
Make-It-3D:基于扩散先验从单张图像创建高保真3D内容 (ICCV 2023)










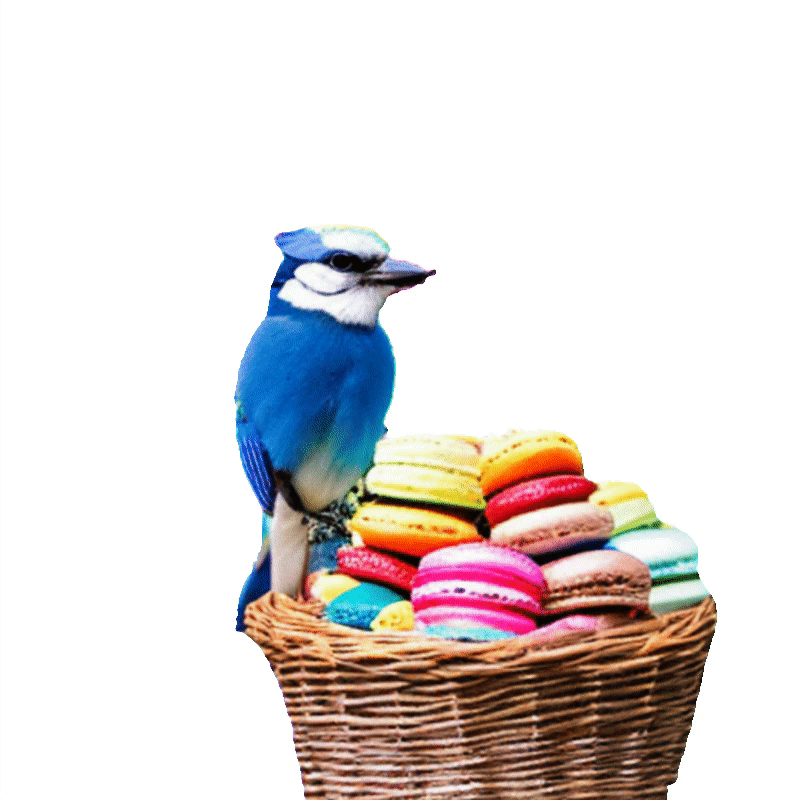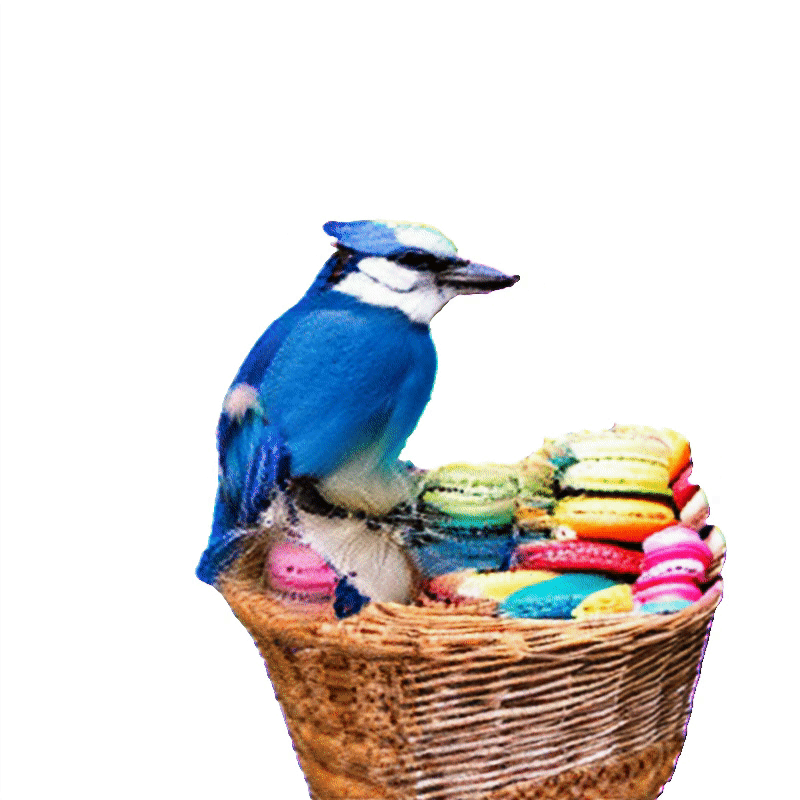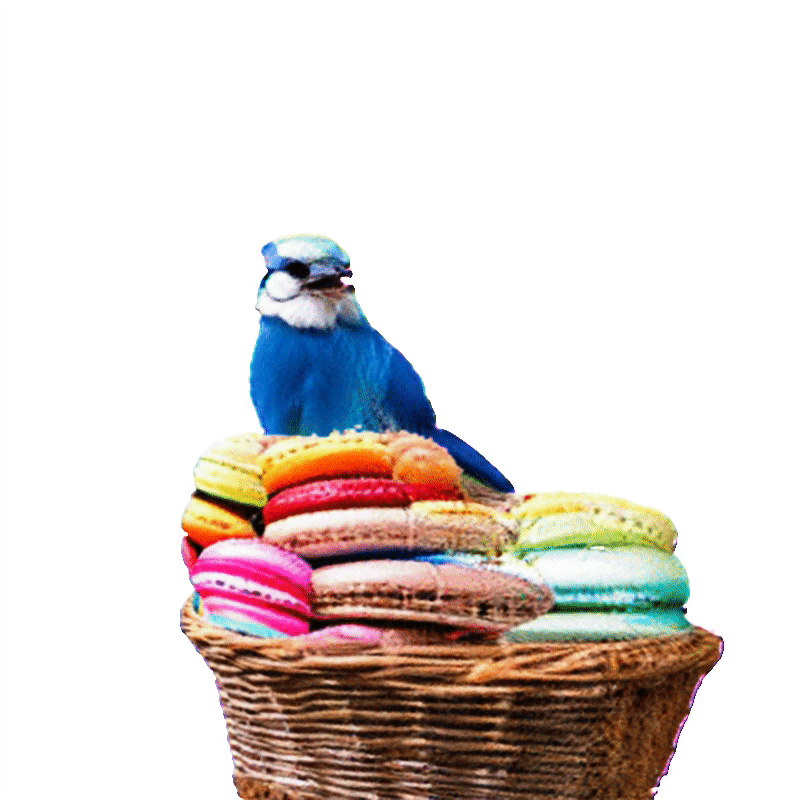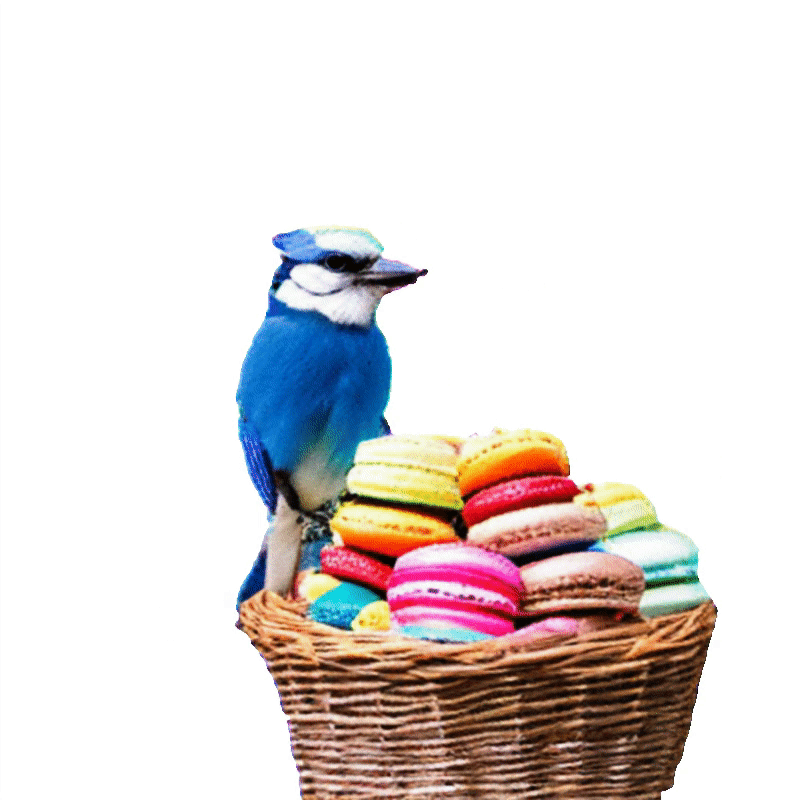
