
YOLOExplorer
使用简单的API精确探索、操作和迭代计算机视觉数据集。 支持SQL过滤、向量相似度搜索、与Pandas的原生接口等功能。
- 使用强大的自定义查询分析数据集
- 查找并删除不良图像(重复、域外数据等)
- 通过从其他数据集添加更多示例来丰富数据集
- 以及更多功能
🌟 新功能:支持GUI仪表板、Python风格和笔记本工作流
仪表板工作流
支持多个数据集
您现在可以探索多个数据集,在它们之间搜索,在多个数据集中添加/删除图像以丰富不良示例。在几秒钟内开始在新数据集上训练。 以下是同时使用VOC、coco128和coco8数据集的示例,其中VOC作为主要数据集。from yoloexplorer import Explorerexp = Explorer("VOC.yaml") exp.build_embeddings()
coco_exp = Explorer("coco128.yaml") coco_exp.build_embeddings() #类似地初始化coco8
exp.dash([coco_exp, coco8]) #自动分析功能即将推出,使用dash(..., analysis=True)
支持多个模型
您现在可以探索列出的多个预训练模型
"resnet18", "resnet50", "efficientnet_b0", "efficientnet_v2_s", "googlenet", "mobilenet_v3_small",以从图像中提取更好的特征,改善跨多个数据集的搜索。
from yoloexplorer import Explorerexp = Explorer("coco128.yaml", model="resnet50") exp.build_embeddings()
coco_exp = Explorer("coco128.yaml", model="mobilenet_v3_small") coco_exp.build_embeddings()
#如果嵌入已存在,在build_embedding中使用force=True参数
exp.dash([coco_exp, coco8]) #自动分析功能即将推出,使用dash(..., analysis=True)
使用SQL和语义搜索查询,将数据集视为pandas DataFrame并探索嵌入

Colab / 笔记本
安装
pip install yoloexplorer
从源分支安装
