
 访问官网
访问官网 Github
Github珊瑚

珊瑚是一个SQL翻译、分析和重写引擎。它建立了一个标准的中间表示-珊瑚IR,它独立于任何SQL方言捕捉了关系代数表达式的语义。珊瑚IR有两种形式:一种是抽象语法树(AST)层面的,另一种是逻辑计划层面的。两种形式是同构的,可以相互转换。
珊瑚暴露了API,用于在SQL方言和珊瑚IR之间实现双向转换。目前,珊瑚支持将HiveQL和Spark SQL转换为珊瑚IR,并将珊瑚IR转换为HiveQL、Spark SQL和Trino SQL。通过支持多种SQL方言,珊瑚可以用来将一种方言定义的SQL语句和视图翻译成另一种方言的等价形式。它还可用于引擎和SQL驱动的数据源之间的互操作。有关方言转换示例,请参见模块[coral-hive]、[coral-spark]和[coral-trino]。
珊瑚还暴露了用于珊瑚IR重写和操作的API。这包括重写珊瑚IR表达式以生成语义等价但性能更好的表达式。例如,珊瑚通过重写视图定义来自动化增量视图维护。有关更多详细信息,请参见模块[coral-incremental]。其他珊瑚重写应用包括数据治理和策略执行。
珊瑚可以作为一个库在其他项目中使用,也可以作为一个服务。有关更多详细信息,请参见下面的说明。
 Slack
Slack
- 在Slack上加入社区讨论here!
模块
珊瑚由以下模块组成:
- Coral-Hive: 将HiveQL转换为珊瑚IR(通常也可用于Spark SQL)。
- Coral-Trino: 将珊瑚IR转换为Trino SQL。将Trino SQL转换为珊瑚IR正在开发中。
- Coral-Spark: 将珊瑚IR转换为Spark SQL(通常也可用于HiveQL)。
- Coral-Dbt: 将珊瑚与DBT集成。它可以在DBT模型上应用珊瑚转换。
- Coral-Incremental: 从输入的SQL派生出增量查询,用于增量视图维护。
- Coral-Schema: 使用视图逻辑计划和基表的Avro模式,推导视图的Avro模式。
- Coral-Spark-Plan [WIP]: 将Spark计划字符串转换为等价的逻辑计划。
- Coral-Visualization: 可视化珊瑚SqlNode和RelNode树并将其呈现到输出文件中。
- Coral-Service: 提供REST API,允许用户与珊瑚交互(更多详细信息请参见Coral即服务)。
版本升级
本项目遵循语义版本控制,其格式x.y.z表示主版本、次版本和修订版本升级。在集成不同版本的本项目时,需要考虑可能需要的潜在更改。
主版本升级
主版本升级表示引入向后不兼容性的版本变更,如类的删除或重命名。
次版本升级
次版本升级表示引入向后不兼容性的版本变更,如方法的删除或重命名。
请仔细查看每个版本升级附带的发行说明和文档,了解具体变更及建议的迁移步骤。
如何构建
克隆仓库:
git clone https://github.com/linkedin/coral.git
构建:
**请注意,该项目需要Python 3和Java 8来运行。**将JAVA_HOME设置为合适版本的主目录,然后使用:
./gradlew clean build
或者,将org.gradle.java.home gradle属性设置为合适版本的java主目录,如下所示:
./gradlew -Dorg.gradle.java.home=/path/to/java/home clean build
贡献
该项目正在积极开发中,我们欢迎各种形式的贡献。 请参见贡献协议。
资源
- Coral: A SQL translation, analysis, and rewrite engine for modern data lakehouses, LinkedIn Engineering Blog, 12/10/2020.
- Incremental View Maintenance with Coral, DBT, and Iceberg, Tech Talk, Iceberg Meetup, 5/11/2023.
- Coral & Transport UDFs: Building Blocks of a Postmodern Data Warehouse, Tech-talk, Facebook HQ, 2/28/2020.
- Transport: Towards Logical Independence Using Translatable Portable UDFs, LinkedIn Engineering Blog, 11/14/2018.
- Dali Views: Functions as a Service for Big Data, LinkedIn Engineering Blog, 11/9/2017.
