 HF |
| Qwen2-7B-SFT | 7B | 54.8 | 88.2 | - | 🤗 HF |
| Qwen2-7B-SFT + Step-DPO | 7B | 55.8 (+1.0) | 88.5 (+0.3) | - | 🤗 HF |
| Qwen1.5-32B-SFT | 32B | 54.9 | 90.0 | - | 🤗 HF |
| Qwen1.5-32B-SFT + Step-DPO | 32B | 56.9 (+2.0) | 90.9 (+0.9) | - | 🤗 HF |
| Qwen2-57B-A14B-SFT | 57B | 54.6 | 89.8 | - | 🤗 HF |
| Qwen2-57B-A14B-SFT + Step-DPO | 57B | 56.5 (+1.9) | 90.0 (+0.2) | - | 🤗 HF |
| Llama-3-70B-SFT | 70B | 56.9 | 92.2 | - | 🤗 HF |
| Llama-3-70B-SFT + Step-DPO | 70B | 59.5 (+2.6) | 93.3 (+1.1) | - | 🤗 HF |
| Qwen2-72B-SFT | 72B | 61.7 | 92.9 | 44.2 | 🤗 HF |
| Qwen2-72B-SFT + Step-DPO | 72B | 64.7 (+3.0) | 93.9 (+1.0) | 47.0 (+2.8) | 🤗 HF |
| Qwen2-72B-Instruct | 72B | 69.4 | 92.4 | 47.0 | - |
| Qwen2-72B-Instruct + Step-DPO | 72B | 70.8 (+1.4) | 94.0 (+1.6) | 50.1 (+3.1) | 🤗 HF |
注:Odyssey-MATH包含竞赛级数学问题。
安装
conda create -n step_dpo python=3.10
conda activate step_dpo
pip install -r requirements.txt
训练
预训练权重
我们使用Qwen2、Qwen1.5、Llama-3和DeepSeekMath模型作为预训练权重,并使用Step-DPO对它们进行微调。根据你的选择下载。
| 预训练权重 |
|---|
| Qwen/Qwen2-7B-Instruct |
| deepseek-ai/deepseek-math-7b-rl |
| xinlai/Qwen2-7B-SFT |
| xinlai/Qwen1.5-32B-SFT |
| xinlai/Qwen2-57B-A14B-SFT |
| xinlai/Llama-3-70B-SFT |
| xinlai/Qwen2-72B-SFT |
| Qwen/Qwen2-72B-Instruct |
注意:带有'-SFT'的模型是基于开源基础模型,使用我们的29.9万条SFT数据进行有监督微调的。你可以在我们的SFT模型或现有的开源指令模型上执行Step-DPO。
以下是在Qwen/Qwen2-72B-Instruct上执行Step-DPO的脚本示例:
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file accelerate_configs/deepspeed_zero3_cpu.yaml --mixed_precision bf16 \
--num_processes 8 \
train.py configs/config_full.yaml \
--model_name_or_path="Qwen/Qwen2-72B-Instruct" \
--data_path="xinlai/Math-Step-DPO-10K" \
--per_device_train_batch_size=2 \
