
 Github
Github 论文
论文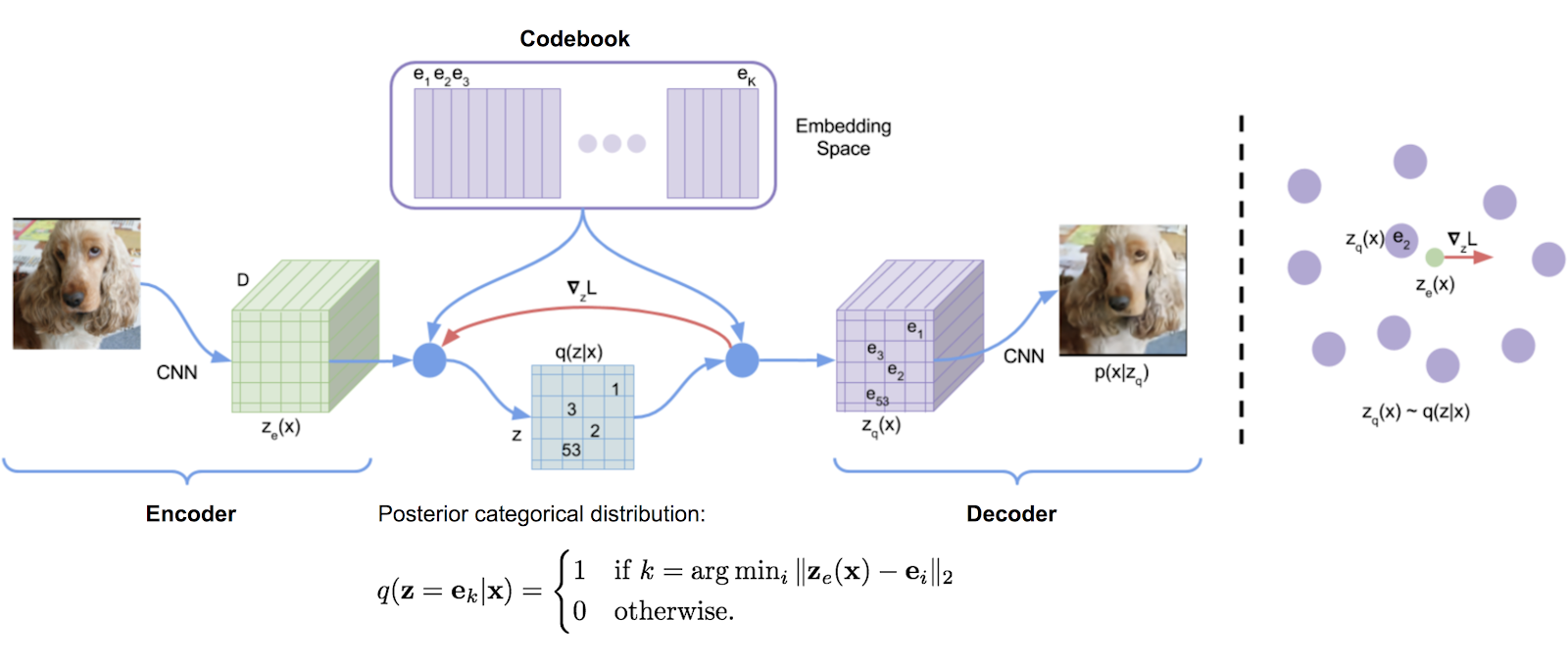
向量量化 - Pytorch
一个向量量化库,最初由Deepmind的tensorflow实现转录而来,现在方便地打包成一个包。它使用指数移动平均数来更新字典。
向量量化已被Deepmind和OpenAI成功使用于生成高质量的图像(VQ-VAE-2)和音乐(Jukebox)。
安装
$ pip install vector-quantize-pytorch
使用
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize(
dim = 256,
codebook_size = 512, # 码本大小
decay = 0.8, # 指数移动平均衰减,值越低字典变化越快
commitment_weight = 1. # 承诺损失的权重
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = vq(x) # (1, 1024, 256), (1, 1024), (1)
残差向量量化
这篇论文提出了使用多个向量量化器递归量化波形的残差。你可以使用ResidualVQ类,并添加一个额外的初始化参数。
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ(
dim = 256,
num_quantizers = 8, # 指定量化器的数量
codebook_size = 1024, # 码本大小
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = residual_vq(x)
print(quantized.shape, indices.shape, commit_loss.shape)
# (1, 1024, 256), (1, 1024, 8), (1, 8)
# 如果你需要所有量化层的代码,只要传递 return_all_codes = True
quantized, indices, commit_loss, all_codes = residual_vq(x, return_all_codes = True)
# (8, 1, 1024, 256)
此外,这篇论文使用残差向量量化(Residual-VQ)构建RQ-VAE,以更压缩的代码生成高分辨率图像。
他们做了两个修改。第一个是共享所有量化器的码本。第二个是随机采样代码,而不是总是取最接近的匹配项。你可以通过两个额外的关键字参数使用这两个功能。
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ(
dim = 256,
num_quantizers = 8,
codebook_size = 1024,
stochastic_sample_codes = True,
sample_codebook_temp = 0.1, # 随机采样代码的温度,0意味着非随机
