
 访问官网
访问官网 Github
Github 文档
文档 论文
论文KoGPT2-微调





我们使用了SKT-AI预训练的约20GB韩语数据的KoGPT2模型。首先,为了进行歌词创作,我们对版权已过期的精选歌词数据、小说、文章等进行了按数据类型不同权重的微调。此外,我们还接收了音乐流派,可以查看不同音乐流派的歌词学习结果。
在Colab中,为了顺利进行学习,我们将Google Drive与Dropbox连接起来。学习的中间结果会从Google Drive转移到Dropbox,然后从Google Drive中删除相应结果。相关代码
如果你觉得使用接收CSV格式数据集的Version 2代码进行KoGPT2-FineTuning工作比较困难,可以使用Version 1.1。
在下面,你可以看到学习各种韩语歌词的结果。我们还将进行其他多样化的项目。
示例

数据结构
| 权重 | 流派 | 歌词 |
|---|---|---|
| 1100.0 | 抒情歌 | '你知道我的心\n\n\n只是像傻瓜一样呆呆地站着\n\n\n看着\n\n\n不得不放弃...' |
| ... |
3x200000
微调
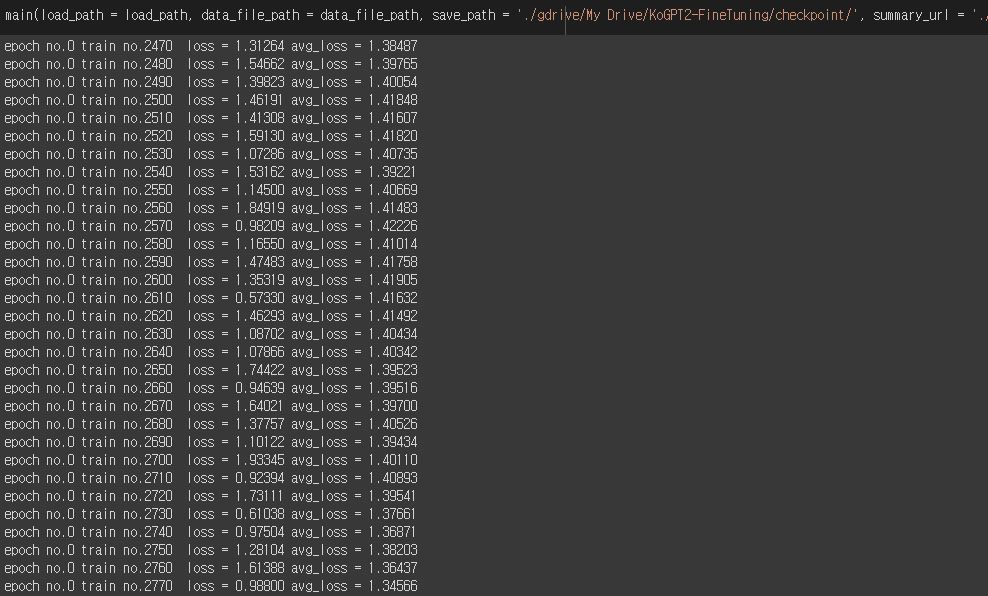
python main.py --epoch=200 --data_file_path=./dataset/lyrics_dataset.csv --save_path=./checkpoint/ --load_path=./checkpoint/genre/KoGPT2_checkpoint_296000.tar --batch_size=1
解析器
parser.add_argument('--epoch', type=int, default=200,
help="通过epoch来调整学习范围。")
parser.add_argument('--save_path', type=str, default='./checkpoint/',
help="保存学习结果的路径。")
parser.add_argument('--load_path', type=str, default='./checkpoint/Alls/KoGPT2_checkpoint_296000.tar',
help="加载已学习结果的路径。")
parser.add_argument('--samples', type=str, default="samples/",
help="保存生成结果的路径。")
parser.add_argument('--data_file_path', type=str, default='dataset/lyrics_dataset.txt',
help="加载学习数据的路径。")
parser.add_argument('--batch_size', type=int, default=8,
help="指定batch_size。")
使用Colab
你可以使用Colab运行微调代码。
防止运行时断开连接
function ClickConnect() {
// 未能分配后端。
// 无法使用带GPU的后端。是否要使用不带加速器的运行时?
