
 访问官网
访问官网 Github
Github 论文
论文使用在线强化学习对大型语言模型进行基础训练
本仓库包含了我们论文《使用在线强化学习对大型语言模型进行基础训练》的代码。
您可以在我们的网站上找到更多信息。
我们使用GLAM方法在BabyAI-Text中对大型语言模型的知识进行功能性基础训练:
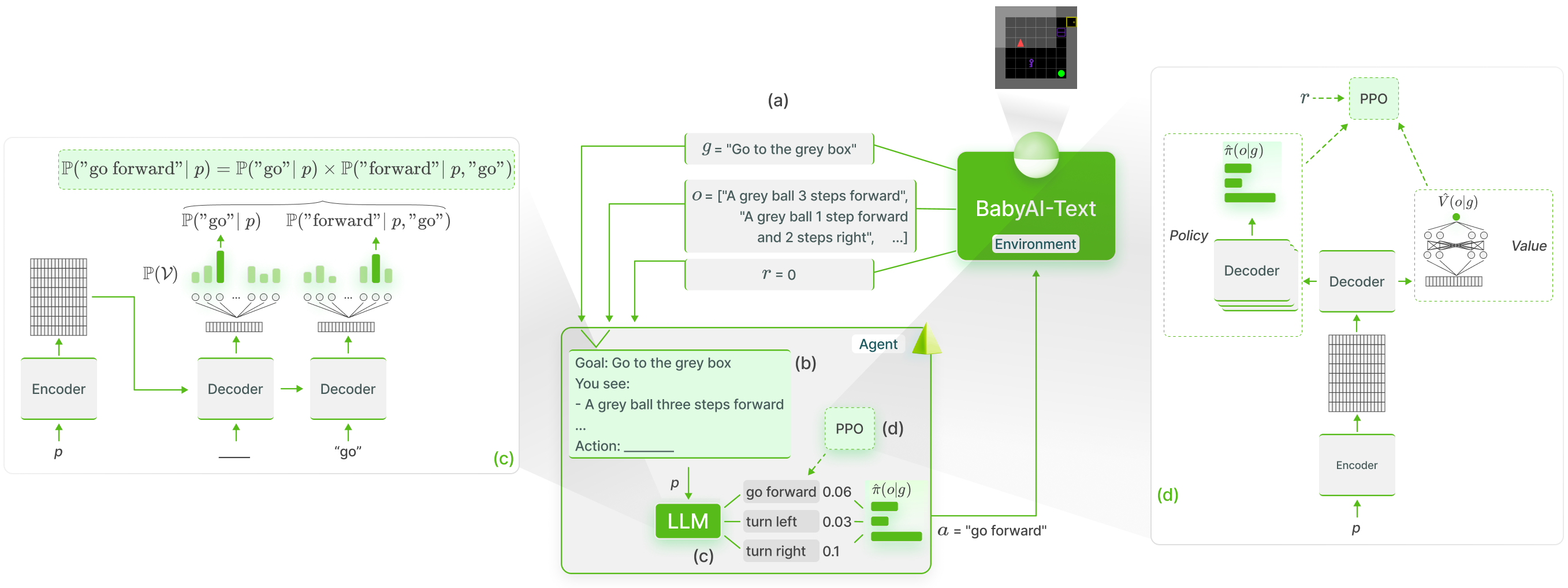
我们发布了我们的BabyAI-Text环境,以及用于进行实验的代码(包括训练智能体和评估其性能)。 我们依赖Lamorel库来使用大型语言模型。
我们的仓库结构如下:
📦 Grounding_LLMs_with_online_RL
┣ 📂 babyai-text -- 我们的BabyAI-Text环境
┣ 📂 experiments -- 我们实验的代码
┃ ┣ 📂 agents -- 所有智能体的实现
┃ ┃ ┣ 📂 bot -- 利用BabyAI的机器人的智能体
┃ ┃ ┣ 📂 random_agent -- 随机均匀行动的智能体
┃ ┃ ┣ 📂 drrn -- 来自此处的DRRN智能体
┃ ┃ ┣ 📂 ppo -- 使用PPO的智能体
┃ ┃ ┃ ┣ 📜 symbolic_ppo_agent.py -- 改编自BabyAI的PPO的SymbolicPPO
┃ ┃ ┃ ┗ 📜 llm_ppo_agent.py -- 我们使用PPO进行基础训练的LLM智能体
┃ ┣ 📂 configs -- 我们实验的Lamorel配置
┃ ┣ 📂 slurm -- 在SLURM集群上启动我们实验的工具脚本
┃ ┣ 📂 campaign -- 用于启动我们实验的SLURM脚本
┃ ┣ 📜 train_language_agent.py -- 使用BabyAI-Text训练智能体(LLMs和DRRN)-> 包含我们对LLMs的PPO损失实现以及LLMs顶部的额外头
┃ ┣ 📜 train_symbolic_ppo.py -- 在BabyAI上训练SymbolicPPO(使用BabyAI-Text的任务)
┃ ┣ 📜 post-training_tests.py -- 训练后智能体的泛化测试
┃ ┣ 📜 test_results.py -- 格式化结果的工具
┃ ┗ 📜 clm_behavioral-cloning.py -- 使用轨迹对LLM进行行为克隆的代码
安装步骤
- 创建conda环境
conda create -n dlp python=3.10.8; conda activate dlp
- 安装PyTorch
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
- 安装我们包所需的包
pip install -r requirements.txt
-
安装BabyAI-Text:请参阅
babyai-text包中的安装详情 -
安装Lamorel
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
启动
请使用Lamorel和我们的配置。 您可以在campaign中找到我们训练脚本的示例。
训练语言模型
要在BabyAI-Text环境上训练语言模型,必须使用train_language_agent.py文件。
这个脚本(通过Lamorel启动)使用以下配置项:
rl_script_args:
seed: 1
number_envs: 2 # 要启动的并行环境数量(步骤将同步,即一次步骤调用将返回number_envs个观察结果)
num_steps: 1000 # 总训练步数
max_episode_steps: 3 # 单个回合的最大步数
frames_per_proc: 40 # 执行一次PPO更新所收集的转换数量将是frames_per_proc*number_envs
discount: 0.99 # PPO中使用的折扣因子
lr: 1e-6 # 用于微调LLM的学习率
beta1: 0.9 # PPO的超参数
beta2: 0.999 # PPO的超参数
gae_lambda: 0.99 # PPO的超参数
entropy_coef: 0.01 # PPO的超参数
value_loss_coef: 0.5 # PPO的超参数
max_grad_norm: 0.5 # 更新LLM参数时的最大梯度范数
adam_eps: 1e-5 # Adam的超参数
clip_eps: 0.2 # PPO损失裁剪中使用的epsilon值
epochs: 4 # 对每组收集的轨迹执行的PPO轮数
batch_size: 16 # 小批量大小
action_space: ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # 智能体可执行的动作
saving_path_logs: ??? # 存储日志的位置
name_experiment: 'llm_mtrl' # 用于日志记录
name_model: 'T5small' # 用于日志记录
saving_path_model: ??? # 存储微调模型的位置
name_environment: 'BabyAI-MixedTestLocal-v0' # BabiAI-Text的环境
load_embedding: true # 是否应加载训练好的嵌入层(当lm_args.pretrained=False时有用)。将此项和use_action_heads都设为True(lm_args.pretrained=False)会创建我们的NPAE智能体。
use_action_heads: false # 是否应使用动作头而不是评分。将此项和use_action_heads都设为True(lm_args.pretrained=False)会创建我们的NPAE智能体。
template_test: 1 # 使用哪个提示模板来记录动作概率的演变(我们论文的C部分)。选项为[1, 2]。
nbr_obs: 3 # 提示中使用的过去观察数量
关于语言模型本身的配置项,请参见Lamorel。
评估测试回合的表现
要评估智能体(如训练过的LLM、BabyAI的机器人等)在测试任务上的表现,使用post-training_tests.py并设置以下配置项:
rl_script_args:
seed: 1
number_envs: 2 # 要启动的并行环境数量(步骤将同步,即一次步骤调用将返回number_envs个观察结果)
max_episode_steps: 3 # 单个回合的最大步数
action_space: ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # 智能体可执行的动作
saving_path_logs: ??? # 存储日志的位置
name_experiment: 'llm_mtrl' # 用于日志记录
name_model: 'T5small' # 用于日志记录
saving_path_model: ??? # 存储微调模型的位置
name_environment: 'BabyAI-MixedTestLocal-v0' # BabiAI-Text的环境
load_embedding: true # 是否应加载训练好的嵌入层(当lm_args.pretrained=False时有用)。将此项和use_action_heads都设为True(lm_args.pretrained=False)会创建我们的NPAE智能体。
use_action_heads: false # 是否应使用动作头而不是评分。将此项和use_action_heads都设为True(lm_args.pretrained=False)会创建我们的NPAE智能体。
nbr_obs: 3 # 提示中使用的过去观察数量
number_episodes: 10 # 测试回合数
language: 'english' # 用于执行法语实验(H4部分)
zero_shot: true # 是否应使用零样本LLM(即未经微调的)
modified_action_space: false # 是否应使用修改过的动作空间(例如,与训练时看到的不同)
new_action_space: #["rotate_left","rotate_right","move_ahead","take","release","switch"] # 修改后的动作空间
im_learning: false # 是否应使用通过行为克隆产生的LLM
im_path: "" # 通过行为克隆学习的LLM的路径
bot: false # 是否应使用BabyAI的机器人智能体











