
 Github
Github 论文
论文FLASK:基于对齐技能集的细粒度语言模型评估


这是FLASK:基于对齐技能集的细粒度语言模型评估的官方GitHub仓库。
新闻
[2023年7月21日] 初始发布:我们发布了FLASK的第一个版本!也欢迎查看交互式演示。
概述
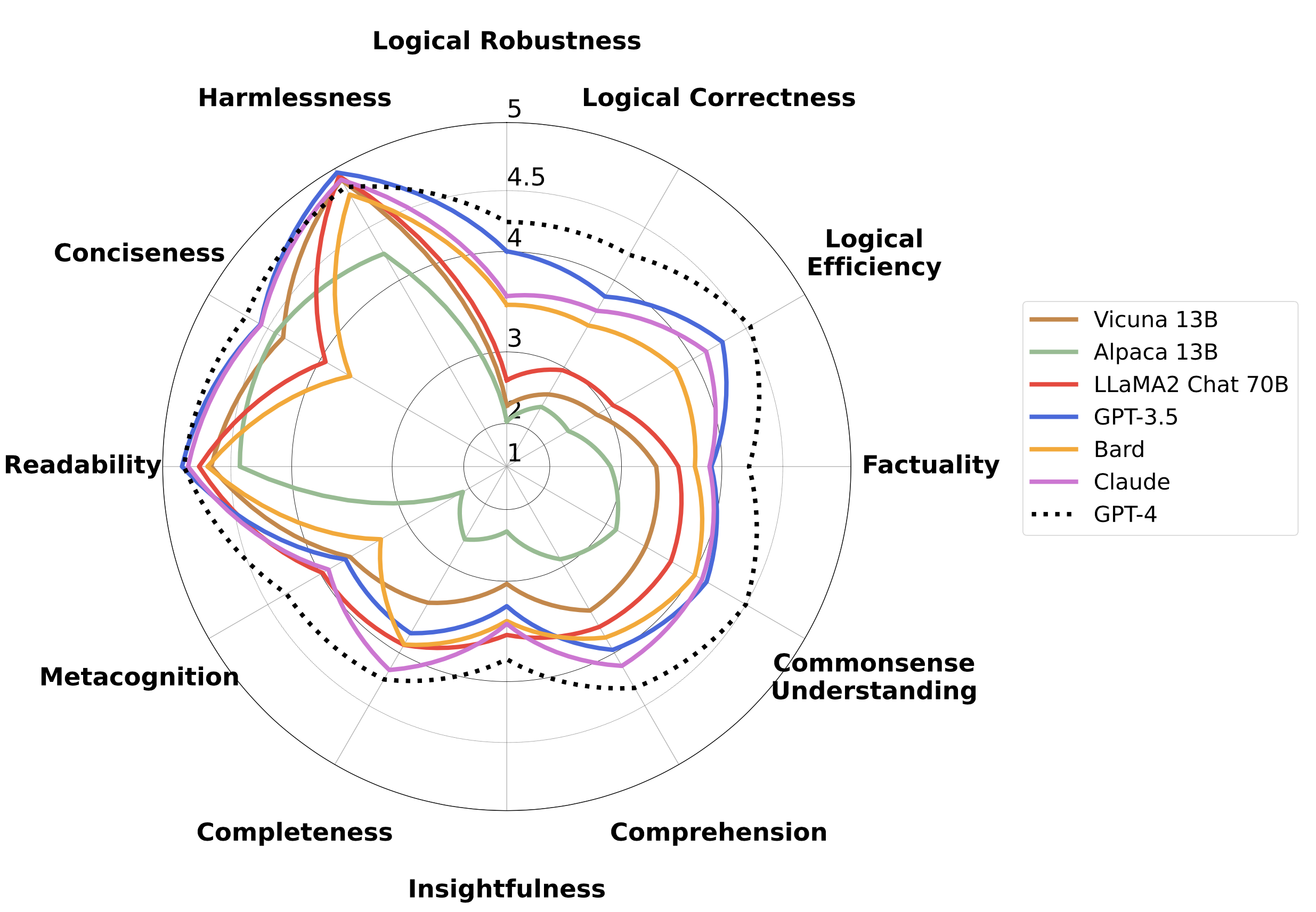
这是FLASK项目的代码仓库,FLASK是一种任务无关的语言模型评估协议,使用细粒度的实例级技能集作为评估指标。
评估
本代码仓库包含FLASK的基于模型实现。关于基于人工评估的指南,请参考论文。
步骤1. OpenAI API信息
由于我们的基于模型的评估基于GPT-4评估,您需要将您的OpenAI API密钥添加到openai_info/api_info.json文件中,在api_keys列表中添加您的密钥。请注意,我们还支持多个密钥以加快评估速度。
步骤2. 模型推理
如果您想在FLASK的评估集上进行模型推理,请运行以下命令:
cd model_output
python inference.py --model-path {模型路径} --model-id {模型ID} --question-file ../input_data/flask_evaluation_raw.jsonl --answer-file {输出目录} --num-gpus {GPU数量}
我们在model_output/outputs目录中提供了各种LLM的推理结果。请注意,对于FLASK-Hard的推理,您只需将--question-file参数替换为../evaluation_set/flask_hard_evaluation.jsonl即可。
步骤3. 模型评估
完成推理后,我们可以使用FLASK评估协议对模型进行评估。运行以下命令进行评估:
cd gpt_review
python gpt4_eval.py -q '../evaluation_set/flask_evaluation.jsonl' -a {答案文件} -o {输出评审文件} -e {输出错误文件}
请注意,错误文件用于存储由于OpenAI API速率限制而失败的实例。如果在推理后创建了错误文件,您可以通过运行以下命令仅重新运行错误实例:
cd gpt_review
python gpt4_eval.py -q {输出错误文件} -a {答案文件} -o {输出评审文件} -e {新输出错误文件}
我们在gpt_review/outputs目录中提供了各种模型的GPT-4评估结果。
步骤4. 汇总和分析
评估完成后,FLASK支持根据技能、领域和难度级别进行细粒度分析。
要分析每种技能的性能,请运行以下命令:
cd gpt_review
python aggregate_skill.py -m {output_review_file}
要分析每个技能在不同难度下的表现,运行以下命令:
cd gpt_review
python aggregate_difficulty_skill.py -m {output_review_file}
要分析每个领域的表现,运行以下命令:
cd gpt_review
