
AUTOMATIC1111 的 StableDiffusion WebUI 的 text2video 插件
警告:截至 2023-11-21 该插件不再维护。如果你想继续开发/重制它,请通过 Discord 联系我 @kabachuha(你也可以在 camenduru 的服务器的 text2video 频道 找到我),我们会一起解决。
从 2023-11-21 开始由 Deforum-art 维护
再次由我维护
Auto1111 插件实现了多种 text2video 模型,如 ModelScope 和 VideoCrafter,仅使用 Auto1111 webui 依赖项和可下载的模型(因此无需登录)。
系统要求
ModelScope
显存 6 GB 应该足以在 256x256 的低显存 VAE 模式下在 GPU 上运行(我们已经收到有人在 4gbs 显存的情况下启用 192x192 视频 的报告)。显存 12GB 的 NVIDIA GeForce RTX 2080 Ti 能够处理 24 帧长的 256x256 视频,如果你的显卡支持 Torch2 注意力优化,你可以在同样的 12GB 显存内设置 125 帧(8 秒)长的视频!在同样条件下,250 帧(16 秒)需要 20 GB 显存。
提示词:最佳质量,动漫女孩跳舞
我们非常欢迎任何与该插件相关的帮助,特别是 pull-request。
LoRA 支持
目前支持使用这个 finetune 仓库训练的 LoRA。请按照那里的说明进行训练。 https://github.com/ExponentialML/Text-To-Video-Finetuning#updates
训练完成后,只需将它们放置在 webui 安装定义的默认 LoRA 目录中即可。
VideoCrafter(WIP,需要更多开发者来妥善维护)
在默认设置下,VideoCrafter 运行大约需要 9.2 GB 显存。
主要版本更新
2023-03-27 更新:VAE 设置和“将模型保留在显存中”移至 'ModelScopeTxt2Vid' 下的一般 webui 设置。
2023-03-26 更新:提示词权重实现!(截至 2023-04-05,仅 ModelScope)
2023-04-05 更新:增加 VideoCrafter 支持,将插件重命名为 sd-webui-text2video
2023-04-13 更新:in-framing/in-painting 支持:可以将现有图片动画化,甚至无缝循环视频!
2023-04-15 更新:MEGA-UPDATE:Torch2/xformers 优化,可以在 12GB 显存上制作 125 帧长视频。如果选中 keep_pipe_in_vram,则不会离线 CPU。
2023-04-16 更新:WebAPI 可用!
2023-07-02 更新:其他采样器,模型热切换。
测试示例:
ModelScope
提示词:电影风格爆炸,by greg rutkowski
提示词:非常吸引人的动漫女孩滑冰,by makoto shinkai,电影灯光
'续接'现有图片
提示词:最佳质量,宇航员狗
提示词:爆炸
视频补帧和循环
提示词:核爆炸
提示词:最佳质量,很多奶酪
VideoCrafter
提示词:动漫 1 女孩,灵梦,东方
获取权重的方法
ModelScope
从 原始 HuggingFace 仓库下载以下文件。或者,下载半精度 fp16 剔除权重(更小,加载时占用较少的显存):
- VQGAN_autoencoder.pth
- configuration.json
- open_clip_pytorch_model.bin
- text2video_pytorch_model.pth
并将它们放在 stable-diffusion-webui/models/ModelScope/t2v 目录中。如果缺少这些文件夹,请自行创建。
VideoCrafter
通过 此链接下载预训练 T2V 模型或下载 剔除的半精度权重,并将 model.ckpt 放在 models/VideoCrafter/model.ckpt 目录中。
细调模型及其使用方法
感谢 https://github.com/ExponentialML/Text-To-Video-Finetuning,你可以细调你的模型!
要在这里利用细调模型,请使用 此脚本,该脚本将转换该仓库输出的 Diffusers 格式模型为原始权重格式。
突出的细调模型
ZeroScope v2
由 @cerspense 在高质量的 YouTube 视频上训练。下载文件夹中名为 zs2_XL 的文件 cerspense/zeroscope_v2_XL 然后从 任何其他 ModelScope 模型 中添加缺少的 VQGAN_autoencoder.pth 和 configuration.json。
Potat1
Potat1 是一个基于 ModelScope 的模型,由 @camenduru 在 2197 个分辨率为 1024x576 的剪辑上训练,这使它成为第一个开源的高分辨率 text2video 模型。
要下载此插件的即插即用权重,请使用此链接:https://huggingface.co/kabachuha/potat1-with-text-encoder-original-format。
Animov-0.1
由 strangeman3107 提供的 Animov-0.1。该模型的转换权重位于 这里。
截图
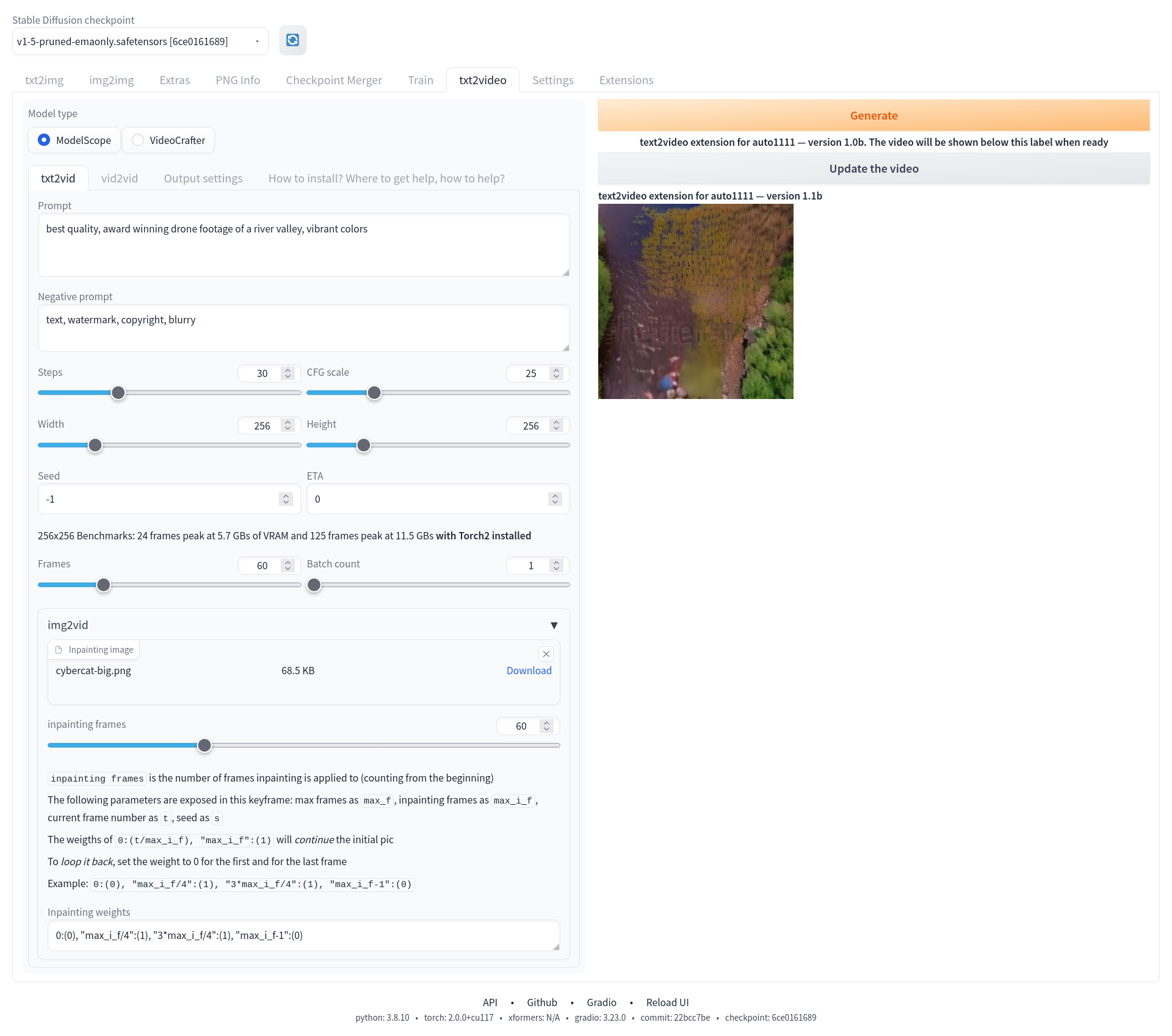
txt2vid 和 img2vid
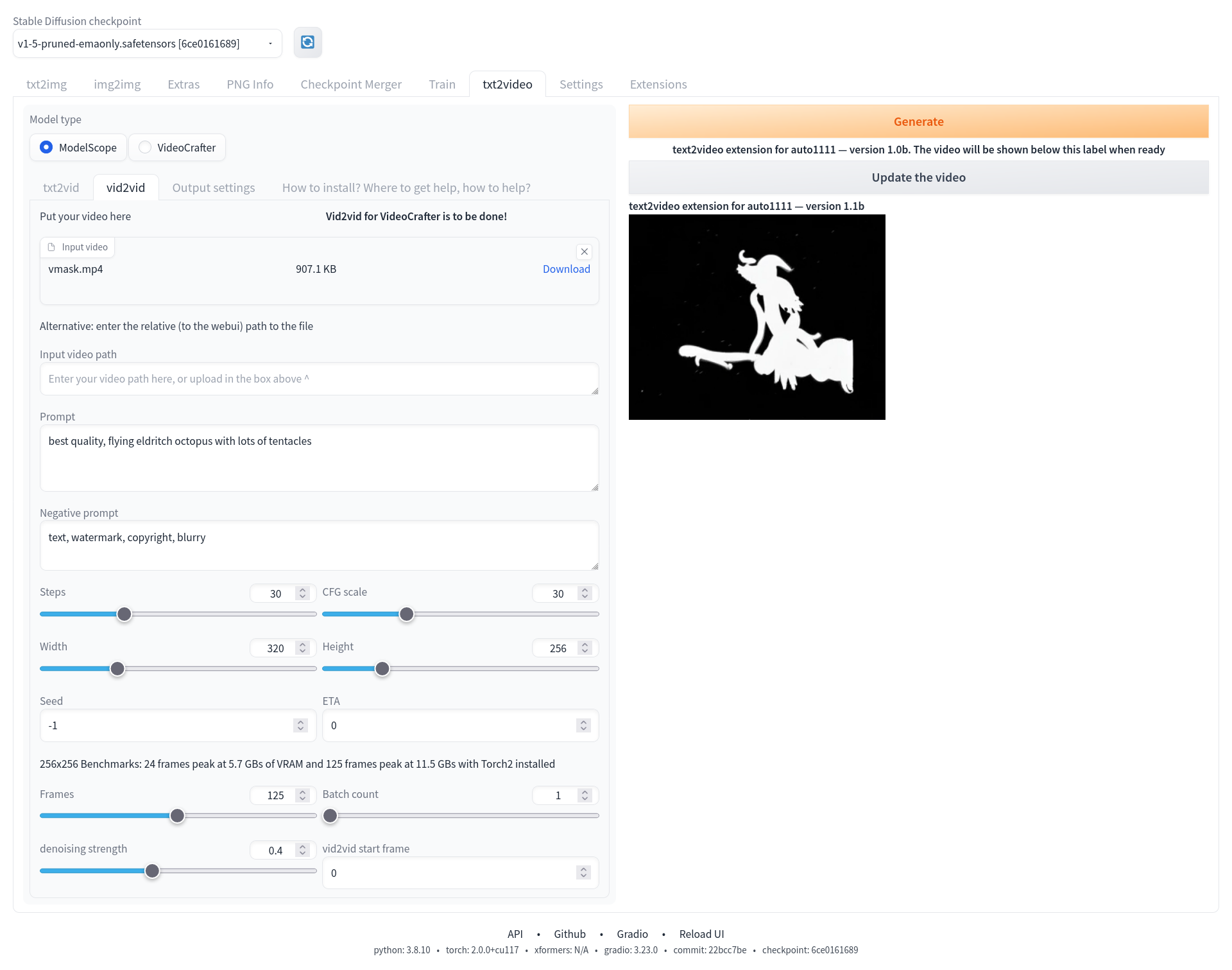
vid2vid
开发资源
ModelScope
HuggingFace 空间:
https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
来自 ModelScope 的 PyTorch 实现模型:
https://github.com/modelscope/modelscope/tree/master/modelscope/models/multi_modal/video_synthesis
开发者提供的 Google Colab:
https://colab.research.google.com/drive/1uW1ZqswkQ9Z9bp5Nbo5z59cAn7I0hE6R?usp=sharing
VideoCrafter
Github:









