
 访问官网
访问官网 Github
Github 文档
文档 论文
论文

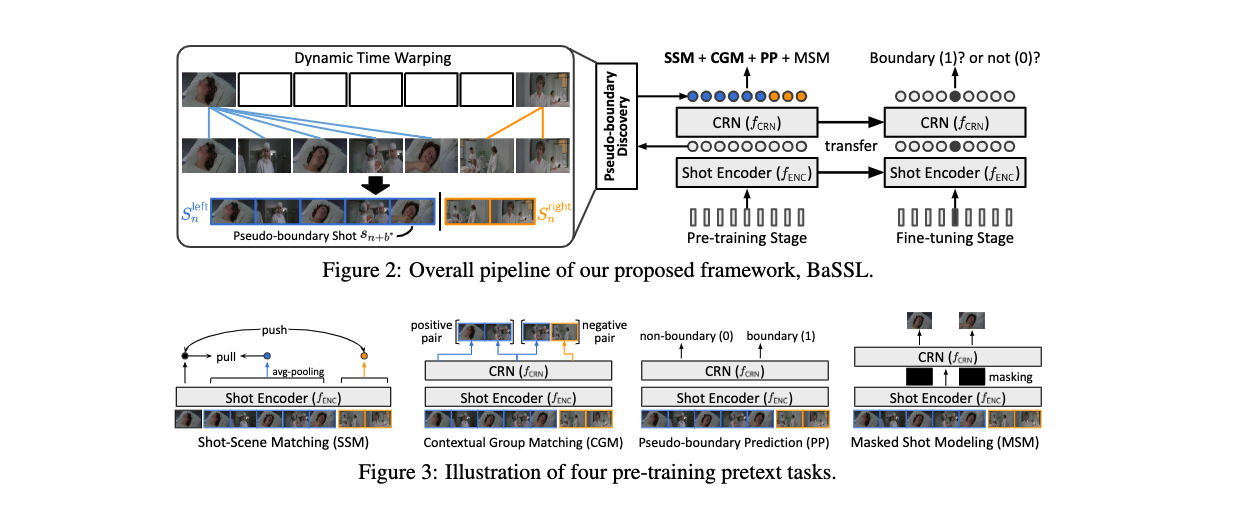
BaSSL
这是**Boundary-aware Self-supervised Learning for Video Scene Segmentation (BaSSL)**的官方PyTorch实现 [arxiv] [modelscope上的演示]
- 该方法是一种自监督学习算法,在预训练阶段学习一个模型来捕捉跨边界的上下文转换。具体来说,该方法利用伪边界并提出了三个新颖的边界感知预训练任务,有效地最大化场景内相似性并最小化场景间相似性,从而在视频场景分割任务中实现更高的性能。
1. 环境设置
我们已在以下环境中测试了实现:
- Python 3.7.7 / PyTorch 1.7.1 / torchvision 0.8.2 / CUDA 11.0 / Ubuntu 18.04
此外,代码基于pytorch-lightning (==1.3.8),所有必要的依赖项都可以通过运行以下命令来安装。
$ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
$ pip install -r requirements.txt
# (可选)安装pillow-simd有时会带来更快的数据加载速度。
$ pip uninstall pillow && CC="cc -mavx2" pip install -U --force-reinstall pillow-simd
2. 准备数据
我们提供了MovieNet-SSeg数据集原始关键帧的数据下载脚本,以及适用于BaSSL的重新格式化的注释文件。
供您参考,我们的脚本将自动下载并解压数据---1) 关键帧(160G),2) 注释(200M)---到<path-to-root>/bassl/data/movienet。
# 下载movienet数据
$ cd <path-to-root>
$ bash script/download_movienet_data.sh
此外,从MovieNet-SSeg谷歌云盘下载注释文件,并将文件夹scene318放入<path-to-root>/bassl/data/movienet。然后,数据文件夹结构将如下所示:
# <path-to-root>/bassl/data
movienet
│─ 240P_frames
│ │─ tt0120885 # 电影ID(或视频ID)
│ │ │─ shot_0000_img_0.jpg
│ │ │─ shot_0000_img_1.jpg
│ │ │─ shot_0000_img_2.jpg # 每个镜头给出三个关键帧。
| | :
│ : │─ shot_1256_img_2.jpg
│ |
│ │─ tt1093906
│ │─ shot_0000_img_0.jpg
│ │─ shot_0000_img_1.jpg
│ │─ shot_0000_img_2.jpg
| :
│ │─ shot_1270_img_2.jpg
│
│─anno
│─ anno.pretrain.ndjson
│─ anno.trainvaltest.ndjson
│─ anno.train.ndjson
│─ anno.val.ndjson
│─ anno.test.ndjson
│─ vid2idx.json
│─scene318
│─ label318
│─ meta
│─ shot_movie318
3. 训练(预训练和微调)
我们使用Hydra来提供灵活的训练配置。
以下示例说明了如何根据您的使用情况修改每个训练参数。
我们假设您位于<path-to-root>(即本仓库的根目录)。
3.1. 预训练
(1) 预训练BaSSL
我们的预训练基于分布式环境(多GPU训练),使用pytorch-lightning支持的ddp环境。
默认设置需要8个GPU(V100)和256的批量大小。但是,您可以将参数config.DISTRIBUTED.NUM_PROC_PER_NODE设置为您可以使用的GPU数量,或更改config.TRAIN.BATCH_SIZE.effective_batch_size。
