
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文


忘掉昂贵的 NVIDIA GPU 吧,将您现有的设备整合成一个强大的 GPU:iPhone、iPad、Android、Mac、Linux,几乎任何设备都可以!
参与其中
exo 是实验性软件。早期可能会出现 bug。创建问题以便修复。exo labs 团队将努力快速解决问题。
我们也欢迎社区的贡献。我们在这个表格中列出了一系列悬赏任务。
特性
广泛的模型支持
exo 支持 LLaMA(MLX 和 tinygrad)和其他流行模型。
动态模型分区
exo 根据当前网络拓扑和可用设备资源优化分割模型。这使您能够运行比单个设备更大的模型。
自动设备发现
exo 将使用最佳可用方法自动发现其他设备。零手动配置。
ChatGPT 兼容 API
exo 提供了一个ChatGPT 兼容的 API用于运行模型。在您的应用程序中只需一行更改,就可以使用 exo 在自己的硬件上运行模型。
设备平等
与其他分布式推理框架不同,exo 不使用主从架构。相反,exo 设备点对点连接。只要设备连接到网络中的某个地方,就可以用来运行模型。
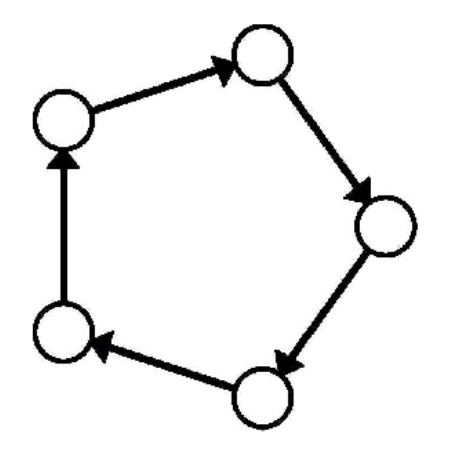
Exo 支持不同的分区策略来在设备间分割模型。默认分区策略是环形内存加权分区。这在一个环中运行推理,每个设备运行与设备内存成比例的模型层数。
安装
目前推荐的安装 exo 的方式是从源代码安装。
前提条件
- 需要 Python>=3.12.0,因为之前版本存在asyncio 问题。
从源代码安装
git clone https://github.com/exo-explore/exo.git
cd exo
pip install .
# 或者,使用 venv
source install.sh
故障排除
- 如果在 Mac 上运行,MLX 有一个安装指南,其中包含故障排除步骤。
文档
在多个 MacOS 设备上的使用示例
设备 1:
python3 main.py
设备 2:
python3 main.py
就是这样!无需配置 - exo 将自动发现其他设备。
访问在 exo 上运行的模型的本地方式是使用带有对等句柄的 exo 库。在这个 Llama 3 示例中查看如何操作。
exo 在 http://localhost:8000 上启动一个类似 ChatGPT 的 WebUI(由 tinygrad tinychat 提供支持)
对于开发者,exo 还在 http://localhost:8000/v1/chat/completions 上启动了一个 ChatGPT 兼容的 API 端点。使用 curl 的示例:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.1-8b",
"messages": [{"role": "user", "content": "exo 的含义是什么?"}],
"temperature": 0.7
}'
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llava-1.5-7b-hf",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "这些是什么?"
},
{
"type": "image_url",
"image_url": {
"url": "http://images.cocodataset.org/val2017/000000039769.jpg"
}
}
]
}
],
"temperature": 0.0
}'
调试
使用 DEBUG 环境变量(0-9)启用调试日志。
DEBUG=9 python3 main.py
已知问题
- 🚧 由于库发展如此之快,iOS 实现已经落后于 Python。我们现在决定不发布有错误的 iOS 版本,以免收到大量针对过时代码的 GitHub 问题。我们正在努力妥善解决这个问题,并将在准备就绪时发布公告。如果您现在想访问 iOS 实现,请发送电子邮件至 alex@exolabs.net,说明您的 GitHub 用户名和使用场景,您将在 GitHub 上获得访问权限。
推理引擎
exo 支持以下推理引擎:











