
 访问官网
访问官网 Github
Github Huggingface
HuggingfaceSNAC 🍿
多尺度神经音频编解码器(SNAC)以低比特率将音频压缩为离散代码。
| 🎸 音乐样本 | 🗣️ 语音样本 |
|---|---|
🎧 更多音频样本可在 https://hubertsiuzdak.github.io/snac/ 获取
概述
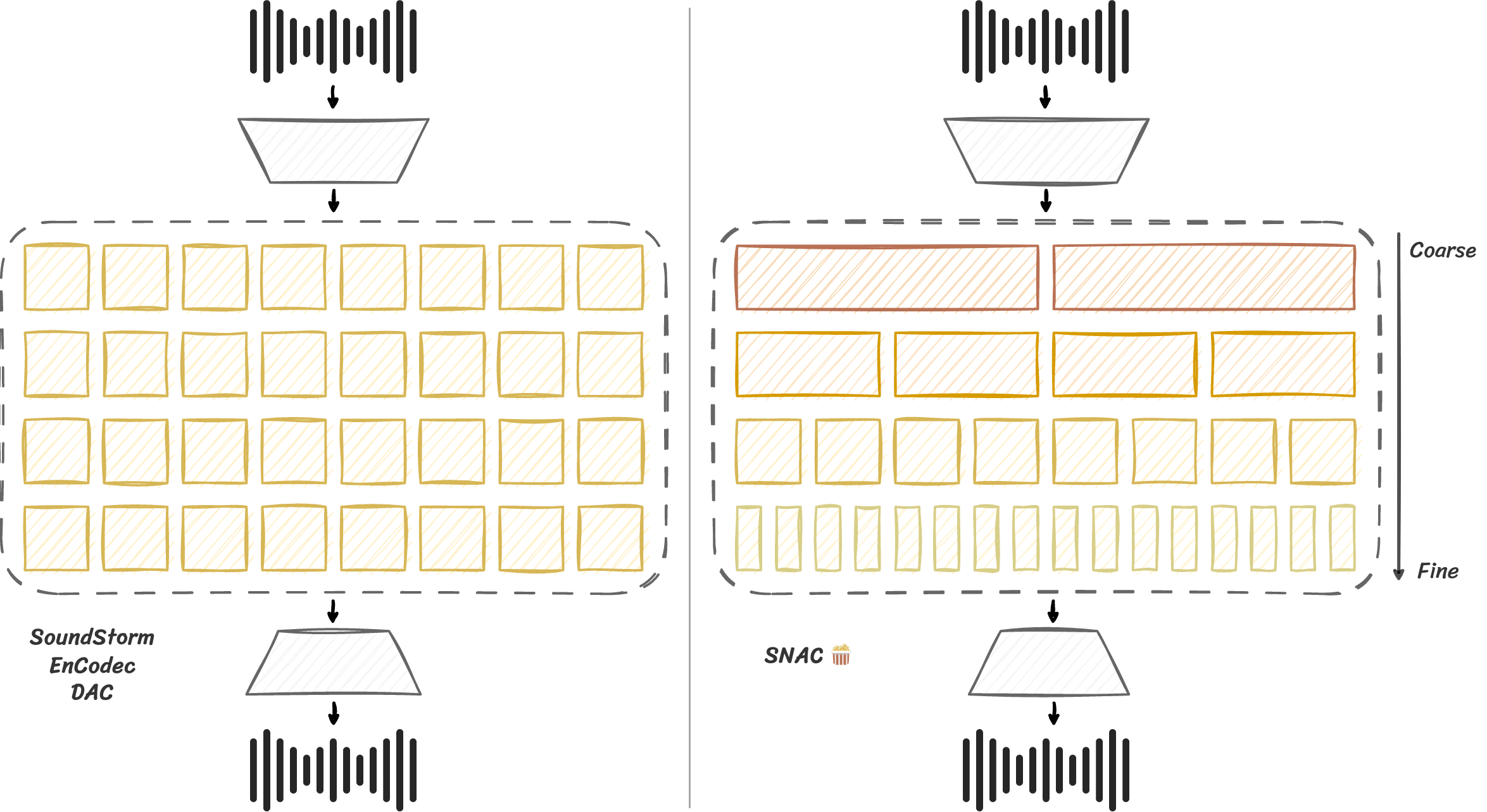
SNAC 类似于 SoundStream、EnCodec 和 DAC,将音频编码为分层标记(见左图)。然而,SNAC 引入了一个简单的变化,即粗糙标记的采样频率更低,覆盖更长的时间跨度(见右图)。
这不仅可以节省比特率,更重要的是,这对于音频生成的语言建模方法可能非常有用。例如,使用约 10 Hz 的粗糙标记和 2048 的上下文窗口,你可以有效地为约 3 分钟的音频建模一致的结构。
预训练模型
目前,所有模型仅支持单声道音频。
| 模型 | 比特率 | 采样率 | 参数 | 推荐用例 |
|---|---|---|---|---|
| hubertsiuzdak/snac_24khz | 0.98 kbps | 24 kHz | 19.8 M | 🗣️ 语音 |
| hubertsiuzdak/snac_32khz | 1.9 kbps | 32 kHz | 54.5 M | 🎸 音乐 / 音效 |
| hubertsiuzdak/snac_44khz | 2.6 kbps | 44 kHz | 54.5 M | 🎸 音乐 / 音效 |
使用方法
安装方法:
pip install snac
在 Python 中使用 SNAC 编码(和解码)音频的代码如下:
import torch
from snac import SNAC
model = SNAC.from_pretrained("hubertsiuzdak/snac_32khz").eval().cuda()
audio = torch.randn(1, 1, 32000).cuda() # 实际音频的占位符,形状为 (B, 1, T)
with torch.inference_mode():
codes = model.encode(audio)
audio_hat = model.decode(codes)
你也可以在一次调用中进行编码和重构:
with torch.inference_mode():
audio_hat, codes = model(audio)
⚠️ 注意,codes 是一个不同长度标记序列的列表,每个序列对应不同的时间分辨率。
>>> [code.shape[1] for code in codes]
[12, 24, 48, 96]
致谢
模块定义改编自 Descript Audio Codec。