您可以运行单个命令cd bassl; bash ../scripts/run_pretrain_bassl.sh或以下完整命令:
cd <path-to-root>/bassl
EXPR_NAME=bassl
WORK_DIR=$(pwd)
PYTHONPATH=${WORK_DIR} python3 ${WORK_DIR}/pretrain/main.py \
config.EXPR_NAME=${EXPR_NAME} \
config.DISTRIBUTED.NUM_NODES=1 \
config.DISTRIBUTED.NUM_PROC_PER_NODE=8 \
config.TRAIN.BATCH_SIZE.effective_batch_size=256
请注意,检查点会自动保存在bassl/pretrain/ckpt/<EXPR_NAME>中,日志文件(例如tensorboard)保存在bassl/pretrain/logs/<EXPR_NAME>中。
(2) 使用各种损失组合运行
每个目标都可以独立开启和关闭。
cd <path-to-root>/bassl
EXPR_NAME=bassl_all_pretext_tasks
WORK_DIR=$(pwd)
PYTHONPATH=${WORK_DIR} python3 ${WORK_DIR}/pretrain/main.py \
config.EXPR_NAME=${EXPR_NAME} \
config.LOSS.shot_scene_matching.enabled=true \
config.LOSS.contextual_group_matching.enabled=true \
config.LOSS.pseudo_boundary_prediction.enabled=true \
config.LOSS.masked_shot_modeling.enabled=true
(3) 预训练镜头级预训练基线
镜头级预训练方法可以通过将config.LOSS.sampling_method.name设置为以下之一来训练:
instance(Simclr_instance),temporal(Simclr_temporal),shotcol(Simclr_NN)。 此外,您还可以选择两个更多的选项:bassl(BaSSL)和bassl+shotcol(BaSSL+ShotCoL)。 以下示例是针对Simclr_NN,即ShotCoL。选择您喜欢的选项 ;)
cd <path-to-root>/bassl
EXPR_NAME=Simclr_NN
WORK_DIR=$(pwd)
PYTHONPATH=${WORK_DIR} python3 ${WORK_DIR}/pretrain/main.py \
config.EXPR_NAME=${EXPR_NAME} \
config.LOSS.sampleing_method.name=shotcol \
3.2. 微调
(1) 运行单个命令来微调预训练模型
首先,下载模型库部分提供的检查点,并将它们移动到bassl/pretrain/ckpt。
cd <path-to-root>/bassl
# 微调BaSSL(10个epoch)
bash ../scripts/finetune_bassl.sh
# 微调Simclr_NN(即ShotCoL)
bash ../scripts/finetune_shot-level_baseline.sh
完整流程(即提取镜头级表示followed by微调)描述如下。
(2) 从镜头关键帧提取镜头级特征
为了提高计算效率,我们预先提取镜头级表示,然后微调预训练模型。
将LOAD_FROM设置为预训练阶段使用的EXPR_NAME,并将config.DISTRIBUTED.NUM_PROC_PER_NODE更改为可以使用的GPU数量。
然后,提取的镜头级特征将保存在<path-to-root>/bassl/data/movienet/features/<LOAD_FROM>中。
cd <path-to-root>/bassl
LOAD_FROM=bassl
WORK_DIR=$(pwd)