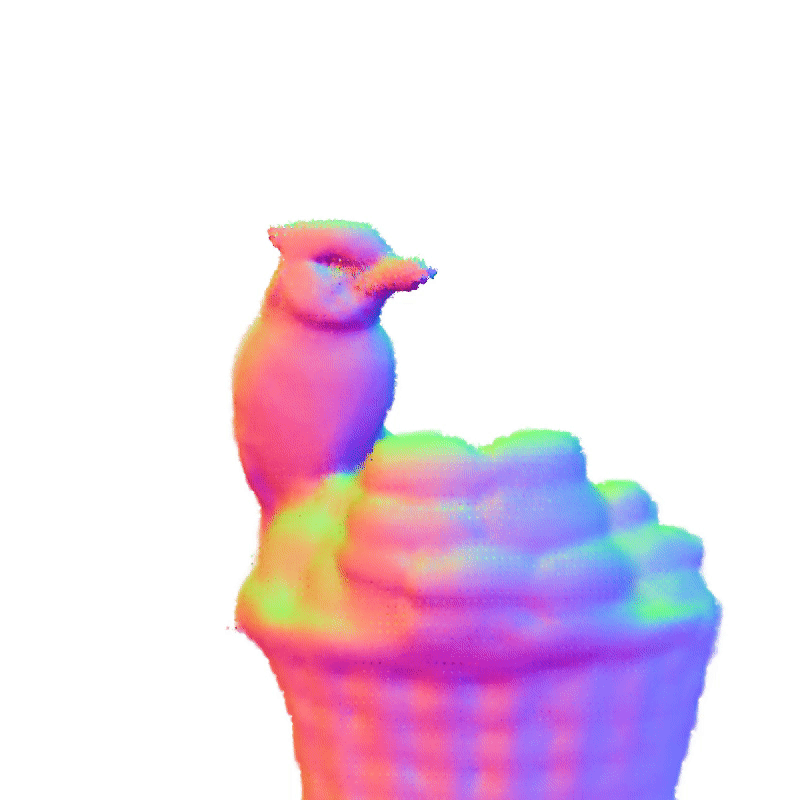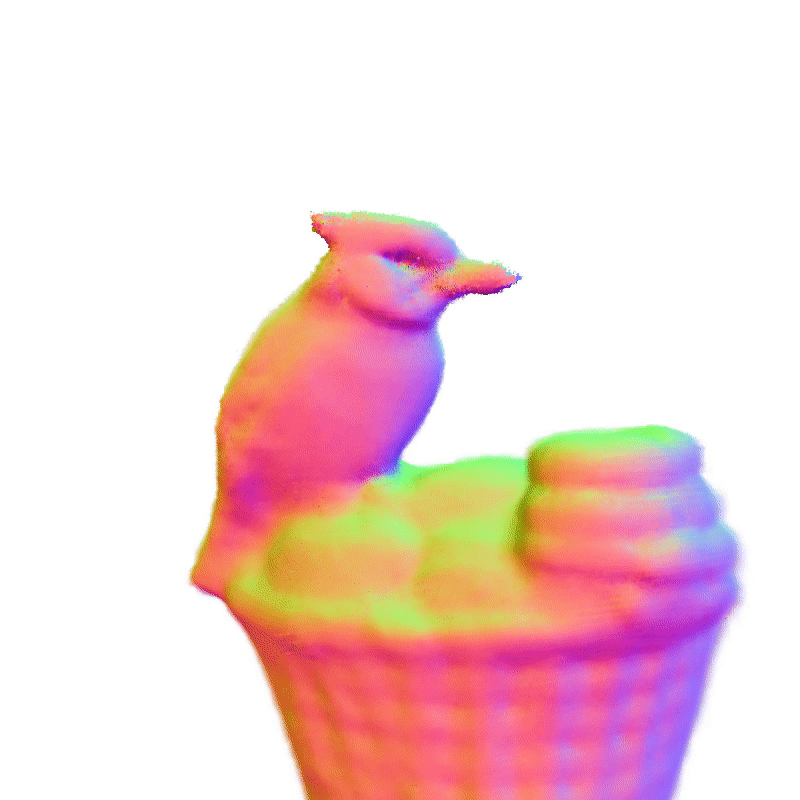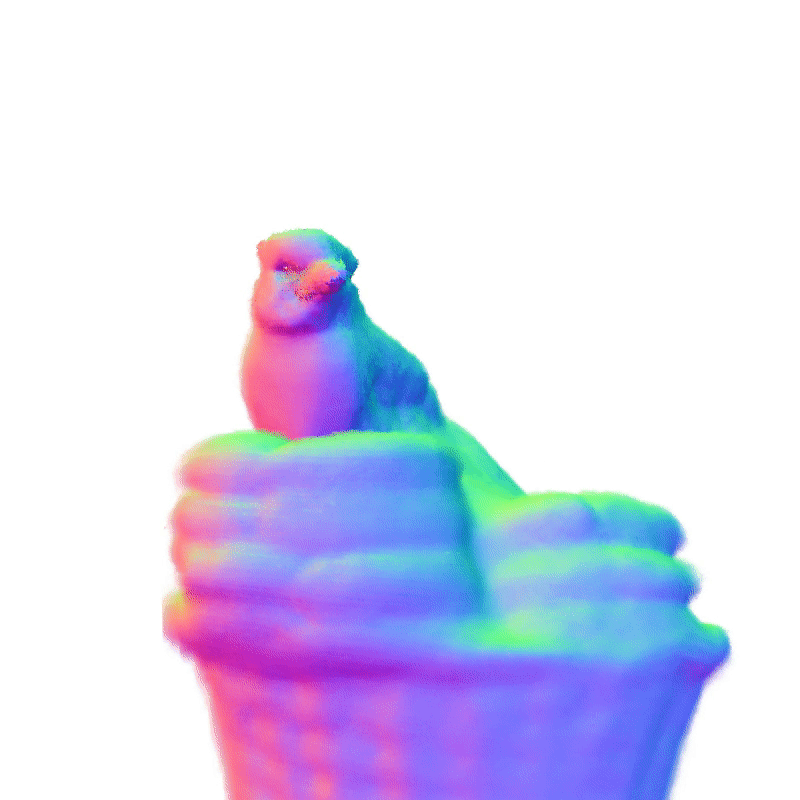