shared_codebook = True # 是否共享所有量化器的码本
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = residual_vq(x)
# (1, 1024, 256), (1, 1024, 8), (1, 8)
最近的一篇论文进一步提出对特征维度分组的残差向量量化,显示出与Encodec相当的结果,同时使用更少的码本。你可以通过导入GroupedResidualVQ来使用它。
import torch
from vector_quantize_pytorch import GroupedResidualVQ
residual_vq = GroupedResidualVQ(
dim = 256,
num_quantizers = 8, # 指定量化器的数量
groups = 2,
codebook_size = 1024, # 码本大小
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = residual_vq(x)
# (1, 1024, 256), (2, 1, 1024, 8), (2, 1, 8)
初始化
SoundStream论文提出码本应该由第一批的kmeans质心初始化。你可以通过在VectorQuantize或ResidualVQ类中设置一个标志kmeans_init = True来轻松开启此功能。
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ(
dim = 256,
codebook_size = 256,
num_quantizers = 4,
kmeans_init = True, # 设置为True
kmeans_iters = 10 # 初始化时计算码本质心的kmeans迭代次数
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = residual_vq(x)
# (1, 1024, 256), (1, 1024, 4), (1, 4)
增加码本的使用率
该库将包含一些来自各种论文的技术,以应对使用向量量化器时常见的“死”码本条目问题。
降低码本维度
改进VQGAN论文提出将码本保持在较低的维度。编码器值在量化前会被投影到较低维度,然后再投影回高维。你可以通过codebook_dim超参数设置这一点。
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize(
dim = 256,
codebook_size = 256,
codebook_dim = 16 # 论文建议设置为32或低至8以增加码本使用率
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = vq(x)
# (1, 1024, 256), (1, 1024), (1,)
余弦相似度
改进VQGAN论文还提出对代码和编码向量进行l2归一化,这相当于使用余弦相似度来计算距离。他们声称将向量强制在一个球上有助于增强码本使用率和下游重建。你可以通过设置use_cosine_sim = True开启此功能。
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize(
dim = 256,
codebook_size = 256,
use_cosine_sim = True # 设置为True
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = vq(x)
# (1, 1024, 256), (1, 1024), (1,)
过期的陈旧代码
最后,SoundStream论文有一个方案,他们用当前批次中随机选择的向量替换低于某个命中阈值的代码。你可以通过threshold_ema_dead_code关键字设置这个阈值。
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize(
dim = 256,
codebook_size = 512,
threshold_ema_dead_code = 2 # 应该积极替换指数移动平均簇大小小于2的代码
)
x = torch.randn(1, 1024, 256)
quantized, indices, commit_loss = vq(x)
# (1, 1024, 256), (1, 1024), (1,)
正交正则化损失
向量量化自动编码器(VQ-VAE)/向量量化生成对抗网络(VQ-GAN)正在迅速流行。最近的一篇论文提出,当对图像使用向量量化时,强制码本为正交可以让离散代码实现平移等效性,从而大大改善下游的文本到图像生成任务。
你可以通过简单地将orthogonal_reg_weight设置为大于0来使用此功能,这样正交正则化将被添加到模块输出的辅助损失中。
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize(
dim = 256,
codebook_size = 256,
accept_image_fmap = True, # 设置为True以能够传递图像特征图
orthogonal_reg_weight = 10, # 论文中建议值为10
orthogonal_reg_max_codes = 128, # 这将随机从码本中采样以用于正交正则化损失,以限制内存使用
orthogonal_reg_active_codes_only = False # 如果你有一个非常大的码本,并且只希望对每批激活的代码强制该损失,则设置为True
)
img_fmap = torch.randn(1, 256, 32, 32)
quantized, indices, loss = vq(img_fmap) # (1, 256, 32, 32), (1, 32, 32), (1,)
# 损失现在包含正交正则化损失及其分配的权重
多头向量量化
有许多论文提出了具有多头方法的离散潜在表示变体(每个特征多个代码)。我决定提供一个变体,其中相同的码本用于跨输入维度head次向量量化。