python aggregate_domain.py -m {output_review_file}
元数据标注
我们还提供了FLASK自动元数据标注过程的实现。
步骤1. OpenAI API信息
由于我们的基于模型的评估是基于GPT-4评估,你需要将你的OpenAI API密钥添加到openai_info/api_info.json文件中,其中你需要在api_keys列表中添加你的密钥。请注意,我们还支持多个密钥以加快评估速度。
步骤2. 领域标注
对于领域元数据标注,运行以下命令:
cd metadata_annotation/domain
python domain_annotation.py -o {output_domain_annotation} -e {output_domain_annotation_error}
我们修订了维基百科的领域分类,定义了10个不同的领域。请注意,错误文件用于存储由于OpenAI API速率限制而失败的实例。如果在推理后创建了错误文件,你可以只重新运行错误实例。
步骤3. 技能集标注
对于技能集标注,运行以下命令:
cd metadata_annotation/skillset
python skillset_annotation.py -q {output_domain_annotation} -o {output_skill_annotation} -e {output_skill_annotation_error}
我们定义了12种技能用于对LLM进行细粒度评估。
步骤4. 难度标注
对于难度级别标注,运行以下命令:
cd metadata_annotation/difficulty
python difficulty_annotation.py -q {output_skill_annotation} -o {output_difficulty_annotation} -e {output_difficulty_annotation_error}
我们根据领域知识定义了5个不同的难度级别。请注意,在步骤4之后,output_difficulty_annotation文件的每一行应该与evaluation_set/flask_evaluation.jsonl文件的行格式相同。
在线演示
查看交互式演示!
团队成员
Seonghyeon Ye*、Doyoung Kim*、Sungdong Kim、Hyeonbin Hwang、Seungone Kim、Yongrae Jo、James Thorne、Juho Kim和Minjoon Seo。
(*表示贡献相同)
发布
我们发布了FLASK的评估代码。我们还计划在不久的将来发布包含分析代码的FLASK的pip版本。敬请期待!
引用
如果您使用本仓库中的数据或代码,请引用。
@misc{叶2023flask,
标题={FLASK: 基于对齐技能集的细粒度语言模型评估},
作者={叶成铉 and 金度英 and 金成东 and 黄炫彬 and 金承一 and 曹龙来 and James Thorne and 金珠浩 and 徐敏准},
年份={2023},
eprint={2307.10928},
档案前缀={arXiv},
主要类别={cs.CL}
}











