
 访问官网
访问官网 Github
Github 文档
文档
🀄 国风网文:一个篇章级多语言网络小说语料库



国风网文是一个公开版权、高质量、篇章级和多语言的网络小说语料库。其独特之处在于:
- 丰富的语言和文化现象:文学文本比非文学文本包含更复杂的语言和文化知识。
- 长距离上下文:小说等文学作品比其他领域的文本具有更长的上下文。
- 通用人工智能:我们预计这个数据集不仅会推动机器翻译领域的现有研究,还将激发大型语言模型的新颖研究。
新闻 🤩🤩🤩
- [2024/05/20] 🛰️🛰️🛰️ 国风网文语料库V2已发布:两个篇章级数据集,分别用于中文→德文和中文→俄文。
- [2023/05/15] WMT23共享任务:篇章级文学翻译
- [2024/05/15] 🎉🎉🎉 国风GitHub现已上线 🎉🎉🎉
- [2023/05/06] 🚀🚀🚀 国风网文语料库V1已发布:一个带有句级对齐的篇章级数据集,用于中文→英文。
- [2023/04/14] WMT23共享任务:篇章级文学翻译
国风网文语料库概览 💕
该数据集涵盖了14个流派,如奇幻科幻和言情。详细统计如下。
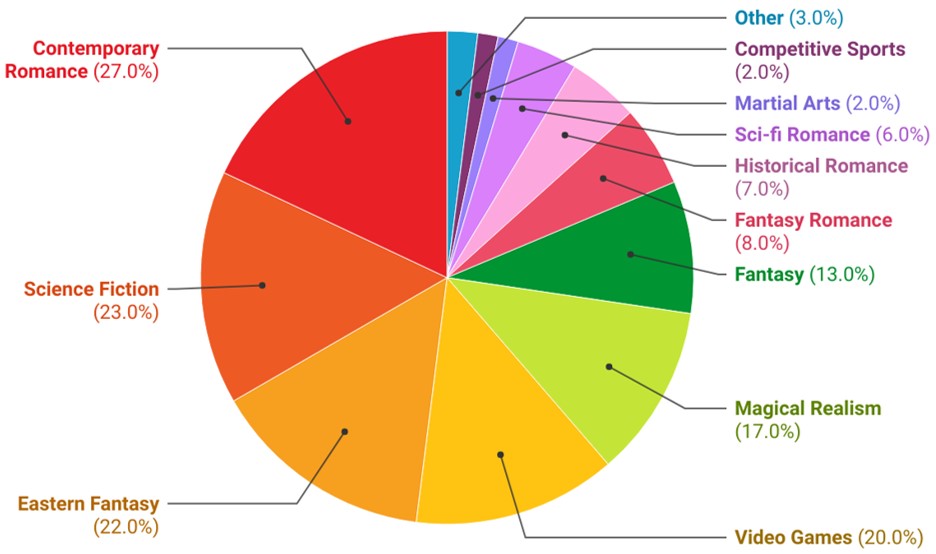
不同语言的高频词词云图如下所示。

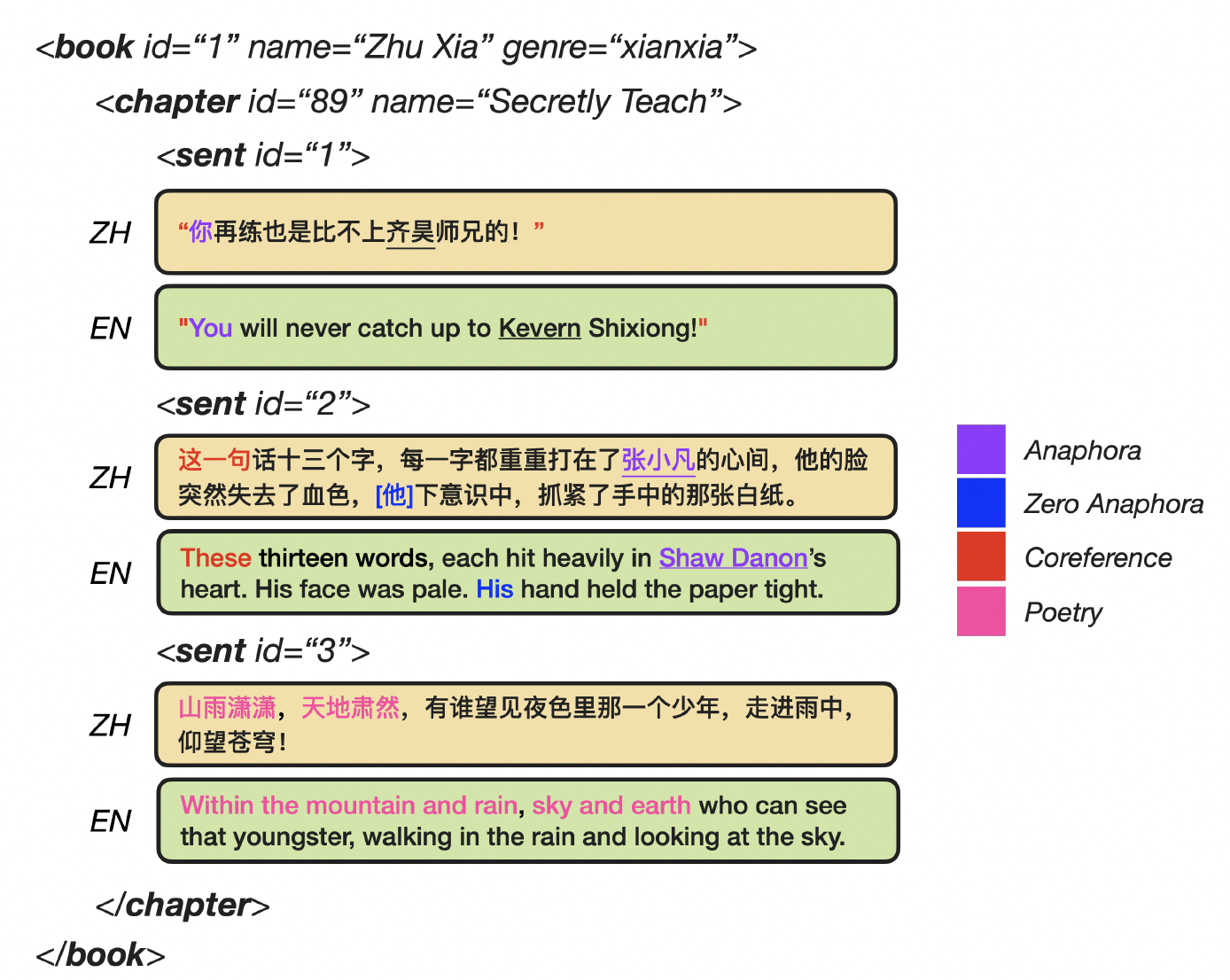
从中英文数据集中抽样的数据示例,彩色词汇展示了丰富的语言现象。
版权和许可
版权是发布文学文本时的一个重要考虑因素,我们(腾讯AI实验室和阅文集团)是本数据集中网络小说的合法版权所有者。我们很高兴能在特定条款和条件下向研究社区提供这些数据。
- 🔔 国风网文语料库的版权归腾讯AI实验室和阅文集团所有。
- 🚦 完成注册流程并提供机构信息后,WMT参与者或研究人员获准仅将数据集用于非商业研究目的,并须遵守合理使用原则(CC-BY 4.0)。
- 🔒 严禁修改或重新分发数据集。如果您计划对数据集进行任何更改(如添加更多注释)并打算公开发布,请先联系我们获得书面同意。
- 🚧 使用本数据集即表示您同意上述条款和条件。我们严正对待版权侵犯行为,将对任何未经授权使用我们数据的行为采取法律行动。