// 找到取消按钮并点击
var buttons = document.querySelectorAll("colab-dialog.yes-no-dialog paper-button#cancel");
buttons.forEach(function(btn) {
btn.click();
});
console.log("每1分钟重新连接");
document.querySelector("#top-toolbar > colab-connect-button").click();
}
setInterval(ClickConnect,1000*60);
每10分钟清空屏幕
function CleanCurrentOutput(){
var btn = document.querySelector(".output-icon.clear_outputs_enabled.output-icon-selected[title$='当前正在运行...'] iron-icon[command=clear-focused-or-selected-outputs]");
if(btn) {
console.log("每10分钟清空输出");
btn.click();
}
}
setInterval(CleanCurrentOutput,1000*60*10);
GPU内存检查
nvidia-smi.exe
生成器
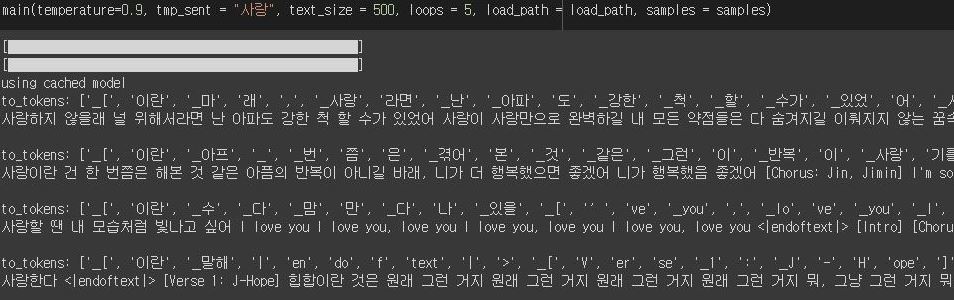
python generator.py --temperature=1.0 --text_size=1000 --tmp_sent=""
无抄袭
python generator.py --temperature=5.0 --text_size=500 --tmp_sent=""
解析器
parser.add_argument('--temperature', type=float, default=0.7,
help="通过temperature调节文本的创造性。")
parser.add_argument('--top_p', type=float, default=0.9,
help="通过top_p调节文本的表现范围。")
parser.add_argument('--top_k', type=int, default=40,
help="通过top_k调节文本的表现范围。")
parser.add_argument('--text_size', type=int, default=250,