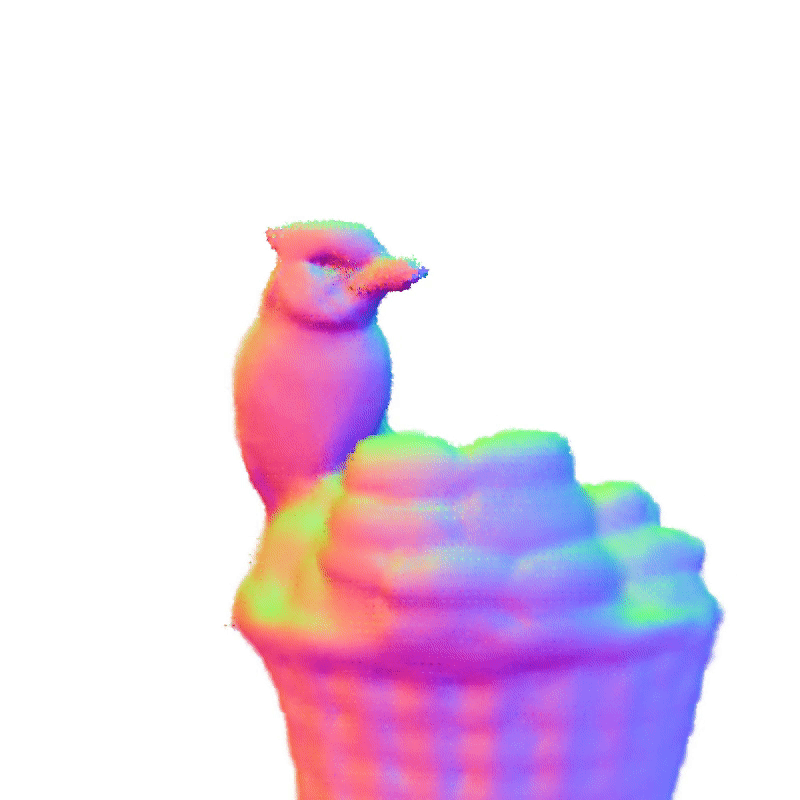
项目页面 | 论文
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, Dong Chen.