引用 ❗❗❗
📝 如果您使用国风网文语料库,请引用以下论文并声明原始下载链接:
@inproceedings{wang2023findings,
title={Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs},
author={Wang, Longyue and Tu, Zhaopeng and Gu, Yan and Liu, Siyou and Yu, Dian and Ma, Qingsong and Lyu, Chenyang and Zhou, Liting and Liu, Chao-Hong and Ma, Yufeng and others},
booktitle={Proceedings of the Eighth Conference on Machine Translation},
pages={55--67},
year={2023}
}
@inproceedings{wang2024findings,
title={Findings of the WMT 2024 Shared Task on Discourse-Level Literary Translation},
author={Wang, Longyue and Liu, Siyou and Wu, Minghao and Jiao, Wenxiang and Wang, Xing and Xu, Jiahao and Tu, Zhaopeng and Zhou, Liting and Gu, Yan and Chen, Weiyu and Koehn, Philipp and Way, Andy and Yuan, Yulin},
booktitle={Proceedings of the Ninth Conference on Machine Translation},
year={2024}
}
下载链接:https://github.com/longyuewangdcu/GuoFeng-Webnovel
数据处理
💌 网络小说最初由小说作者用中文创作,然后由专业译者翻译成其他语言。以中英文为例,我们使用自动和人工方法处理数据:
- 我们根据双语标题匹配中文书籍及其英文对应版本;
- 在每本书中,中英文章节根据章节ID号对齐;
- 在每个章节内,我们构建了一个基于机器翻译的句子对齐器,以平行方式对齐句子,保持章节中的句子顺序;
- 人工注释员参与审查并纠正句子级对齐中的任何差异。
💡 请注意:
- 由于人工译者以文档方式翻译小说,某些句子可能没有对应的翻译;
- 对于中德和中俄,我们目前跳过了3~4步,仅保留章节级平行数据。当前版本可能包含一些翻译错误,如误译。

中文→英文
我们发布了来自179部网络小说的22,567个连续章节,涵盖奇幻科幻和言情等14个流派。**数据为文档级别,并包含跨句对齐信息。**数据统计如下:
| 表1 | 书籍 | 章节 | 句子 | 备注 |
|---|---|---|---|---|
| 训练集 | 179 | 22,567 | 1,939,187 | 14个流派 |
| 验证集1 | 1 | 22 | 22,755 | 与训练集相同书籍 |
| 测试集1 | 1 | 26 | 22,697 | 与训练集相同书籍 |
| 验证集2 | 2 | 10 | 10,853 | 与训练集不同书籍 |
| 测试集2 | 2 | 12 | 12,917 | 与训练集不同书籍 |
| 测试输入 | - | - | - | 待定 |
数据格式 💾
以"train.en"为例,数据格式如下:**<BOOK id=""> </BOOK>表示一本书的边界,其中包含多个连续章节,用<CHAPTER id=""> </CHAPTER>**标签标记。内容被分割成句子,并手动与"train.zh"中的中文句子对齐。
<BOOK id="100-jdxx">
<CHAPTER id="jdxx_0001">
第1章 做出选择吧,年轻人
"崩塌现实,粉碎灵魂。通过放逐这个世界,遵循血之契约,我将召唤你,年轻的魔王啊!"
在夕阳下的公园里,一个长相英俊的孩童模样的少年将左手放在胸前,右手伸出,五指张开,仿佛要从掌心释放出惊人的力量。他看起来严肃而庄重。
... ...
</CHAPTER>
<CHAPTER id="jdxx_0002">
....