你还可以使用一种更成熟的方法(memcodes),来自NWT论文
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize(
dim = 256,
codebook_dim = 32, # 许多论文显示较小的码本维度是可接受的
heads = 8, # 向量量化的头数量,共享码本
separate_codebook_per_head = True, # 是否为每个头设置单独的码本。False意味着共享一个码本
codebook_size = 8196,
accept_image_fmap = True
)
img_fmap = torch.randn(1, 256, 32, 32)
quantized, indices, loss = vq(img_fmap)
# (1, 256, 32, 32), (1, 32, 32, 8), (1,)
随机投影量化器
这篇论文首先提出使用随机投影量化器进行掩码语音建模,其中信号用随机初始化的矩阵投影,然后与随机初始化的码本匹配。因此不需要学习量化器。谷歌的通用语音模型(USM)使用这种技术在语音到文本建模中达到最新的技术水平。
USM进一步提出使用多个码本,并采用具有多重softmax目标的掩码语音建模。您可以简单地通过将num_codebooks设置为大于1来实现此功能。
import torch
from vector_quantize_pytorch import RandomProjectionQuantizer
quantizer = RandomProjectionQuantizer(
dim = 512, # 输入维度
num_codebooks = 16, # 在USM中,他们使用了最多16个码本以获得5%的提升
codebook_dim = 256, # 码本维度
codebook_size = 1024 # 码本大小
)
x = torch.randn(1, 1024, 512)
indices = quantizer(x)
# (1, 1024, 16)
该仓库还应该自动同步多进程环境中的码本。如果没有,请提交问题。您可以通过设置sync_codebook为 True | False 来覆盖是否同步码本。
有限标量量化
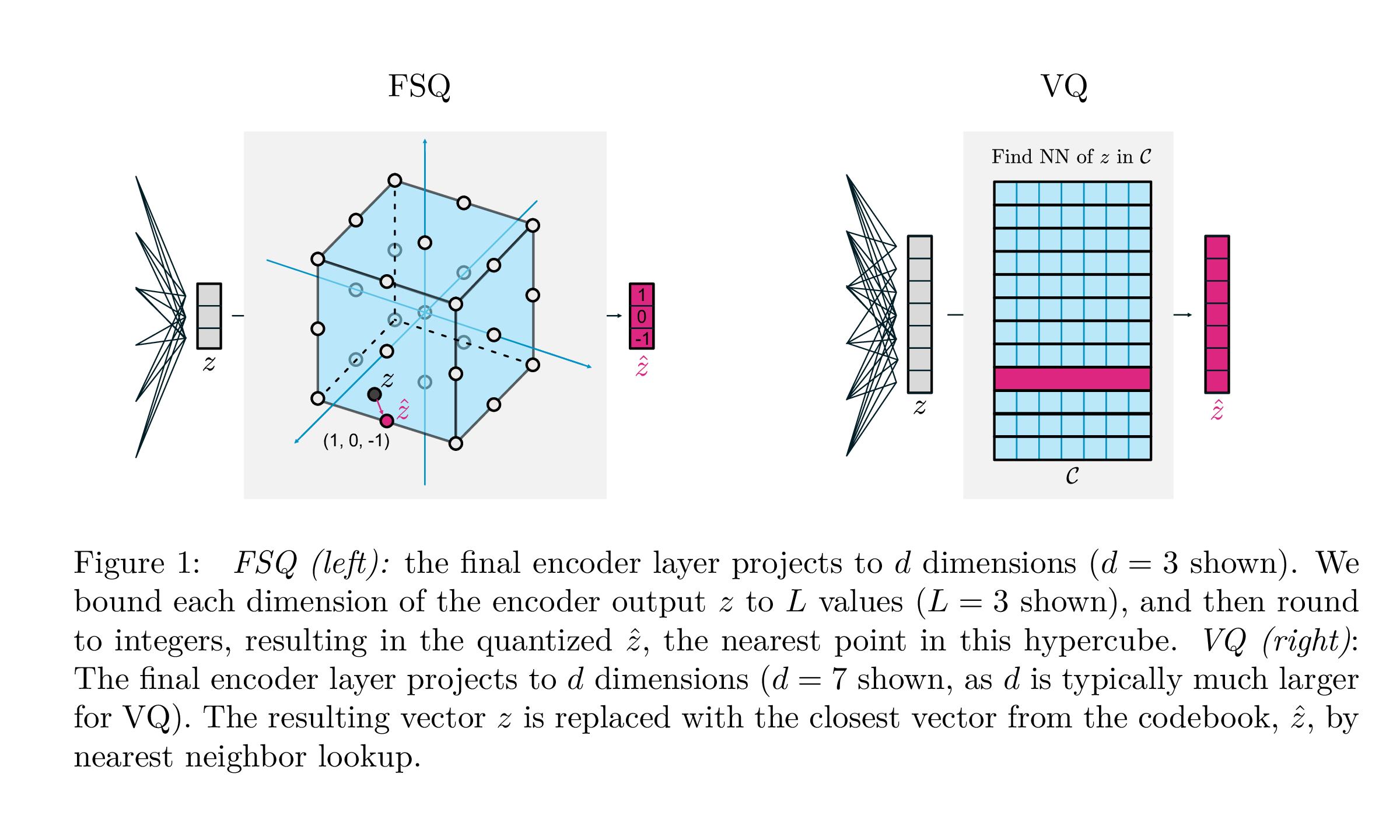
| VQ | FSQ | |
|---|---|---|
| 量化 | argmin_c || z-c || | round(f(z)) |
| 梯度 | 直接估计法 (STE) | STE |
| 辅助损失 | 承诺、码本、熵损失等 | N/A |
| 技巧 | 码本的EMA,码本拆分,投影等 | N/A |
| 参数 | 码本 | N/A |
这项来自Google Deepmind的工作旨在极大地简化用于生成建模的矢量量化方法,消除承诺损失、码本的EMA更新,以及解决码本崩溃或利用率不足的问题。他们采用将每个标量舍入到离散级别的直接梯度法;代码变为超立方体中的均匀点。
感谢@sekstini在创纪录的时间内移植了此实现!
