
 Github
Github Huggingface
Huggingface 文档
文档 论文
论文项目介绍:vitmatte-small-distinctions-646
项目概述
vitmatte-small-distinctions-646是一个基于ViTMatte模型的项目,专注于图像抠图,即精确估计图像中前景物体的任务。该项目最初是在Yao等人发布的论文《ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers》中提出的,并在这个GitHub仓库首次发布。
模型描述
ViTMatte是一种简单的方法,适用于图像的抠图任务。其模型结构由一个视觉Transformer(Vision Transformer, ViT)和一个轻量级的头部组成。ViTMatte通过使用预训练的视觉Transformer来提升图像抠图的效果。
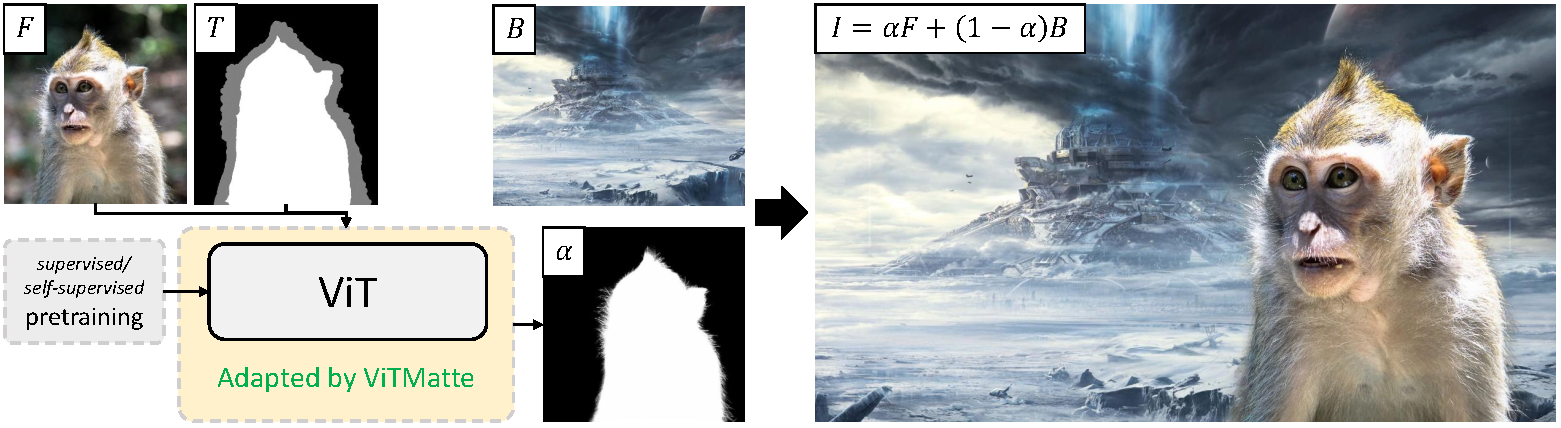
这是一个高级别的概述,取自这篇原始论文。
使用方法与限制
您可以使用这个原始模型进行图像抠图任务。此外,可以访问模型中心查找可能感兴趣的其他微调版模型。
如何使用
有关详细使用说明,请参考文档。
参考文献与引用信息
如果您需要在研究中引用此模型,请使用以下BibTeX条目:
@misc{yao2023vitmatte,
title={ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers},
author={Jingfeng Yao and Xinggang Wang and Shusheng Yang and Baoyuan Wang},
year={2023},
eprint={2305.15272},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
这是对vitmatte-small-distinctions-646项目的详细介绍。它为那些需要进行图像前景识别和抠图的用户提供了一个有效的工具。通过利用预训练的视觉Transformer,ViTMatte为实现高效和精确的图像处理任务开辟了新的途径。










