
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文通过奖励梯度进行视频扩散对齐
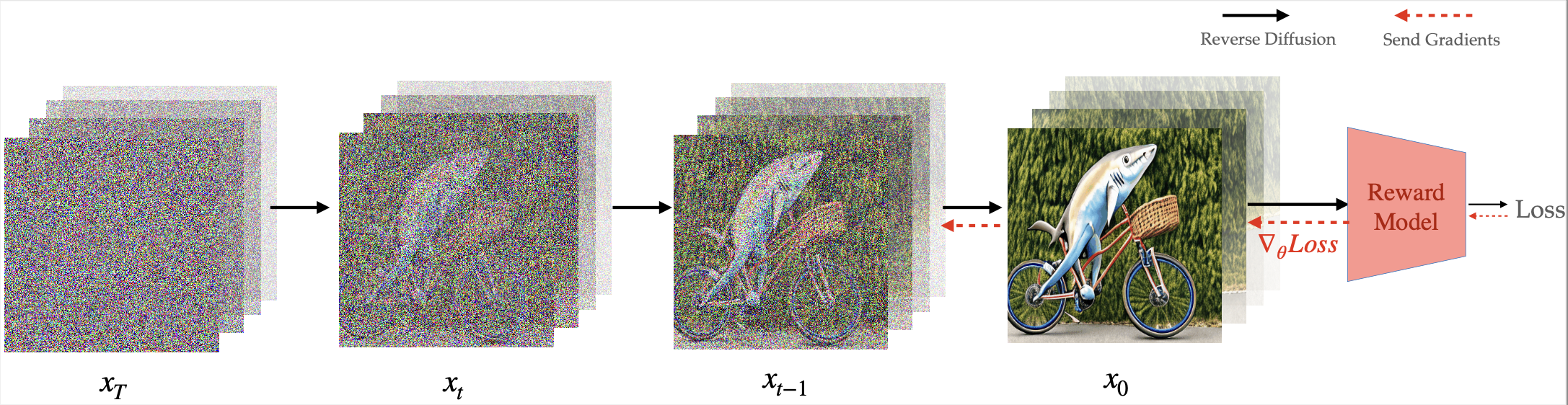


这是我们论文通过奖励梯度进行视频扩散对齐的官方实现,作者为
Mihir Prabhudesai*、Russell Mendonca*、Zheyang Qin*、Katerina Fragkiadaki、Deepak Pathak。
摘要
我们在构建基础视频扩散模型方面取得了重大进展。由于这些模型是使用大规模无监督数据进行训练的,因此将这些模型适应特定的下游任务(如视频-文本对齐或道德视频生成)变得至关重要。通过监督微调来适应这些模型需要收集目标视频数据集,这是具有挑战性且繁琐的。在本研究中,我们转而利用通过强大判别模型上的偏好学习得到的预训练奖励模型。这些模型包含与生成的RGB像素相关的密集梯度信息,这对于在复杂搜索空间(如视频)中高效学习至关重要。我们展示了我们的方法可以实现视频扩散的对齐,用于美学生成、文本上下文与视频之间的相似性,以及长度是训练序列长度3倍的长时间跨度视频生成。我们证明,与之前用于视频生成的无梯度方法相比,我们的方法在奖励查询和计算效率方面都能更高效地学习。
特性
- 适配VideoCrafter2文本到视频模型
- 适配Open-Sora V1.2文本到视频模型
- 适配ModelScope文本到视频模型
- 适配Stable Video Diffusion图像到视频模型
演示
 |  |  |
 |  |  |
 |  |  |
🌟 VADER-VideoCrafter
我们强烈建议首先使用VADER-VideoCrafter模型,因为它的表现更好。
⚙️ 安装
假设您位于VADER/目录中,您可以使用以下命令为VADER-VideoCrafter创建Conda环境:
cd VADER-VideoCrafter
conda create -n vader_videocrafter python=3.10
conda activate vader_videocrafter
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=12.1 -c pytorch -c nvidia
conda install xformers -c xformers
pip install -r requirements.txt
git clone https://github.com/tgxs002/HPSv2.git
cd HPSv2/
pip install -e .
cd ..