pip install git+https://github.com/lancedb/yoloexplorer.git
Pypi安装即将推出
快速入门
YOLOExplorer可用于快速生成可在Ultralytics YOLO, SAM, FAST-SAM, RT-DETR等模型上训练的新版本CV数据集。
通过以下两个简单步骤开始探索您的数据集
- 选择支持的数据集或使用您自己的数据集。目前支持所有Ultralytics YOLO数据集
from yoloexplorer import Explorer
coco_exp = Explorer("coco128.yaml")
- 构建LanceDB表以允许查询
coco_exp.build_embeddings()
coco_exp.dash() # 启动GUI仪表板
查询基础
构建表后,您可以获取数据集的架构
schema = coco_exp.table.schema
您可以使用此架构运行查询
SQL查询
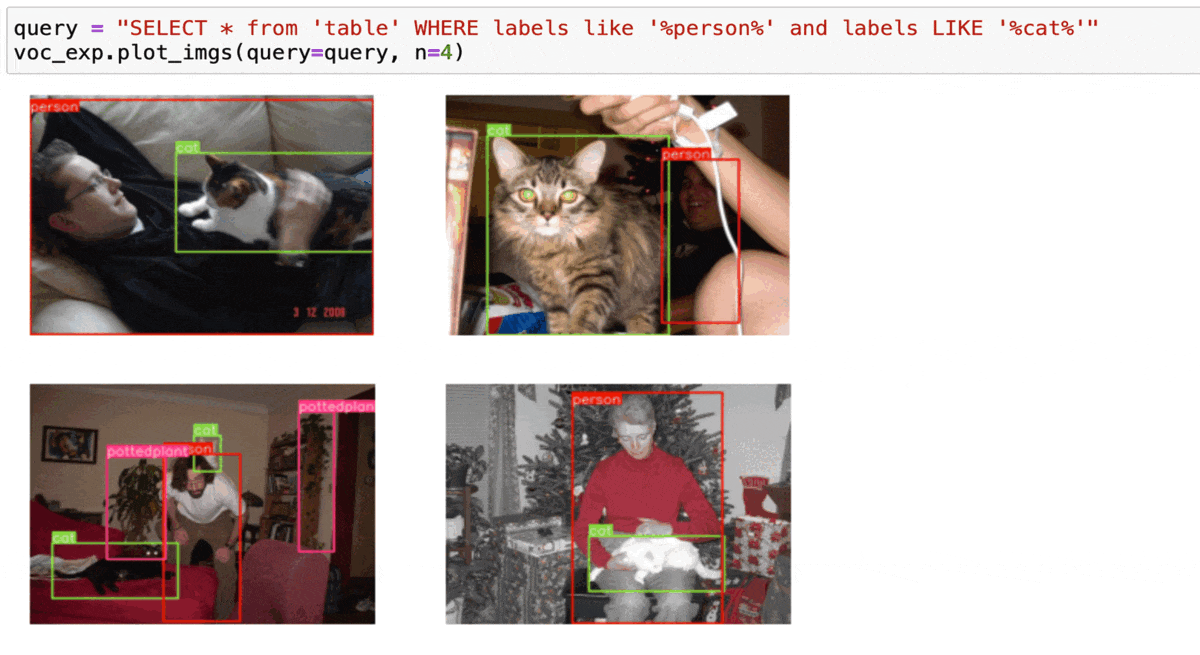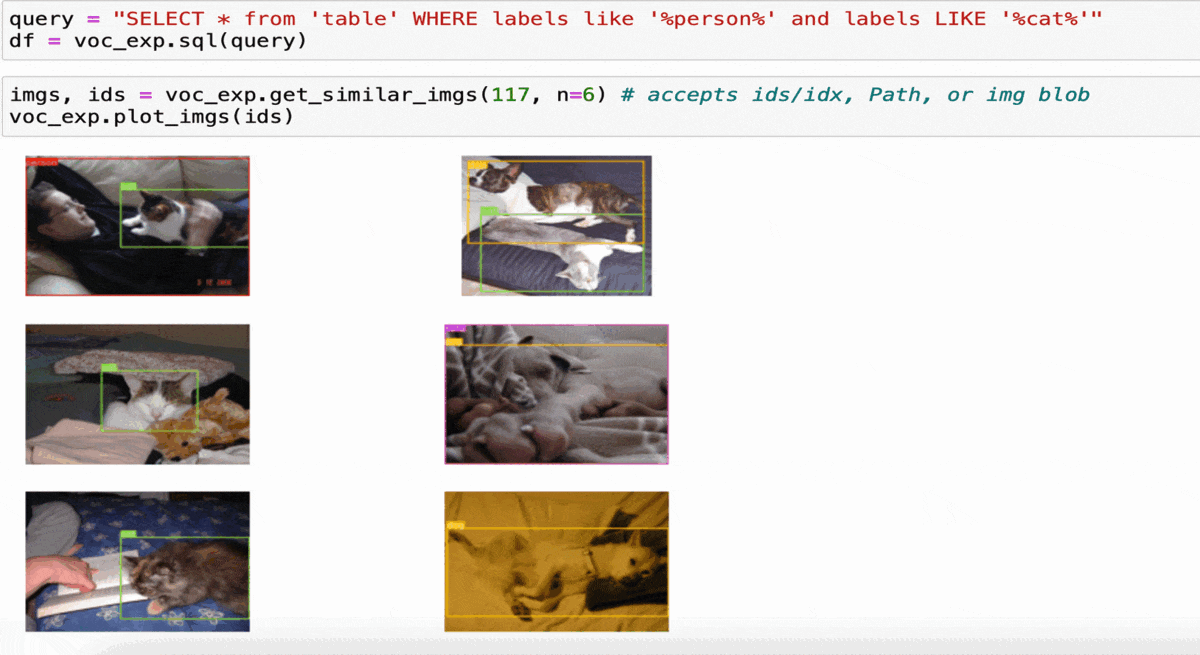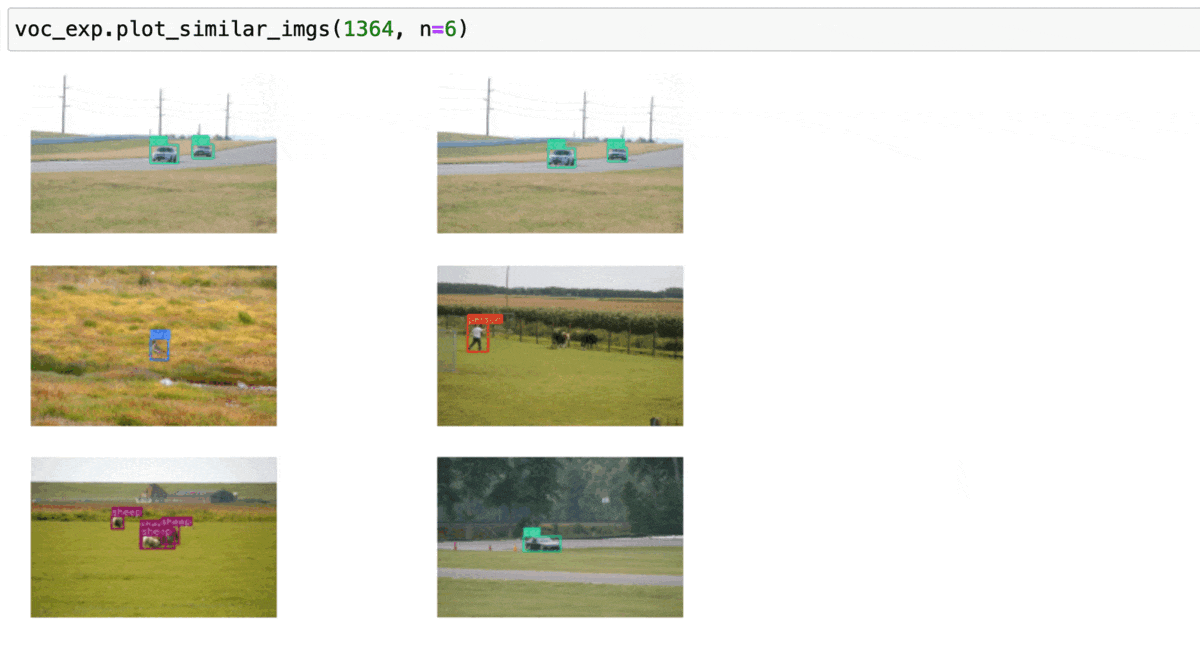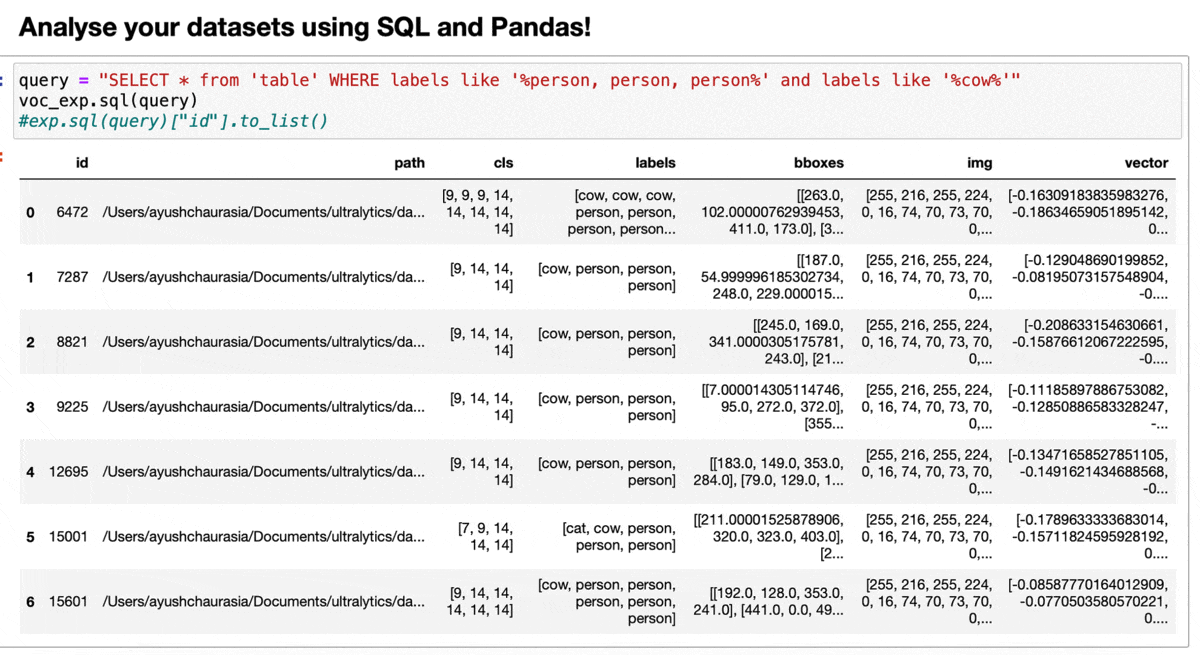
让我们尝试这个查询并打印4个结果 - 选择包含一个或多个'person'和'cat'的实例
df = coco_exp.sql("SELECT * from 'table' WHERE labels like '%person%' and labels LIKE '%cat%'")
coco_exp.plot_imgs(ids=df["id"][0:4].to_list())
结果

上述操作等同于直接使用查询进行绘图:
voc_exp.plot_imgs(query=query, n=4)
相似度查询
现在假设您的模型混淆了某些类别(例如猫和狗),所以您想查找与上面类似的图像进行调查。
在这种情况下,第一张图像的id是117
imgs, ids = coco_exp.get_similar_imgs(117, n=6) # 接受ids/idx、Path或img blob
voc_exp.plot_imgs(ids)

上述操作等同于直接调用plot_similar_imgs
voc_exp.plot_similar_imgs(117, n=6)
注意:您也可以传递任何不在数据集中的图像文件进行相似度搜索