摘要
在这项工作中,我们研究了仅从单张图像创建高保真3D内容的问题。这本质上是一个挑战:它基本上涉及估计基础的3D几何,同时还需凭空想象未见的纹理。为了解决这一挑战,我们利用一个训练良好的2D扩散模型的先验知识,作为3D创作的3D感知监督。我们的方法,Make-It-3D,采用了两阶段优化流程:第一阶段通过结合正视图中的参考图像约束和新视图中的扩散先验来优化神经辐射场;第二阶段将粗糙模型转化为具纹理的点云,并借助参考图像中的高质量纹理,在使用扩散先验的同时进一步提升现实感。大量实验证明,我们的方法比之前的工作大幅度提高了成绩,带来了真实的重建和令人印象深刻的视觉质量。我们的方法首次实现了从单张图像对所有物体进行高质量3D创作,并且能够支持多种应用,如文本到3D创作和纹理编辑。
新闻!
- :loudspeaker: Make-It-3D的Jittor版本现已发布在Make-it-3D-Jittor。欢迎试用!!
待办事项
- 发布粗糙阶段训练代码
- 发布所有训练代码(粗糙阶段 + 精细阶段)
- 发布论文中所有结果的测试 alpha 数据
360°几何演示





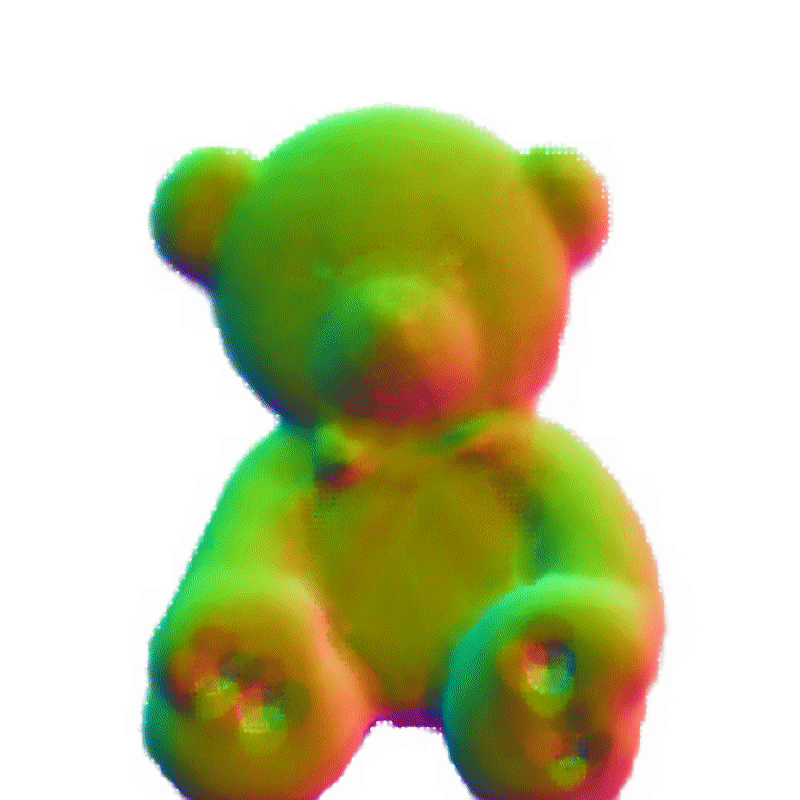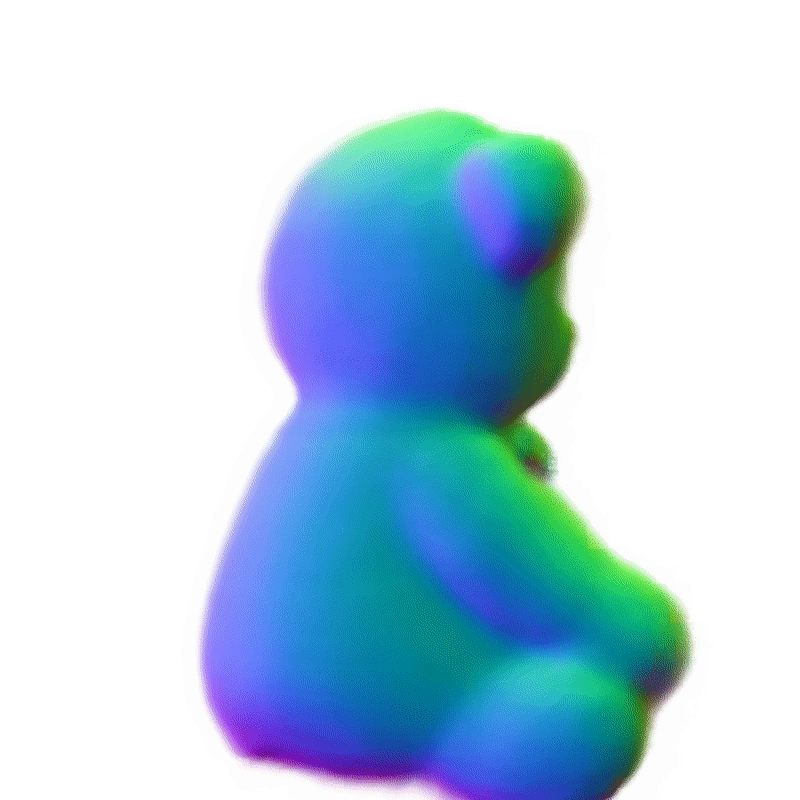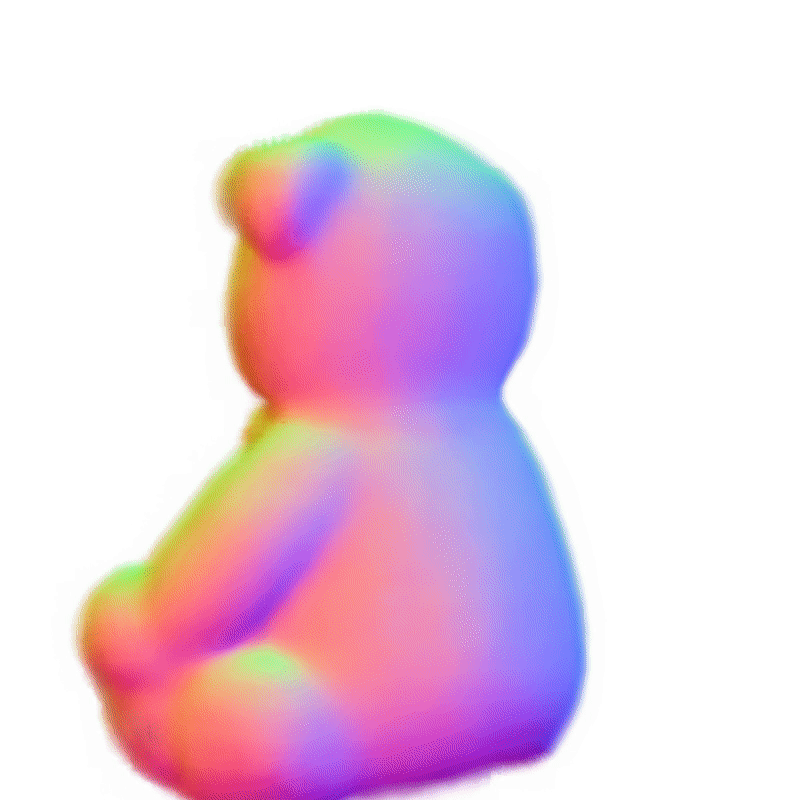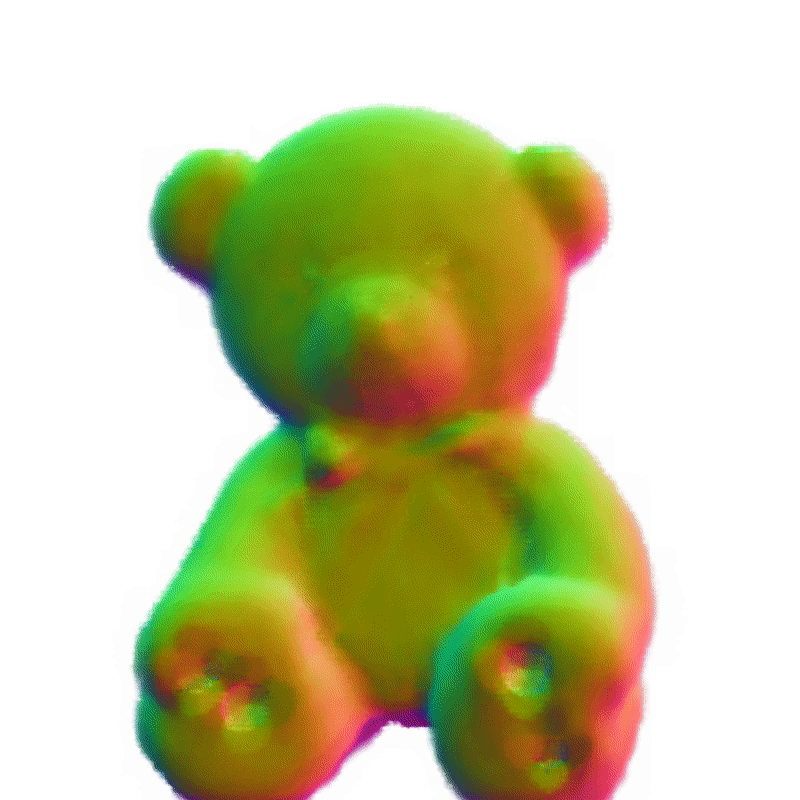
SAM + Make-It-3D




安装
通过 pip 安装:
pip install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio===0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
pip install git+https://github.com/openai/CLIP.git
pip install git+https://github.com/huggingface/diffusers.git
pip install git+https://github.com/huggingface/huggingface_hub.git