import torch
from vector_quantize_pytorch import FSQ
quantizer = FSQ(
levels = [8, 5, 5, 5]
)
x = torch.randn(1, 1024, 4) # 4是因为有4个级别
xhat, indices = quantizer(x)
# (1, 1024, 4), (1, 1024)
assert torch.all(xhat == quantizer.indices_to_codes(indices))
一个改进的Residual FSQ,用于尝试改进音频编码。
import torch
from vector_quantize_pytorch import ResidualFSQ
residual_fsq = ResidualFSQ(
dim = 256,
levels = [8, 5, 5, 3],
num_quantizers = 8
)
x = torch.randn(1, 1024, 256)
residual_fsq.eval()
quantized, indices = residual_fsq(x)
# (1, 1024, 256), (1, 1024, 8)
quantized_out = residual_fsq.get_output_from_indices(indices)
# (1, 1024, 256)
assert torch.all(quantized == quantized_out)
无查表量化
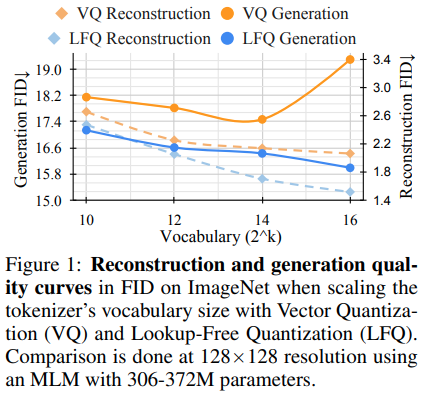
MagViT背后的研究团队发布了新的SOTA生成视频建模结果。v1和v2之间的核心变化包括一种新类型的量化,无查表量化(LFQ),彻底消除了码本和嵌入查找。
本文提出了使用独立二进制潜变量的简单LFQ量化器。其他实现的LFQ也存在。然而,团队表明,使用LFQ的MAGVIT-v2在ImageNet基准上显著提升。 LFQ和2级FSQ之间的差异包括熵正则化以及承诺损失的维持。
开发一种没有码本查找的更先进的LFQ量化方法可能会彻底改变生成建模。
您可以按如下方式简单使用。在MagViT2 pytorch port上试用。
import torch
from vector_quantize_pytorch import LFQ
# 您可以指定dim或codebook_size
# 如果两者都指定,将相互验证
quantizer = LFQ(
codebook_size = 65536, # 码本大小,必须为2的幂
dim = 16, # 输入特征尺寸,默认为log2(码本大小)如果未定义
entropy_loss_weight = 0.1, # 熵损失的权重
diversity_gamma = 1. # 熵损失中代码多样性的权重,来源于https://arxiv.org/abs/1911.05894
)
image_feats = torch.randn(1, 16, 32, 32)
quantized, indices, entropy_aux_loss = quantizer(image_feats, inv_temperature=100.) # 您可能需要尝试温度
# (1, 16, 32, 32), (1, 32, 32), ()
assert (quantized == quantizer.indices_to_codes(indices)).all()
您还可以传入视频特征,格式为 (batch, feat, time, height, width) 或序列,格式为(batch, seq, feat)
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ(
codebook_size = 65536,
dim = 16,
entropy_loss_weight = 0.1,
diversity_gamma = 1.