PYTHONPATH=${WORK_DIR} python3 ${WORK_DIR}/pretrain/extract_shot_repr.py \
config.DISTRIBUTED.NUM_NODES=1 \
config.DISTRIBUTED.NUM_PROC_PER_NODE=1 \
+config.LOAD_FROM=${LOAD_FROM}
(3) 微调和评估
cd <path-to-root>/bassl
WORK_DIR=$(pwd)
# 预训练方法:bassl和bassl+shotcol
# 在预训练阶段学习CRN网络
LOAD_FROM=bassl
EXPR_NAME=transfer_finetune_${LOAD_FROM}
PYTHONPATH=${WORK_DIR} python3 ${WORK_DIR}/finetune/main.py \
config.TRAIN.BATCH_SIZE.effective_batch_size=1024 \
config.EXPR_NAME=${EXPR_NAME} \
config.DISTRIBUTED.NUM_NODES=1 \
config.DISTRIBUTED.NUM_PROC_PER_NODE=1 \
config.TRAIN.OPTIMIZER.lr.base_lr=0.0000025 \
+config.PRETRAINED_LOAD_FROM=${LOAD_FROM}
# 预训练方法:instance、temporal、shotcol
# 在预训练阶段不学习CRN网络
# 因此,我们使用不同的基础学习率(经过超参数搜索后确定)
LOAD_FROM=shotcol_pretrain
EXPR_NAME=finetune_scratch_${LOAD_FROM}
PYTHONPATH=${WORK_DIR} python3 ${WORK_DIR}/finetune/main.py \
config.TRAIN.BATCH_SIZE.effective_batch_size=1024 \
config.EXPR_NAME=${EXPR_NAME} \
config.DISTRIBUTED.NUM_NODES=1 \
config.DISTRIBUTED.NUM_PROC_PER_NODE=1 \
config.TRAIN.OPTIMIZER.lr.base_lr=0.000025 \
+config.PRETRAINED_LOAD_FROM=${LOAD_FROM}
4. 模型库
我们提供以自监督方式训练的预训练检查点。
使用这些检查点进行微调后,模型将给出与下面所示几乎相似的分数。
| 方法 | AP | 检查点(预训练) |
|---|---|---|
| SimCLR (instance) | 51.51 | 下载 |
| SimCLR (temporal) | 50.05 | 下载 |
| SimCLR (NN) | 51.17 | 下载 |
| BaSSL (10 epoch) | 56.26 | 下载 |
| BaSSL (40 epoch) | 57.40 | 下载 |
5. 引用
如果您发现此代码对您的研究有帮助,请引用我们的论文。
@article{mun2022boundary,
title={Boundary-aware Self-supervised Learning for Video Scene Segmentation},
author={Mun, Jonghwan and Shin, Minchul and Han, Gunsu and
Lee, Sangho and Ha, Sungsu and Lee, Joonseok and Kim, Eun-sol},
journal={arXiv preprint arXiv:2201.05277},
year={2022}
}
6. 问题联系
Jonghwan Mun, jason.mun@kakaobrain.com
Minchul Shin, craig.starr@kakaobrain.com
7. 许可证
本项目根据Apache License 2.0条款授权。 版权所有 2021 Kakao Brain Corp。保留所有权利。