--gradient_accumulation_steps=8 \
--torch_dtype=bfloat16 \
--bf16=True \
--beta=0.4 \
--num_train_epochs=4 \
--save_strategy='steps' \
--save_steps=200 \
--save_total_limit=1 \
--output_dir=outputs/qwen2-72b-instruct-step-dpo \
--hub_model_id=qwen2-72b-instruct-step-dpo \
--prompt=qwen2-boxed
评估
以下是在GSM8K和MATH测试集上评估微调模型的脚本示例:
python eval_math.py \
--model outputs/qwen2-72b-instruct-step-dpo \
--data_file ./data/test/GSM8K_test_data.jsonl \
--save_path 'eval_results/gsm8k/qwen2-72b-instruct-step-dpo.json' \
--prompt 'qwen2-boxed' \
--tensor_parallel_size 8
python eval_math.py \
--model outputs/qwen2-72b-instruct-step-dpo \
--data_file ./data/test/MATH_test_data.jsonl \
--save_path 'eval_results/math/qwen2-72b-instruct-step-dpo.json' \
--prompt 'qwen2-boxed' \
--tensor_parallel_size 8
数据构建流程
我们发布了构建Step-DPO数据的脚本,位于data_pipeline/目录中。请按以下说明操作。
cd Step-DPO
# 步骤1:错误收集
# 执行前,请设置MODEL_PATH、PRED_PATH、EVAL_PROMPT
bash data_pipeline/step1.sh
# 步骤2:通过GPT-4定位错误步骤
# 执行前,请设置OPENAI_BASE_URL、OPENAI_API_KEY
bash data_pipeline/step2.sh
# 步骤3:由模型自身纠正
# 执行前,请设置MODEL_PATH、EVAL_PROMPT、JSON_FILE、PRED_PATH、SAVE_PATH
bash data_pipeline/step3.sh
# 最后,获取结果数据集
# 执行前,请设置EVAL_PROMPT、JSON_FILE、PRED_PATH、SAVE_PATH
bash data_pipeline/merge.sh
部署
对于部署,请直接使用以下命令:
python3 app.py --model_path_or_name xinlai/Qwen2-7B-Instruct-Step-DPO
示例



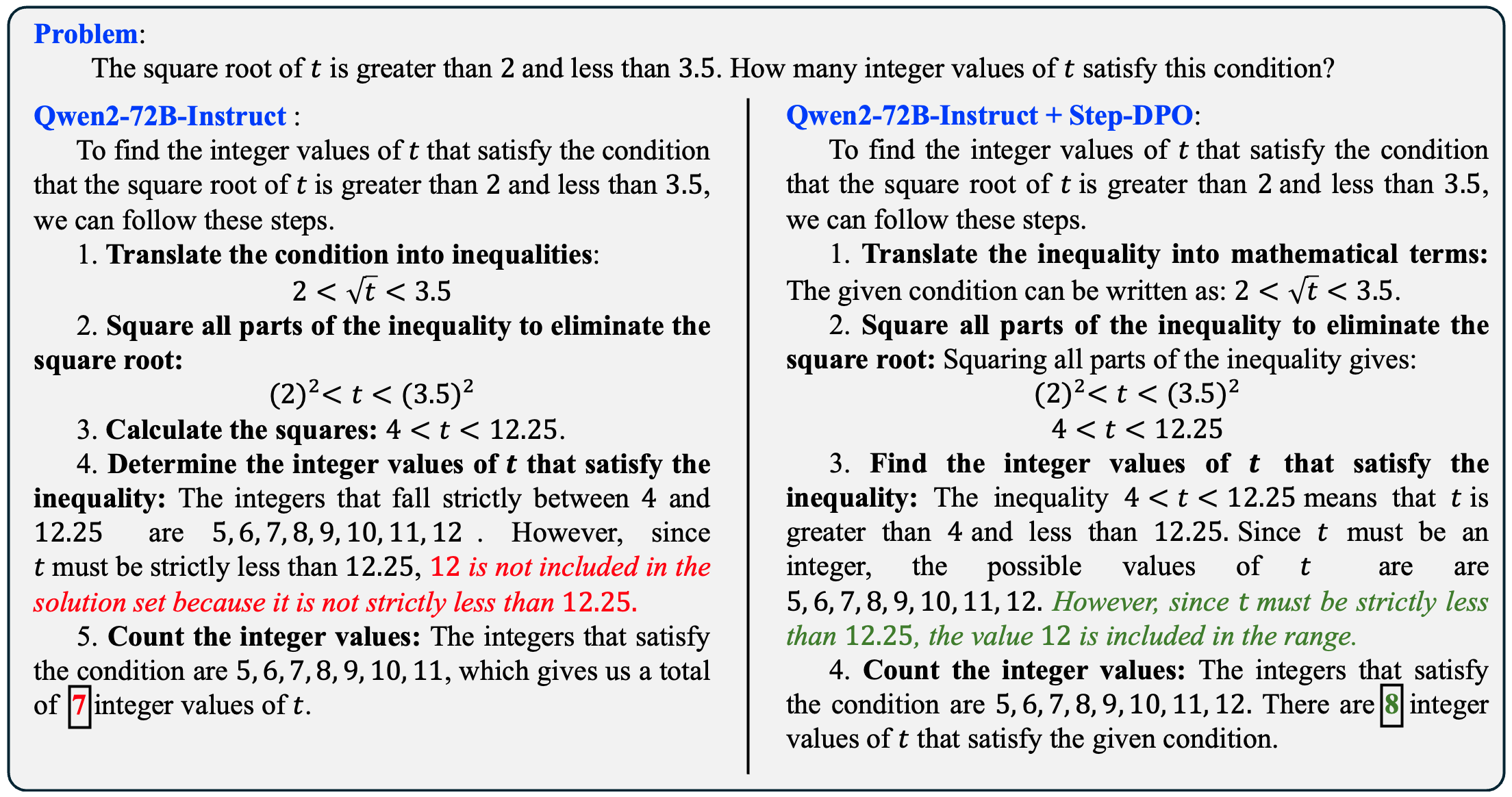
致谢
本仓库基于alignment-handbook、DeepSeekMath和MetaMath。
非常感谢他们的努力!
引用
如果您在研究中发现这个项目有用,请考虑引用我们:
@article{lai2024stepdpo,
title={Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs},
author={Xin Lai and Zhuotao Tian and Yukang Chen and Senqiao Yang and Xiangru Peng and Jiaya Jia},
journal={arXiv:2406.18629},
year={2024}
}











