
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文Manga OCR
针对日语文字的光学字符识别,主要聚焦于日本漫画。 它使用了基于Transformers的视觉编码器解码器框架构建的自定义端到端模型。
Manga OCR可以用作通用的印刷日语OCR,但其主要目的是提供高质量的文本识别,能够在各种漫画特定的场景下表现出色:
- 识别垂直和水平文字
- 识别带有假名标注的文字
- 识别覆盖在图像上的文字
- 识别各种字体和字体风格
- 识别低质量图像
与许多OCR模型不同,Manga OCR支持在一次前向传递中识别多行文本,因此可以一次处理漫画中的文本气泡,而无需将它们拆分为单独的行。
相关项目:
- Poricom,一个使用manga-ocr的GUI阅读器
- mokuro,一个使用manga-ocr生成漫画HTML覆盖的工具
- Xelieu的指南,一个关于如何使用manga-ocr/mokuro进行阅读和挖掘工作流的综合指南(以及许多其他有用的提示)
- 开发代码,包括训练和生成合成数据的代码:链接
- 合成数据生成管道的描述 + 生成图像的示例:链接
安装
需要Python 3.6或更新版本。请注意,由于PyTorch依赖项的问题,最新的Python版本可能不受支持,该依赖项经常在新的Python版本发布时出现问题,并需要一些时间才能跟上。请参阅PyTorch网站获取支持的Python版本列表。
有些用户报告了使用从Microsoft Store安装的Python时遇到的问题。如果您看到错误:
ImportError: DLL load failed while importing fugashi: The specified module could not be found.
尝试从官方网站安装Python。
如果您希望使用GPU运行,请按照此处描述安装PyTorch,否则可以跳过此步骤。
故障排除
ImportError: DLL load failed while importing fugashi: The specified module could not be found.- 可能是由于从Microsoft Store安装的Python所致,尝试从官方网站安装Python- 在ARM架构上安装
mecab-python3的问题 - 尝试此解决办法
使用方法
Python API
from manga_ocr import MangaOcr
mocr = MangaOcr()
text = mocr('/path/to/img')
或者
import PIL.Image
from manga_ocr import MangaOcr
mocr = MangaOcr()
img = PIL.Image.open('/path/to/img')
text = mocr(img)
在后台运行
Manga OCR可以在后台运行并处理新出现的图像。
可以使用类似ShareX或Flameshot之类的工具手动捕捉屏幕的某个区域,并让OCR从系统剪贴板或指定目录中读取它。默认情况下,Manga OCR会将识别的文本写入剪贴板,可以通过Yomichan这样的字典读取。
在Linux上,剪贴板模式需要wl-copy用于Wayland会话或xclip用于X11会话。您可以通过在终端中运行echo $XDG_SESSION_TYPE来查看系统需要哪个。
用于使用字典阅读日语漫画的完整设置可能如下所示:
使用ShareX捕捉区域 -> 将图像写入剪贴板 -> Manga OCR -> 将文本写入剪贴板 -> Yomichan
- 要从剪贴板读取图像并将识别的文本写入剪贴板,请在命令行中运行:
manga_ocr - 要从ShareX的截图文件夹读取图像,请在命令行中运行:
manga_ocr "/path/to/sharex/screenshot/folder"
请注意,在剪贴板扫描模式下,任何您复制到剪贴板的图像都会被OCR处理并替换为识别的文本。如果您希望能够像平常一样复制和粘贴图像,应该改用文件夹扫描模式,并在ShareX中为OCR定义一个单独任务,将截图保存到某个文件夹而不是复制到剪贴板。
第一次运行时,下载模型(约400 MB)可能需要几分钟时间。
在日志中看到OCR ready消息后,OCR就可以使用了。
- 要查看其他选项,请在命令行中运行:
manga_ocr --help
如果manga_ocr不起作用,您也可以尝试替换为python -m manga_ocr。
使用小技巧
- OCR支持多行文本,但文本越长,出现错误的可能性就越大。如果识别长文本的某部分失败,可以尝试在较小的图像区域上运行。
- 该模型专门针对漫画进行了训练,但在其他类型的印刷文本(如小说或电子游戏)上也应表现不错。不过,它可能无法处理手写文本。
- 即使图像上没有文字,模型也会尝试识别一些文字。由于它使用了一个transformer解码器(因此对日语有一定了解),它甚至可能“想象出”一些看起来真实的句子!这在大多数用例中应该不会构成问题,但下一版本可能会有所改进。
示例
以下是一些挑选的示例,展示了该模型的能力。
| 图片 | Manga OCR结果 |
|---|---|
 | 素直にあやまるしか |
 | 立川で見た〝穴〟の下の巨大な眼は: |
 | 実战剣術も一流です |
 | 第30話重苦しい闇の奥で静かに呼吸づきながら |
 | よかったじゃないわよ!何逃げてるのよ!!早くあいつを退治してよ! |
 | ぎゃっ |
 | ピンポーーン |
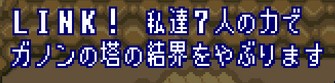 | LINK!私達7人の力でガノンの塔の結界をやぶります |
 | ファイアパンチ |
 | 少し黙っている |
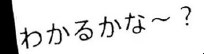 | わかるかな〜? |
 | 警察にも先生にも町中の人達に!! |
联系方式
如有任何疑问,请随时联系我:kha-white@mail.com
致谢
该项目使用了以下资源:
- Manga109-s 数据集
- CC-100 数据集