</CHAPTER>
</BOOK>
数据描述(国风网络小说语料库V2)2️⃣
我们发布了来自约120部网络小说的约19K个连续章节,涵盖奇幻科幻和言情等14个流派。数据为文档级别,不包含对齐信息。数据统计如下:
中文→德语
| 子集 | 书籍数量 | 章节数量 | X语言词数 / 中文字数 | 备注 |
|---|---|---|---|---|
| 训练集 | 118 | 19,101 | 25,562,039 / 36,790,017 | 14个流派 |
| 验证集 | -- | -- | -- | -- |
| 测试集 | -- | -- | -- | -- |
| 测试输入 | -- | -- | -- | -- |
中文→俄语
| 子集 | 书籍数量 | 章节数量 | X语言词数 / 中文字数 | 备注 |
|---|---|---|---|---|
| 训练集 | 122 | 19,971 | 23,521,169 / 39,074,007 | 14个流派 |
| 验证集 | -- | -- | -- | -- |
| 测试集 | -- | -- | -- | -- |
| 测试输入 | -- | -- | -- | -- |
数据格式 💾
数据格式:以中德语言对为例,数据格式如下:(1) **1-ac, 2-ccg, ......**表示书籍级别的文件夹。(2) 在"1-ac"文件夹中,15-jlws_0001-CH.txt, 15-jlws_0001-DE.txt, ....是连续的中文和德语章节。(3) 每个文件中没有标签和句级对齐信息。
.
├── 1-ac # 书籍ID - 英文标题
│ ├── 15-jlws_0001-CH.txt # 章节ID - 中文
│ ├── 15-jlws_0001-DE.txt # 章节ID - 德语
│ ├── ...... # 更多章节
├── 2-ccg # 书籍ID - 英文标题
│ ├── 62-xzltq_0002-CH.txt # 章节ID - 中文
│ ├── 62-xzltq_0002-DE.txt # 章节ID - 德语
│ ├── ...... # 更多章节
├── ...... # 更多书籍
15-jlws_0001-CH.txt
第一章 李戴
李戴走出考场,穿梭在密密麻麻的人群当中。看着周围那一张张春风得意的脸,耳边响起路人兴高采烈的讨论声,李戴心中却愈加的沮丧。
"哎,考砸了!想进入到面试是肯定没戏了。"李戴揉了揉太阳穴,头脑中那种沉甸甸的感觉却愈发的浓郁。
15-jlws_0001-DE.txt
Kapitel 1: Li Dai
Li Dai verließ das Prüfungszentrum und bewegte sich durch die dichte Menschenmenge. Er sah die triumphierenden Gesichter um ihn herum und hörte die enthusiastischen Diskussionen der Passanten, doch in seinem Herzen wurde er immer deprimierter.
"Oh, ich habe die Prüfung vergeigt! Eine Chance auf ein Vorstellungsgespräch gibt es sicherlich nicht mehr." Li Dai massierte seine Schläfen, das schwere Gefühl in seinem Kopf wurde immer intensiver.
预训练模型 🔢
我们提供三种领域内预训练模型(与去年相同)和大型语言模型(今年新增):
| 版本 | 层数 | 隐藏大小 | 词表大小 | 持续训练 |
|---|---|---|---|---|
| Chinese-Llama-2-7B | 32 | 4096 | 32000 | 中英文学文本(1150亿词) |
| RoBERTa | base | 12 enc | 768 | 21128 |
| 中文文学文本(840亿词) | mBARTCC25 | 12 enc + 12 dec | 1024 | 250000 |
下载 ⏬
数据下载 👨👩
国风网络小说语料库V1和V2可以通过Github下载:(1) 前往"下载"部分并点击按钮;(2) 填写注册表单,您将在最后一页获得链接。
🎈
🎈
🎈
🎈
模型下载 🤖
委员会
数据团队 🧑🏻💼
王龙跃* (vincentwang0229@gmail.com (腾讯AI实验室)
屠兆鹏 (腾讯AI实验室)
顾言 (阅文集团)
陈伟宇 (阅文集团)
技术团队 🧑🏫
徐家浩 (腾讯AI实验室)
焦文翔 (腾讯AI实验室)
王翔 (腾讯AI实验室)
联系方式 ☎️
如果您有任何进一步的问题或建议,请随时发送电子邮件至王龙跃 (vincentwang0229@gmail.com 或 vinnylywang@tencent.com)。
赞助商 🙏🙏🙏