带SQL过滤的相似度搜索(即将推出)
很快您将能够通过预过滤表格来更精细地控制查询
coco_exp.get_similar_imgs(..., query="WHERE labels LIKE '%motorbike%'")
coco_exp.plot_similar_imgs(query="WHERE labels LIKE '%motorbike%'")
绘图
| 可视化方法 | 描述 | 参数 | |---|---|---| | `plot_imgs(ids, query, n=10)` | 绘制给定的`ids`或SQL查询结果。必须提供两者之一。 | `ids`: 图像ID列表或SQL查询。`n`: 要绘制的图像数量。 | | `plot_similar_imgs(img/idx, n=10)` | 绘制与给定图像最相似的`n`张图像。接受数据集中的图像索引、图像路径或编码/二进制图像 | `img/idx`: 要查找相似图像的图像。`n`: 要绘制的相似图像数量。 | | `plot_similarity_index(top_k=0.01, sim_thres=0.90, reduce=False, sorted=False)` | 绘制数据集的相似度索引。这提供了一个图像与数据集中所有图像相比的相似程度的度量。 | `top_k`: 保留用于相似度索引的图像百分比。`sim_thres`: 相似度阈值。`reduce`: 是否降低相似度索引的维度。`sorted`: 是否对相似度索引进行排序。 |附加详情
plot_imgs方法可用于可视化数据集中的一部分图像。ids参数可以是图像ID列表,也可以是返回图像ID列表的SQL查询。n参数指定要绘制的图像数量。plot_similar_imgs方法可用于可视化与给定图像最相似的前n张图像。img/idx参数可以是数据集中图像的索引、图像文件的路径或图像的编码/二进制表示。plot_similarity_index方法可用于可视化数据集的相似度索引。相似度索引是衡量每张图像与数据集中所有其他图像的相似程度的指标。top_k参数指定保留用于相似度索引的图像百分比。sim_thres参数指定相似度阈值。reduce参数指定在计算索引之前是否降低嵌入的维度。sorted参数指定是否对相似度索引进行排序。
添加、删除、合并数据集的部分内容,持久化新数据集,并开始训练!
一旦找到想要添加或删除的正确图像,您可以简单地将它们添加到或从数据集中删除,并生成更新后的版本。
