
 Github
Github 论文
论文
LongNet:将 Transformer 扩展到 10 亿个 Token




 ](https://twitter.com/intent/tweet?text=很高兴介绍 LongNet,这是一个全新的长序列模型,有潜力彻底改变自动化。让我们一起踏上通向更智能未来的旅程。%23LongNet%20%23LongSequence&url=https%3A%2F%2Fgithub.com%2Fkyegomez%2FLongNet)
](https://twitter.com/intent/tweet?text=很高兴介绍 LongNet,这是一个全新的长序列模型,有潜力彻底改变自动化。让我们一起踏上通向更智能未来的旅程。%23LongNet%20%23LongSequence&url=https%3A%2F%2Fgithub.com%2Fkyegomez%2FLongNet)
[
](https://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Fgithub.com%2Fkyegomez%2FLongNet&title=介绍 LongNet,全新的长序列模型&summary=LongNet 是下一代长序列模型,承诺通过其智能和效率改变各行各业。加入我们,成为这一革命性旅程的一部分 %23LongNet%20%23LongSequence&source=)

](https://www.reddit.com/submit?url=https%3A%2F%2Fgithub.com%2Fkyegomez%2FLongNet&title=令人兴奋的未来:LongNet,全新的长序列模型 %23LongNet%20%23LongSequence) [
](https://news.ycombinator.com/submitlink?u=https%3A%2F%2Fgithub.com%2Fkyegomez%2FLongNet&t=令人兴奋的未来:LongNet,全新的长序列模型 %23LongNet%20%23LongSequence)
[
](https://pinterest.com/pin/create/button/?url=https%3A%2F%2Fgithub.com%2Fkyegomez%2FLongNet&media=https%3A%2F%2Fexample.com%2Fimage.jpg&description=LongNet,革命性的长序列模型,将改变我们的工作方式 %23LongNet%20%23LongSequence)
[
](https://api.whatsapp.com/send?text=我刚刚发现了 LongNet,这是一个全新的长序列模型,有望彻底改变自动化。和我一起踏上这个激动人心的智能未来之旅吧。%23LongNet%20%23LongSequence%0A%0Ahttps%3A%2F%2Fgithub.com%2Fkyegomez%2FLongNet)
这是论文LongNet: 将 Transformer 扩展到 10 亿个 Token的开源实现,作者为丁佳钰、马树铭、董力、张星星、黄少汉、王文辉和魏馥茹。LongNet 是一种 Transformer 变体,旨在将序列长度扩展到超过 10 亿个 token,同时不牺牲较短序列的性能。
安装
pip install longnet
使用方法
安装 LongNet 后,您可以按以下方式使用 DilatedAttention 类:
import torch
from long_net import DilatedAttention
# 模型配置
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# 输入数据
batch_size = 32
seq_len = 8192
# 创建模型和数据
model = DilatedAttention(dim, heads, dilation_rate, segment_size, qk_norm=True)
x = torch.randn((batch_size, seq_len, dim))
output = model(x)
print(output)
LongNetTransformer
一个完全可训练的 transformer 模型,具有膨胀 transformer 块、带有层归一化的前馈网络、SWIGLU 和并行 transformer 块
import torch
from long_net.model import LongNetTransformer
longnet = LongNetTransformer(
num_tokens=20000,
dim=512,
depth=6,
dim_head=64,
heads=8,
ff_mult=4,
)
tokens = torch.randint(0, 20000, (1, 512))
logits = longnet(tokens)
print(logits)
训练
- 要在 enwiki8 数据集上运行简单的训练,请 git clone,安装 requirements.txt,然后运行
python3 train.py
LongNet 概述
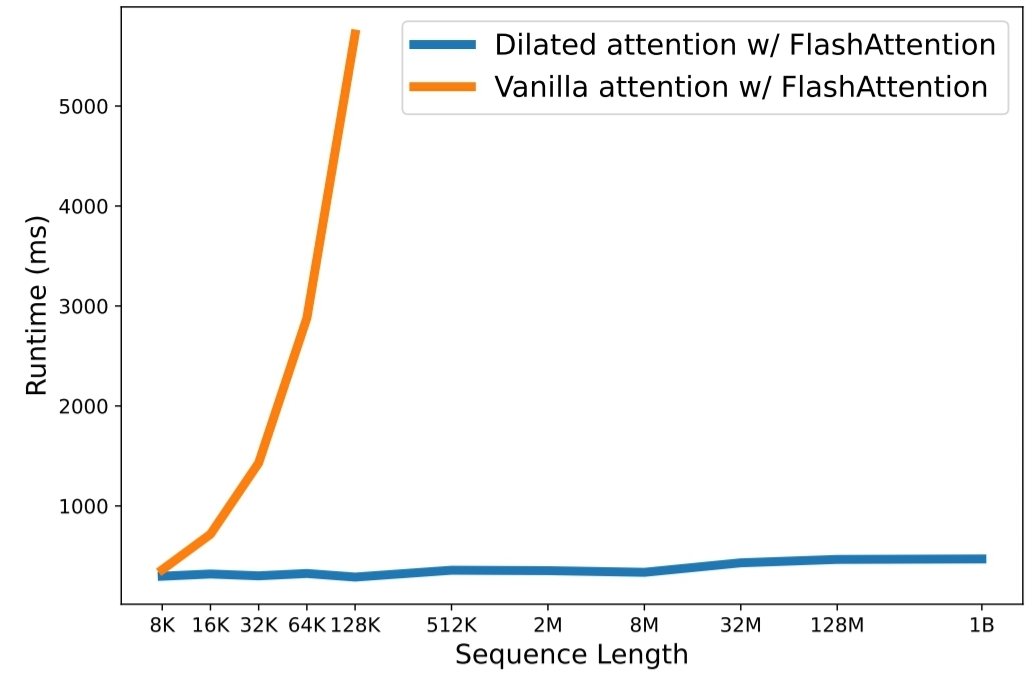
在大型语言模型时代,扩展序列长度已成为一个关键瓶颈。然而,现有方法在计算复杂性或模型表达能力方面都存在困难,导致最大序列长度受到限制。在本文中,他们介绍了 LongNet,这是一种 Transformer 变体,可以将序列长度扩展到超过 10 亿个 token,同时不牺牲较短序列的性能。具体而言,他们提出了膨胀注意力,随着距离的增加,注意力场呈指数级扩大。
特点
LongNet 具有显著优势:
- 它具有线性计算复杂度和对数级别的 token 间依赖关系。
- 它可以作为极长序列的分布式训练器。
- 其膨胀注意力机制是标准注意力的即插即用替代品,可以无缝集成到现有的基于 Transformer 的优化中。
实验结果表明,LongNet 在长序列建模和一般语言任务上都表现出色。他们的工作为建模超长序列开辟了新的可能性,例如将整个语料库甚至整个互联网作为一个序列处理。
引用
@inproceedings{ding2023longnet,
title={LongNet: Scaling Transformers to 1,000,000,000 Tokens},
author={Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu},
booktitle={Proceedings of the 10th International Conference on Learning Representations},
year={2023}
}
待办事项
- 修复并行 Transformer 块的前向传播中的膨胀注意力
- 在 enwiki8 上训练并测试
- 创建多头迭代












{kind=link}