
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文SIGIR2020_PeterRec
用于用户建模和推荐的序列行为参数高效迁移
文章链接: https://zhuanlan.zhihu.com/p/437671278
https://zhuanlan.zhihu.com/p/139048117
https://blog.csdn.net/abcdefg90876/article/details/109505669
https://blog.csdn.net/weixin_44259490/article/details/114850970
https://programmersought.com/article/36196143813/
https://zhuanlan.zhihu.com/p/430145630
🤗 新资源: 四个用于评估基础/可迁移/多模态/大语言模型推荐系统的大规模数据集。
-
MicroLens(DeepMind演讲): https://github.com/westlake-repl/MicroLens
-
NineRec(TPAMI): https://github.com/westlake-repl/NineRec
-
Tenrec(NeurIPS): https://github.com/yuangh-x/2022-NIPS-Tenrec
PeterRec Pytorch 代码在这里: https://github.com/yuangh-x/2022-NIPS-Tenrec
如果您在发表的文章中使用了我们的代码或数据集,请引用我们的论文。
@article{yuan2020parameter,
title={Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation},
author={Yuan, Fajie and He, Xiangnan and Karatzoglou, Alexandros and Zhang, Liguang},
journal={Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval},
year={2020}
}
NextItNet pytorch 版本: https://github.com/syiswell/NextItNet-Pytorch
GRec pytorch 版本: https://github.com/hangjunguo/GRec
PeterRec_cau_parallel.py: 使用因果CNN和并行插入的PeterRec
PeterRec_cau_serial.py: 使用因果CNN和串行插入的PeterRec
PeterRec_cau_serial_lambdafm.py: 基于PeterRec_cau_serial.py,使用lambdafm负采样器,并在评估时考虑所有物品而不是仅采样100个物品
PeterRec_noncau_parallel.py: 使用非因果CNN和并行插入的PeterRec
PeterRec_noncau_serial.py: 使用因果CNN和串行插入的PeterRec
NextitNet_TF_Pretrain.py: 通过NextItNet [0]预训练(即因果CNN)
GRec_TF_Pretrain.py: 通过GRec [1]的编码器预训练(即非因果CNN)
演示步骤:
您可以直接运行我们的代码:
第一步:python NextitNet_TF_Pretrain_topk.py (由于在评估阶段输出完整的softmax,NextitNet_TF_Pretrain.py比NextitNet_TF_Pretrain_topk.py慢)
在收敛后(一旦预训练模型保存就可以停止!)
第二步:python PeterRec_cau_serial.py (或 PeterRec_cau_serial_lambdafm.py)
注意,您可以使用两种评估方法,即我们论文中的采样top-N(PeterRec_cau_serial.py)或评估所有物品(PeterRec_cau_serial_lambdafm.py)。请注意,如果您使用PeterRec_cau_serial_lambdafm.py,这意味着您正在优化top-N指标,那么您必须在所有物品中评估预测准确性(如该文件所示),而不是采样指标 —— 因为采样指标与AUC更一致,而不是真正的top-N。但如果您使用BPR或CE损失和随机负采样器,您应该使用采样指标,因为这两种损失与随机采样器直接优化AUC,而不是top-N指标。 有关更多详细信息,我建议您参考最近的一篇论文"On Sampled Metrics for Item Recommendation"。简而言之,采样指标 = AUC,而不是真正的top-N。BPR优化AUC,而lambdafm优化真正的top-N指标(例如,MRR@N,NDCG@N)。如果您使用正确的评估方法,我们论文中的所有见解和结论都将保持一致。
或者
第一步:python GRec_TF_Pretrain_topk.py 第二步:python PeterRec_noncau_parallel.py
运行我们的论文:
用我们的公开数据集替换演示数据集(包括预训练和微调):
您将使用我们论文中的设置重现论文中报告的结果,包括学习率、嵌入大小、扩张、批量大小等。请注意,论文中报告的结果基于相同的超参数设置,以进行公平比较和消融测试。您可以进一步微调超参数以获得最佳性能。例如,我们在微调期间使用0.001作为学习率,您可能发现0.0001表现更好,尽管论文中的所有见解保持一致。 此外,还有一些其他可以改进的地方,比如用于微调的负采样。为简单起见,我们实现了一个非常基本的均匀采样,您可以使用更高级的采样器,如LambdaFM (LambdaFM: Learning Optimal Ranking with Factorization Machines Using Lambda Surrogates),即PeterRec_cau_serial_lambdafm.py。同样,我们的预训练网络(例如NextitNet_TF_Pretrain.py)也在TF中使用了基本的采样函数,如果您在非常大规模的系统中处理数亿个物品,您也可以用自己的采样函数替换它。
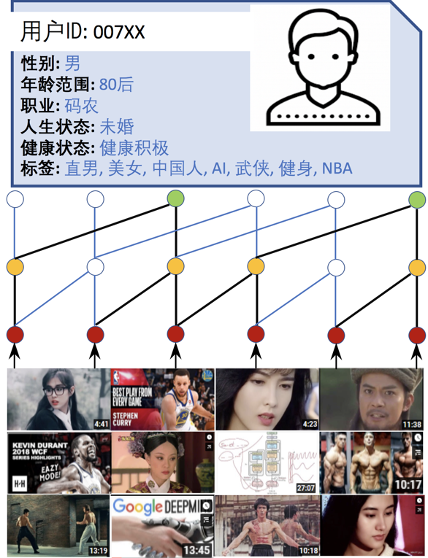
数据集(脱敏)链接
用于预训练、迁移学习和用户表示学习的推荐数据集:
ColdRec2: https://drive.google.com/open?id=1OcvbBJN0jlPTEjE0lvcDfXRkzOjepMXH
ColdRec1: https://drive.google.com/open?id=1N7pMXLh8LkSYDX30-zId1pEMeNDmA7t6
可用于推荐系统预训练、迁移学习、跨域推荐、冷启动推荐、用户表征学习、自监督学习等任务。
请注意,我们提供了论文中使用的原始数据集和几个预处理过的数据集,以便于尝试。也就是说,为了简化,我们为每个任务提供了一个源数据集和一个目标数据集,而在实践中,建议使用一个预训练的源数据集来服务于所有目标任务(确保您的源数据集涵盖目标任务中的所有ID索引)。
实际上,ColdRec2数据集同时包含点击和喜欢操作,我们提供了以下数据集,通过分离点击和喜欢数据,可用于未来的研究。
数据集(脱敏)链接
迁移学习推荐数据集:
ColdRec2(点击和喜欢数据已分离): https://drive.google.com/file/d/1imhHUsivh6oMEtEW-RwVc4OsDqn-xOaP/view?usp=sharing
推荐设置(请注意!)