help="调整输出文本的长度。")
parser.add_argument('--loops', type=int, default=-1,
help="指定重复生成文本的次数。-1表示无限重复。")
parser.add_argument('--tmp_sent', type=str, default="爱情",
help="文本的起始句。")
parser.add_argument('--load_path', type=str, default="./checkpoint/Alls/KoGPT2_checkpoint_296000.tar",
help="保存训练结果的路径。")
使用Colab
您可以使用Colab运行生成器。
tensorboard
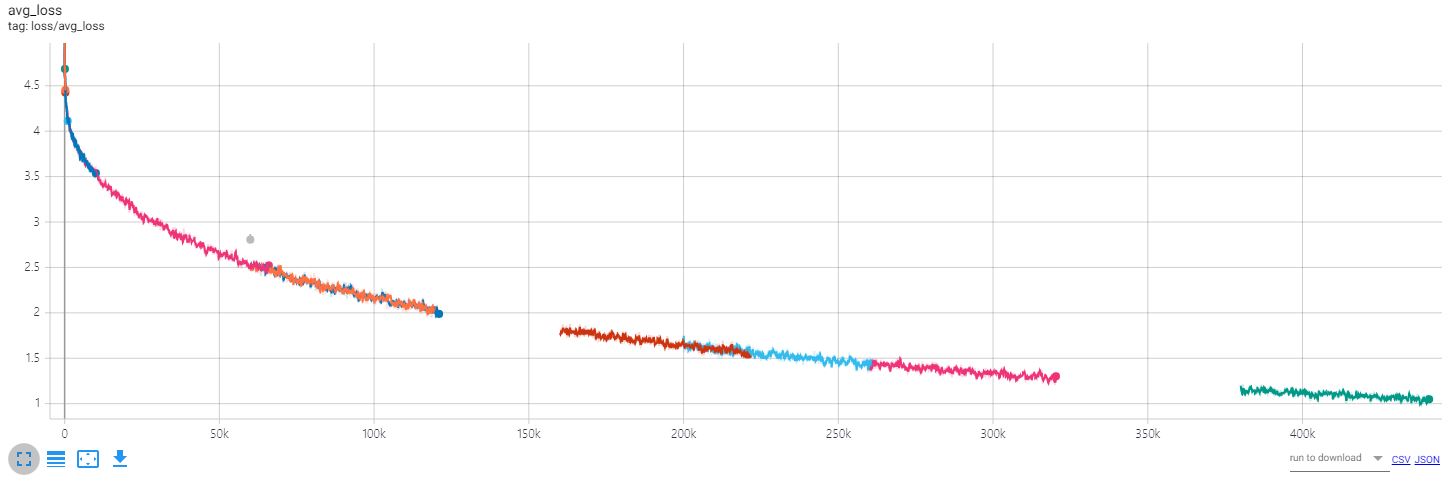
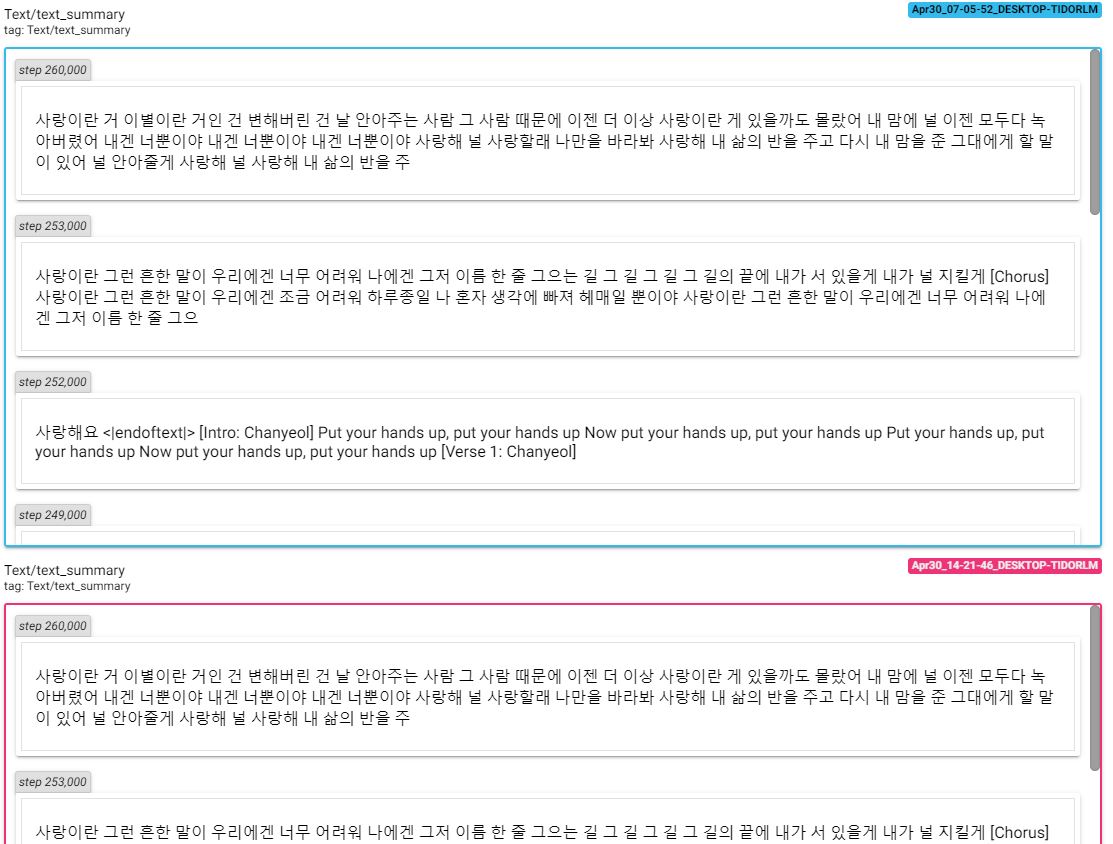
为了查看训练过程中的变化,可以通过tensorboard查看损失和文本。
tensorboard --logdir=runs
损失
文本
引用
@misc{KoGPT2-FineTuning,
author = {gyung},
title = {KoGPT2-FineTuning},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/gyunggyung/KoGPT2-FineTuning}},
}
输出
详细的输出结果可以在samples中查看。关于训练的信息可以在相关文章中查看。
参考
https://github.com/openai/gpt-2
https://github.com/nshepperd/gpt-2
https://github.com/SKT-AI/KoGPT2
https://github.com/asyml/texar-pytorch/tree/master/examples/gpt-2
https://github.com/graykode/gpt-2-Pytorch
https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
https://github.com/shbictai/narrativeKoGPT2
https://github.com/ssut/py-hanspell
https://github.com/likejazz/korean-sentence-splitter