Coral即服务
Coral即服务或简称Coral服务是一个提供REST API的服务,允许用户与Coral进行交互,而无需直接来自计算引擎。目前,该服务支持一个用于在不同方言之间进行查询翻译的API,以及另一个用于与本地Hive元存储交互以创建示例数据库、表和视图的API,以便在翻译API中引用它们。该服务可以在两种模式下使用:远程Hive元存储模式和本地Hive元存储模式。远程模式使用已部署的现有Hive元存储来解析表和视图,而本地模式创建一个空的嵌入式Hive元存储,以便用户添加自己的表和视图定义。
API参考
/api/translations/translate
一个POSTAPI,它接受包含以下参数的JSON请求体,并返回翻译后的查询:
sourceLanguage: 输入方言(例如,spark、trino、hive-请参见下面支持的输入)targetLanguage: 输出方言(例如,spark、trino、hive-请参见下面支持的输出)query: 要在两种方言之间翻译的SQL查询- [可选]
rewriteType: 珊瑚IR重写的类型(例如, incremental)
/api/catalog-ops/execute
一个POSTAPI,它接受一个SQL语句来在本地元存储中创建数据库/表/视图 (注意:此端点仅在珊瑚服务处于本地元存储模式时可用)。
使用示例的说明
- 克隆珊瑚repo
git clone https://github.com/linkedin/coral.git
- 从珊瑚根目录进入coral-service模块
cd coral-service
- 构建
../gradlew clean build
使用本地元存储运行珊瑚服务:
- 运行
../gradlew bootRun --args='--spring.profiles.active=localMetastore'
使用远程元存储运行Coral Service:
- 将您的kerberos客户端keytab文件添加到
coral-service/src/main/resources - 适当地替换
coral-service/src/main/resources/hive.properties中所有的SET_ME - 运行
../gradlew bootRun
您也可以通过 --hivePropsLocation 指定 hive.properties 文件的自定义位置,如下所示:
./gradlew bootRun --args='--hivePropsLocation=/tmp/hive.properties'
Coral Service UI
在 coral-service 模块中运行 ../gradlew bootRun --args='--spring.profiles.active=localMetastore'(用于本地元存储模式)或 ../gradlew bootRun(用于远程元存储模式)之后,配置并启动UI。
请注意:后端服务运行在8080端口(默认),web UI运行在3000端口(默认)。
配置环境变量:
- 在前端项目的根目录下创建一个
.env.local文件 - 将
.env.local.example中的模板复制到新的.env.local文件中 - 在
.env.local中填写环境变量值
在前端目录中安装所需的软件包:
npm install
现在您可以通过运行以下命令启动Coral Service UI:
npm run dev
编译完成后,可以从浏览器访问 http://localhost:3000 来访问UI。

在本地元存储模式下创建数据库/表/视图
这个功能仅在Coral Service的本地元存储模式下可用,它调用上面的 /api/catalog-ops/execute API。