如果'eval_iter'较小,速度会慢很多,因为它表示多久执行一次评估。可能只需要1或2次迭代就会收敛。
另外,请更改您要评估的批次数量,我们只展示了20个批次作为演示,您可以将其更改为2000或更多 NextitNet_TF_Pretrain_topk.py
parser.add_argument('--eval_iter', type=int, default=10000,
help='每x步采样生成器输出')
parser.add_argument('--save_para_every', type=int, default=10000,
help='每隔多少步保存模型参数')
parser.add_argument('--datapath', type=str, default='Data/Session/coldrec2_pre.csv',
help='数据路径')
model_para = {
'item_size': len(items),
'dilated_channels': 64, # 注意在论文中我们使用256
'dilations': [1,4,1,4,1,4,1,4,], # 注意1 4表示1 2 4 8
'kernel_size': 3,
'learning_rate':0.001,
'batch_size':32,# 你可以尝试32、64、128、256等
'iterations':5, #如果测试集性能不再变化,你可以停止预训练。可能不需要5次迭代
'is_negsample':True #False表示无负采样
}
PeterRec设置(例如,PeterRec_cau_serial.py/PeterRec_cau_serial_lambdafm):
parser.add_argument('--eval_iter', type=int, default=500,
help='每x步采样生成器输出')
parser.add_argument('--save_para_every', type=int, default=500,
help='每隔多少步保存模型参数')
parser.add_argument('--datapath', type=str, default='Data/Session/coldrec2_fine.csv',
help='数据路径')
model_para = {
'item_size': len(items),
'target_item_size': len(targets),
'dilated_channels': 64,
'cardinality': 1, # 1是ResNet,否则是ResNeXt(性能相似,但速度较慢)
'dilations': [1,4,1,4,1,4,1,4,],
'kernel_size': 3,
'learning_rate':0.0001,
'batch_size':512, #你不能使用batch_size=1,因为后面使用np.squeeze会减少一个维度
'iterations': 20, # 注意这不是默认设置,你应该根据自己的数据集,通过观察测试集的性能来设置
'has_positionalembedding': args.has_positionalembedding
}
环境
- Tensorflow(版本:1.7.0)
- Python 2.7
相关工作:
[1]
@inproceedings{yuan2019simple,
title={A simple convolutional generative network for next item recommendation},
author={Yuan, Fajie and Karatzoglou, Alexandros and Arapakis, Ioannis and Jose, Joemon M and He, Xiangnan},
booktitle={Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining},
pages={582--590},
year={2019}
}
[2]
@inproceedings{yuan2020future,
title={Future Data Helps Training: Modeling Future Contexts for Session-based Recommendation},
author={Yuan, Fajie and He, Xiangnan and Jiang, Haochuan and Guo, Guibing and Xiong, Jian and Xu, Zhezhao and Xiong, Yilin},
booktitle={Proceedings of The Web Conference 2020},
pages={303--313},
year={2020}
}
[3]
@article{sun2020generic,
title={A Generic Network Compression Framework for Sequential Recommender Systems},
author={Sun, Yang and Yuan, Fajie and Yang, Ming and Wei, Guoao and Zhao, Zhou and Liu, Duo},
journal={Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining},
year={2020}
}
[4]
@inproceedings{yuan2021one,
title={One person, one model, one world: Learning continual user representation without forgetting},
author={Yuan, Fajie and Zhang, Guoxiao and Karatzoglou, Alexandros and Jose, Joemon and Kong, Beibei and Li, Yudong},
booktitle={Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages={696--705},
year={2021}
}
招聘
如果你想与Fajie https://fajieyuan.github.io/ 一起工作,请通过电子邮件yuanfajie@westlake.edu.cn联系他。他的实验室目前正在招募访问学生、实习生、研究助理、博士后(中国元:每年450,000-550,000)和研究科学家。如果你想在西湖大学攻读博士学位,也可以联系他。 如果你有合作的想法或论文,请随时通过微信(wuxiangwangyuan)与他交流。他对各种合作持开放态度。 西湖大学原发杰团队长期招聘:推荐系统和生物信息(尤其蛋白质相关)方向,科研助理、博士生、博士后、访问学者、研究员系列。