)
seq = torch.randn(1, 32, 16)
quantized, *_ = quantizer(seq)
assert seq.shape == quantized.shape
video_feats = torch.randn(1, 16, 10, 32, 32)
quantized, *_ = quantizer(video_feats)
assert video_feats.shape == quantized.shape
或支持多个码本
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ(
codebook_size = 4096,
dim = 16,
num_codebooks = 4 # 4个码本,总码本维度为log2(4096) * 4
)
image_feats = torch.randn(1, 16, 32, 32)
quantized, indices, entropy_aux_loss = quantizer(image_feats)
# (1, 16, 32, 32), (1, 32, 32, 4), ()
assert image_feats.shape == quantized.shape
assert (quantized == quantizer.indices_to_codes(indices)).all()
一个改进的Residual LFQ,看看是否可以改进音频压缩。
import torch
from vector_quantize_pytorch import ResidualLFQ
residual_lfq = ResidualLFQ(
dim = 256,
codebook_size = 256,
num_quantizers = 8
)
x = torch.randn(1, 1024, 256)
residual_lfq.eval()
quantized, indices, commit_loss = residual_lfq(x)
# (1, 1024, 256), (1, 1024, 8), (8)
quantized_out = residual_lfq.get_output_from_indices(indices)
# (1, 1024, 256)
assert torch.all(quantized == quantized_out)
潜变量量化
解构对表示学习至关重要,因为它促进了可解释性、泛化性、改进学习和健壮性。这与抓住数据有意义和独立特征的目标一致,促进了在各种应用中更有效地使用学习的表示。为了更好的解构,挑战在于在没有明确的地面实况信息的情况下解构数据集中潜在的变化。这项工作引入了一种关键的归纳偏置,旨在在一个有组织的潜在空间中进行编码和解码。该策略包括通过利用每个维度的单个可学习标量码本来离散化潜在空间。此方法能够使他们的模型有效地超越强大的先前方法。
请注意,他们必须在本文中使用非常高的权重衰减。
import torch
from vector_quantize_pytorch import LatentQuantize
# 您可以指定dim或codebook_size
# 如果两者都指定,将相互验证
quantizer = LatentQuantize(
levels = [5, 5, 8], # 每个码本维度的级别数
dim = 16, # 输入维度
commitment_loss_weight=0.1,
quantization_loss_weight=0.1,
)
image_feats = torch.randn(1, 16, 32, 32)
quantized, indices, loss = quantizer(image_feats)
# (1, 16, 32, 32), (1, 32, 32), ()
assert image_feats.shape == quantized.shape
assert (quantized == quantizer.indices_to_codes(indices)).all()
您还可以传入视频特征,格式为 (batch, feat, time, height, width) 或序列,格式为(batch, seq, feat)
import torch
from vector_quantize_pytorch import LatentQuantize
quantizer = LatentQuantize(
levels = [5, 5, 8],
dim = 16,
commitment_loss_weight=0.1,
quantization_loss_weight=0.1,
)
seq = torch.randn(1, 32, 16)
quantized, *_ = quantizer(seq)
# (1, 32, 16)
video_feats = torch.randn(1, 16, 10, 32, 32)
quantized, *_ = quantizer(video_feats)
# (1, 16, 10, 32, 32)
或支持多个码本
import torch
from vector_quantize_pytorch import LatentQuantize
model = LatentQuantize(
levels = [4, 8, 16],
dim = 9,
num_codebooks = 3
)
input_tensor = torch.randn(2, 3, dim)
output_tensor, indices, loss = model(input_tensor)
# (2, 3, 9), (2, 3, 3), ()
assert output_tensor.shape == input_tensor.shape
assert indices.shape == (2, 3, num_codebooks)
assert loss.item() >= 0
引用
@misc{oord2018neural,
title = {Neural Discrete Representation Learning},
author = {Aaron van den Oord and Oriol Vinyals and Koray Kavukcuoglu},
year = {2018},
eprint = {1711.00937},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@misc{zeghidour2021soundstream,
title = {SoundStream: An End-to-End Neural Audio Codec},
author = {Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi},
year = {2021},
eprint = {2107.03312},
archivePrefix = {arXiv},
primaryClass = {cs.SD}
}
@inproceedings{anonymous2022vectorquantized,
title = {Vector-quantized Image Modeling with Improved {VQGAN}},
author = {Anonymous},
booktitle = {Submitted to The Tenth International Conference on Learning Representations },
year = {2022},
url = {https://openreview.net/forum?id=pfNyExj7z2},
note = {under review}
}
@inproceedings{lee2022autoregressive,
title={Autoregressive Image Generation using Residual Quantization},
author={Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={11523--11532},
year={2022}
}
@article{Defossez2022HighFN,
title = {High Fidelity Neural Audio Compression},
author = {Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi},