您可以输入一个SQL语句来在本地元存储中创建数据库/表/视图。

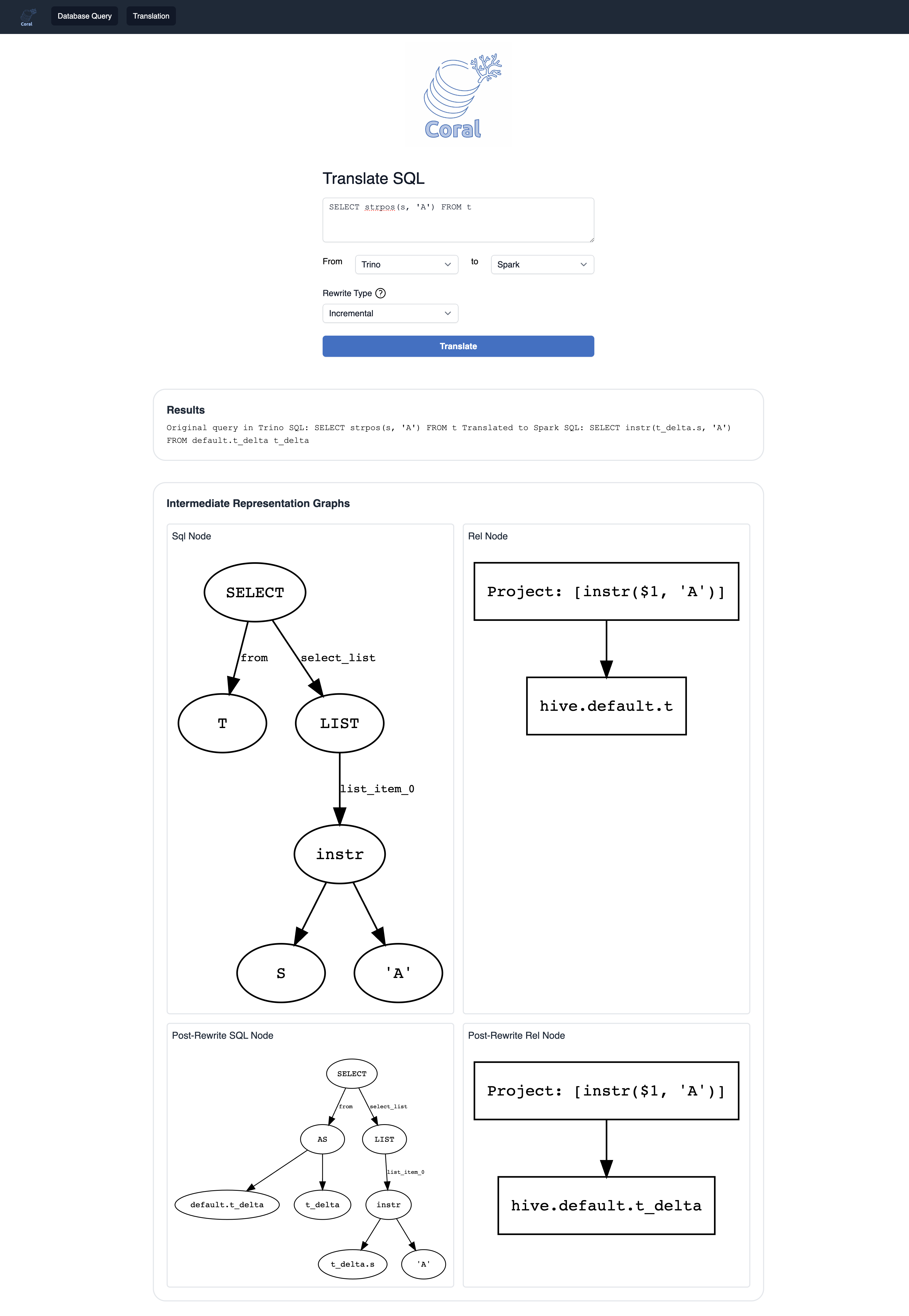
将SQL从源语言翻译到目标语言(带有重写)
这个功能在Coral Service的本地和远程元存储模式下都可用,它调用上面的 /api/translations/translate API。
您可以输入一个SQL查询,并指定源语言和目标语言以使用Coral翻译服务。您还可以指定要应用于输入查询的重写类型。

生成Coral中间表示的Graphviz可视化效果
在翻译过程中,Coral中间表示的图形也将被生成并显示在屏幕上。这也将包括任何事后重写节点。
在前端代码上开发
对您的代码进行lint/格式化:
npm run lint:fix
npm run format
Coral Service CLI
除了上述UI,您也可以使用CLI与该服务进行交互。
本地元存储模式下的示例工作流程:
- 使用
/api/catalog-ops/execute端点在本地元存储中创建一个名为db1的数据库
curl --header "Content-Type: application/json" \
--request POST \
--data "CREATE DATABASE IF NOT EXISTS db1" \
http://localhost:8080/api/catalog-ops/execute
Creation successful
- 使用
/api/catalog-ops/execute端点在db1中的本地元存储中创建一个名为airport的表
curl --header "Content-Type: application/json" \
--request POST \
--data "CREATE TABLE IF NOT EXISTS db1.airport(name string, country string, area_code int, code string, datepartition string)" \
http://localhost:8080/api/catalog-ops/execute
Creation successful
- 使用
/api/translations/translate端点翻译在本地元存储中的db1.airport上的查询
curl --header "Content-Type: application/json" \
--request POST \
--data '{
"sourceLanguage":"hive",
"targetLanguage":"trino",
"query":"SELECT * FROM db1.airport"
}' \
http://localhost:8080/api/translations/translate
翻译结果为:
Original query in HiveQL:
SELECT * FROM db1.airport
Translated to Trino SQL:
SELECT "name", "country", "area_code", "code", "datepartition"
FROM "db1"."airport"
目前支持的翻译流程
- Hive到Trino
- Hive到Spark
- Trino到Spark 注意:在从Trino到Spark的翻译过程中,查询中引用的视图被视为用HiveQL定义的,因此在从Trino翻译视图时无法使用。目前仅支持在Trino查询中引用基表。这种翻译路径目前还是一个概念验证,可能需要进一步改进。
- Spark到Trino











