
 Github
Github 文档
文档

Nevergrad - 一个无梯度优化平台

nevergrad是一个Python 3.8+库。可以通过以下方式安装:
pip install nevergrad
更多安装选项,包括Windows安装和完整说明,可在文档的"入门"部分找到。
你可以在这里加入Nevergrad用户Facebook群组。
使用优化器(这里是NGOpt)最小化函数非常简单:
import nevergrad as ng
def square(x):
return sum((x - .5)**2)
optimizer = ng.optimizers.NGOpt(parametrization=2, budget=100)
recommendation = optimizer.minimize(square)
print(recommendation.value) # 推荐值
>>> [0.49971112 0.5002944]
nevergrad还可以支持有界连续变量以及离散变量,以及这些变量的混合。
为此,可以指定输入空间:
import nevergrad as ng
def fake_training(learning_rate: float, batch_size: int, architecture: str) -> float:
# 最优为learning_rate=0.2, batch_size=4, architecture="conv"
return (learning_rate - 0.2)**2 + (batch_size - 4)**2 + (0 if architecture == "conv" else 10)
# Instrumentation类用于具有多个输入的函数
# (位置参数和/或关键字参数)
parametrization = ng.p.Instrumentation(
# 在0.001和1.0之间对数分布的标量
learning_rate=ng.p.Log(lower=0.001, upper=1.0),
# 1到12之间的整数
batch_size=ng.p.Scalar(lower=1, upper=12).set_integer_casting(),
# "conv"或"fc"
architecture=ng.p.Choice(["conv", "fc"])
)
optimizer = ng.optimizers.NGOpt(parametrization=parametrization, budget=100)
recommendation = optimizer.minimize(fake_training)
# 显示函数的推荐关键字参数
print(recommendation.kwargs)
>>> {'learning_rate': 0.1998, 'batch_size': 4, 'architecture': 'conv'}
在文档中了解更多关于参数化的信息!
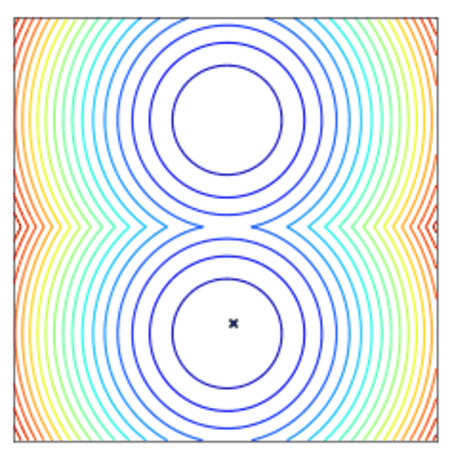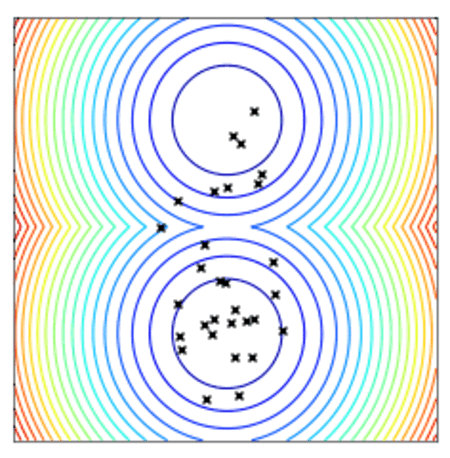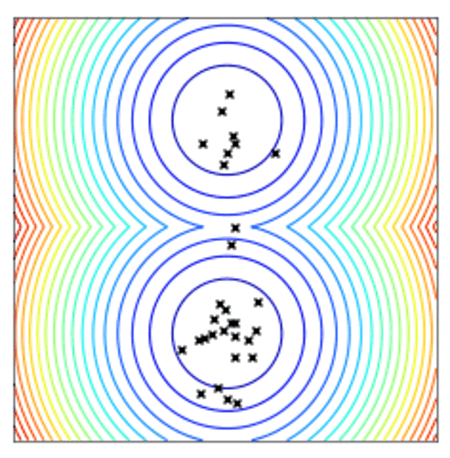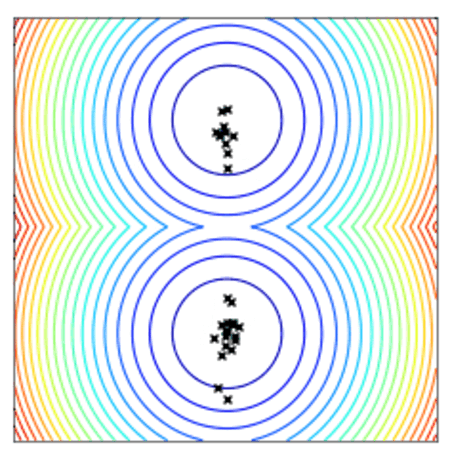
使用两点DE的点群收敛到最小值。
文档
查看我们的文档!它仍在不断完善中,所以请随时提交问题和/或拉取请求(PRs)来更新和使其更清晰! 我们数据的最新版本和我们PDF报告的最新版本。
引用
@misc{nevergrad,
author = {J. Rapin and O. Teytaud},
title = {{Nevergrad - A gradient-free optimization platform}},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://GitHub.com/FacebookResearch/Nevergrad}},
}