journal = {ArXiv},
year = {2022},
volume = {abs/2210.13438}
}
@inproceedings{Chiu2022SelfsupervisedLW,
title = {Self-supervised Learning with Random-projection Quantizer for Speech Recognition},
author = {Chung-Cheng Chiu and James Qin and Yu Zhang and Jiahui Yu and Yonghui Wu},
booktitle = {International Conference on Machine Learning},
year = {2022}
}
@inproceedings{Zhang2023GoogleUS,
title = {Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages},
author = {Yu Zhang and Wei Han and James Qin and Yongqiang Wang and Ankur Bapna and Zhehuai Chen and Nanxin Chen and Bo Li and Vera Axelrod and Gary Wang and Zhong Meng and Ke Hu and Andrew Rosenberg and Rohit Prabhavalkar and Daniel S. Park and Parisa Haghani and Jason Riesa and Ginger Perng and Hagen Soltau and Trevor Strohman and Bhuvana Ramabhadran and Tara N. Sainath and Pedro J. Moreno and Chung-Cheng Chiu and Johan Schalkwyk and Franccoise Beaufays and Yonghui Wu},
year = {2023}
}
@inproceedings{Shen2023NaturalSpeech2L,
title = {NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers},
author = {Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian},
year = {2023}
}
@inproceedings{Yang2023HiFiCodecGV,
title = {HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec},
author = {Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou},
year = {2023}
}
@article{Liu2023BridgingDA,
title = {Bridging Discrete and Backpropagation: Straight-Through and Beyond},
author = {Liyuan Liu and Chengyu Dong and Xiaodong Liu and Bin Yu and Jianfeng Gao},
journal = {ArXiv},
year = {2023},
volume = {abs/2304.08612}
}
@inproceedings{huh2023improvedvqste,
title = {Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks},
author = {Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip},
booktitle = {International Conference on Machine Learning},
year = {2023},
organization = {PMLR}
}
@inproceedings{rogozhnikov2022einops,
title = {Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation},
author = {Alex Rogozhnikov},
booktitle = {International Conference on Learning Representations},
year = {2022},
url = {https://openreview.net/forum?id=oapKSVM2bcj}
}
@misc{shin2021translationequivariant,
title = {Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation},
author = {Woncheol Shin and Gyubok Lee and Jiyoung Lee and Joonseok Lee and Edward Choi},
year = {2021},
eprint = {2112.00384},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{mentzer2023finite,
title = {Finite Scalar Quantization: VQ-VAE Made Simple},
author = {Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen},
year = {2023},
eprint = {2309.15505},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{yu2023language,
title = {Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation},
author = {Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang},
year = {2023},
eprint = {2310.05737},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@inproceedings{Zhao2024ImageAV,
title = {Image and Video Tokenization with Binary Spherical Quantization},
author = {Yue Zhao and Yuanjun Xiong and Philipp Krahenbuhl},
year = {2024},
url = {https://api.semanticscholar.org/CorpusID:270380237}
}
@misc{hsu2023disentanglement,
title = {Disentanglement via Latent Quantization},
author = {Kyle Hsu and Will Dorrell and James C. R. Whittington and Jiajun Wu and Chelsea Finn},
year = {2023},
eprint = {2305.18378},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@inproceedings{Irie2023SelfOrganisingND,
title = {Self-Organising Neural Discrete Representation Learning \`a la Kohonen},
author = {Kazuki Irie and R'obert Csord'as and J{\"u}rgen Schmidhuber},
year = {2023},
url = {https://api.semanticscholar.org/CorpusID:256901024}
}