删除数据
您可以通过传递表格中的ids列表来简单地删除图像。
coco_exp.remove_imgs([100,120,300..n]) # 删除给定id的图像。
添加数据 要从另一个数据集添加数据,您需要该数据集的探索器对象,并已构建嵌入。然后,您可以传递该对象以及您想从该数据集添加的图像的id。
coco_exp.add_imgs(exp, idxs) #
注意:您可以使用SQL查询和/或相似度搜索来获取数据集中所需的id。
持久化表格:创建新数据集并开始训练 进行所需更改后,您可以持久化表格以创建新数据集。
coco_exp.persist()
这将创建一个新的数据集,并输出训练命令,您可以直接将其粘贴到终端中以训练新模型!
重置表格 您可以将表格重置为原始状态或最后持久化的状态(以最新的为准)
coco_exp.reset()
(高级查询)从相似度索引获取见解
plot_similarity_index方法可用于可视化数据集的相似度索引。相似度索引是衡量每张图像与数据集中所有其他图像的相似程度的指标。
让我们看看VOC数据集的相似度索引,保持所有默认设置
voc_exp.plot_similarity_index()
您还可以将相似度索引作为numpy数组获取,以执行高级查询。
sim = voc_exp.get_similarity_index()
现在,您可以将相似度索引与上面讨论的其他查询选项结合起来,创建更强大的查询。这里有一个例子:
"假设您已经创建了一个想要从数据集中删除的候选列表。现在,您想要过滤出相似度索引小于250的图像,即删除与数据集中90%(sim_thres)或更多的250张图像相似的图像。"
ids = [...] # 过滤后的id列表
filter = np.where(sim > 250)
final_ids = np.intersect1d(ids, filter) # 对两个数组取交集
exp.remove_imgs(final_ids)
即将推出
预过滤
- 允许向搜索添加过滤器。
- 对嵌入搜索空间有更精细的控制
预过滤将支持强大的查询,如 - "显示与相似的图像,并且只包含那些包含一个或多个(或恰好一个)人、2辆车和1匹马的图像"
-
自动查找潜在的重复图像
-
更好的嵌入绘图和分析洞察
-
更好的仪表板用于可视化图像
注意:
- API在从开发版到小版本发布时会有一些小的变化
- 出于所有实际目的,id与行号相同,并在每次添加或删除后重置