pip install git+https://github.com/facebookresearch/pytorch3d.git
pip install git+https://github.com/S-aiueo32/contextual_loss_pytorch.git
其他依赖:
pip install -r requirements.txt
pip install ./raymarching
训练要求
- DPT。我们使用一个即用型单视图深度估计器DPT来预测参考图像的深度。
下载预训练模型 dpt_hybrid,并将其放置在git clone https://github.com/isl-org/DPT.git mkdir dpt_weightsdpt_weights文件夹中。 - SAM。我们使用Segment-anything模型来获得前景物体的遮罩。
- BLIP2。我们使用BLIP2生成描述。你也可以通过
--text "{TEXT}"来修改条件文本,从而大大减少时间。 - Stable Diffusion。我们使用预训练2D Stable Diffusion 2.0模型的扩散先验。开始时,你可能需要一个 token 来访问模型,或者使用
huggingface-cli login命令。
训练
粗糙阶段
我们使用渐进训练策略生成完整的360° 3D几何。运行命令并修改工作区名称 NAME 和参考图像的路径 IMGPATH。我们首先在前视图下优化场景。
python main.py --workspace ${NAME} --ref_path "${IMGPATH}" --phi_range 135 225 --iters 2000
然后我们将视角采样扩展到完整的360°。如果你需要一个 "后视图" 提示,你可以使用 --need_back 命令。
python main.py --workspace ${NAME} --ref_path "${IMGPATH}" --phi_range 0 360 --albedo_iters 3500 --iters 5000 --final
如果你遇到 长几何 问题,你可以尝试增加参考的视场角并调整相应的设置。例如:
python main.py --workspace ${NAME} --ref_path "${IMGPATH}" --phi_range 135 225 --iters 2000 --fov 60 --fovy_range 50 70 --blob_radius 0.2
精细阶段
经过粗糙阶段的训练,现在你可以轻松地使用 --refine 命令进行精细阶段的训练。我们在前视图下优化场景。
python main.py --workspace ${NAME} --ref_path "${IMGPATH}" --phi_range 135 225 --refine
你可以使用 --refine_iters 命令修改训练迭代次数。
python main.py --workspace ${NAME} --ref_path "${IMGPATH}" --phi_range 135 225 --refine_iters 3000 --refine
注意: 我们在精细阶段额外使用了 上下文损失,我们发现这有助于锐化纹理。你可能需要在训练前安装 contextual_loss_pytorch。
pip install git+https://github.com/S-aiueo32/contextual_loss_pytorch.git
重要说明
从一般类别的单张图像生成3D几何和新视图是一项具有挑战性的任务。尽管我们的方法在创建单个物体居中的大多数图像方面表现出强大的能力,但在复杂情况下仍可能遇到难以重建坚实几何的问题。如果你遇到任何问题,请随时联系我们。
引用
如果你认为这段代码对你的研究有帮助,请引用:
@InProceedings{Tang_2023_ICCV,
author = {Tang, Junshu and Wang, Tengfei and Zhang, Bo and Zhang, Ting and Yi, Ran and Ma, Lizhuang and Chen, Dong},
title = {Make-It-3D: High-fidelity 3D Creation from A Single Image with Diffusion Prior},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {22819-22829}
}
致谢
这段代码大量借鉴了 Stable-Dreamfusion。











