










Kedro是什么?
Kedro是一个用于生产就绪数据科学的工具箱。它采用软件工程最佳实践来帮助您创建可重现、可维护和模块化的数据工程和数据科学管道。您可以在kedro.org了解更多信息。
Kedro是由LF AI & Data基金会托管的开源Python框架。
如何安装Kedro?
要从Python包索引(PyPI)安装Kedro,请运行:
pip install kedro
也可以使用conda安装Kedro:
conda install -c conda-forge kedro
我们的入门指南包含完整的安装说明,并包括如何设置Python虚拟环境。
从源代码安装
要在正式发布之前访问最新的Kedro版本,请从main分支安装。
pip install git+https://github.com/kedro-org/kedro@main
Kedro的主要特性是什么?
| 功能 | 这是什么? |
|---|---|
| 项目模板 | 基于 Cookiecutter Data Science 的标准、可修改且易于使用的项目模板。 |
| 数据目录 | 一系列轻量级数据连接器,用于在多种不同文件格式和文件系统中保存和加载数据,包括本地和网络文件系统、云对象存储和 HDFS。数据目录还包括基于文件系统的数据和模型版本控制。 |
| 管道抽象 | 使用 Kedro-Viz 自动解析纯 Python 函数之间的依赖关系并可视化数据管道。 |
| 编码标准 | 使用 pytest 进行测试驱动开发,使用 Sphinx 生成文档完善的代码,使用 ruff 支持代码检查,并使用标准 Python 日志库。 |
| 灵活部署 | 部署策略包括单机或分布式机器部署,以及在 Argo、Prefect、Kubeflow、AWS Batch 和 Databricks 上部署的额外支持。 |
如何使用 Kedro?
Kedro 文档首先解释了如何安装 Kedro,然后介绍了Kedro 的关键概念。
然后你可以查看太空飞行教程来构建一个 Kedro 项目,获得实践经验。
对于新手和中级 Kedro 用户,有一个全面的章节介绍如何使用 Kedro-Viz 可视化 Kedro 项目。
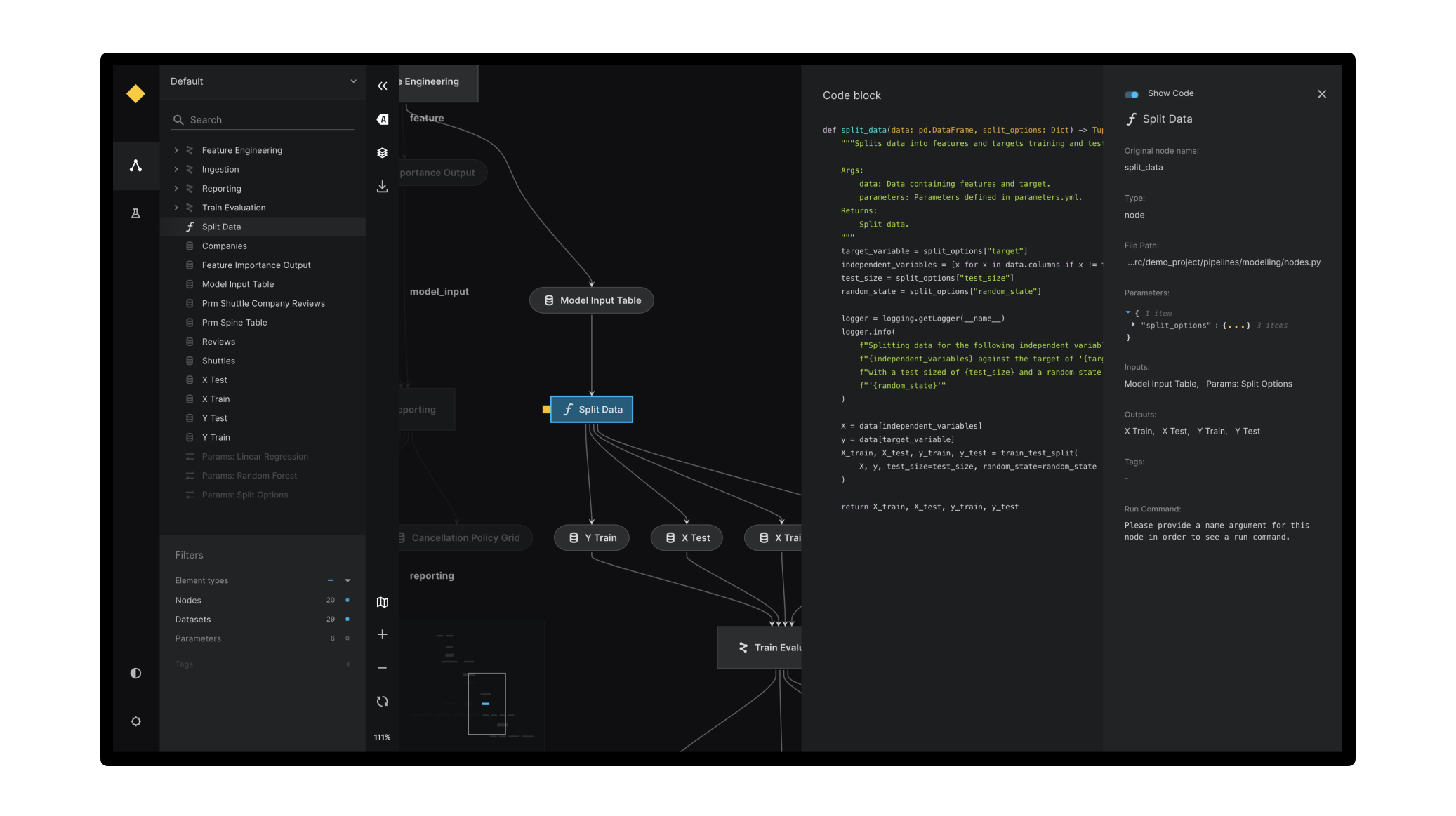 使用 Kedro-Viz 生成的管道可视化
使用 Kedro-Viz 生成的管道可视化
额外的文档解释了如何使用 Kedro 和 Jupyter 笔记本,还有一套针对 Kedro 关键功能的高级用户指南。我们还推荐查阅 API 参考文档以获取更多信息。
Kedro 为什么存在?
Kedro 建立在我们尝试交付具有大量原始未经验证数据的真实世界 ML 应用程序的集体最佳实践(和错误)之上。我们开发 Kedro 是为了实现以下目标:
- 解决 Jupyter 笔记本、一次性脚本和胶水代码的主要缺点,因为重点是创建可维护的数据科学代码
- 当不同团队成员对软件工程概念的接触程度不同时,增强团队协作
- 提高效率,因为模块化和关注点分离等应用概念启发了可重用分析代码的创建
从 Kedro 网站上的产品常见问题了解更多关于 Kedro 如何解决您的用例的信息。
Kedro 背后的人
Kedro 产品团队和来自世界各地的一些开源贡献者维护着 Kedro。
我可以贡献吗?
当然可以!我们欢迎各种形式的贡献。查看我们的Kedro 贡献指南。
我在哪里可以了解更多?
Kedro 周围有一个不断增长的社区。我们鼓励您在 Slack 上提出和回答技术问题,并将过往讨论的 Linen 存档加入书签。
我们在 Kedro 文档中保存了一份技术常见问题列表,你还可以在 awesome-kedro GitHub 仓库中找到越来越多的博客文章、视频和使用 Kedro 的项目。如果你用 Kedro 创建了任何内容,我们很乐意将其添加到列表中。只需提交一个 PR 来添加它!
如何引用 Kedro?
如果您是一位学者,Kedro也能帮助您,例如,作为解决可重复研究问题的工具。使用我们仓库上的"引用此仓库"按钮从CITATION.cff文件生成引用。
Python版本支持政策
- 核心Kedro框架支持CPython核心团队积极维护的所有Python版本。当Python版本达到生命周期终止时,Kedro会停止对该版本的支持。这不被视为重大变更。
- Kedro数据集包遵循NEP 29 Python版本支持政策。这意味着kedro-datasets通常会比kedro更早停止对某个Python版本的支持。这是因为kedro-datasets有许多遵循NEP 29的依赖项,而Kedro框架更保守的版本支持方法使得正确管理这些依赖项变得困难。