- 我们通过Hugging Face使用预训练的文本到视频VideoCrafter2模型。如果您不幸发现在运行推理或训练脚本时模型没有自动下载,您可以手动下载并将
model.ckpt放在VADER/VADER-VideoCrafter/checkpoints/base_512_v2/model.ckpt中。 - 我们在 HuggingFace 上提供了预训练的 LoRA 权重。
vader_videocrafter_pickscore.pt是使用 PickScore 函数在 chatgpt_custom_animal.txt 上微调的模型,LoRA 秩为 16,而vader_videocrafter_hps_aesthetic.pt是使用 HPSv2.1 和 Aesthetic 函数组合在 chatgpt_custom_instruments.txt 上微调的模型,LoRA 秩为 8。
📺 推理
请首先运行 accelerate config 来配置加速器设置。如果您不熟悉加速器配置,可以参考 VADER-VideoCrafter 文档。
假设您位于 VADER/ 目录下,您可以使用以下命令进行推理:
cd VADER-VideoCrafter
sh scripts/run_text2video_inference.sh
- 我们已在 PyTorch 2.3.0 和 CUDA 12.1 上进行了测试。当我们设置
val_batch_size=1并使用fp16混合精度时,推理脚本可以在单个具有 16GB VRAM 的 GPU 上运行。它应该也适用于最新的 PyTorch 和 CUDA 版本。 VADER/VADER-VideoCrafter/scripts/main/train_t2v_lora.py是通过 LoRA 使用 VADER 进行 VideoCrafter2 推理的脚本。- 大多数参数与训练过程相同。主要区别是
--inference_only应设置为True。 --lora_ckpt_path需要设置为预训练 LoRA 模型的路径。特别地,如果lora_ckpt_path设置为'huggingface-pickscore'或'huggingface-hps-aesthetic',它将从相应的 HuggingFace 模型库下载预训练的 LoRA 模型,VADER_VideoCrafter_PickScore 或 VADER_VideoCrafter_HPS_Aesthetic。否则,它将从您提供的路径加载预训练的 LoRA 模型。如果您未提供任何lora_ckpt_path,将使用原始 VideoCrafter2 模型进行推理。注意,如果您使用'huggingface-pickscore',需要设置--lora_rank 16,而如果使用'huggingface-hps-aesthetic',需要设置--lora_rank 8。
- 大多数参数与训练过程相同。主要区别是
🔧 训练
请首先运行 accelerate config 来配置加速器设置。如果您不熟悉加速器配置,可以参考 VADER-VideoCrafter 文档。
假设您位于 VADER/ 目录下,您可以使用以下命令训练模型:
cd VADER-VideoCrafter
sh scripts/run_text2video_train.sh
- 我们的实验在 PyTorch 2.3.0 和 CUDA 12.1 上进行,使用 4 个 A6000 (48GB RAM)。它应该也适用于最新的 PyTorch 和 CUDA 版本。当我们设置
train_batch_size=1 val_batch_size=1并使用fp16混合精度时,训练脚本已在单个具有 16GB VRAM 的 GPU 上进行了测试。 VADER/VADER-VideoCrafter/scripts/main/train_t2v_lora.py也是通过 LoRA 使用 VADER 微调 VideoCrafter2 的脚本。- 您可以阅读 VADER-VideoCrafter 文档 来了解参数的使用。
🎬 VADER-Open-Sora
⚙️ 安装
假设您位于 VADER/ 目录下,您可以使用以下命令为 VADER-Open-Sora 创建 Conda 环境:
cd VADER-Open-Sora
conda create -n vader_opensora python=3.10
conda activate vader_opensora
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=12.1 -c pytorch -c nvidia
conda install xformers -c xformers
pip install -v -e .
git clone https://github.com/tgxs002/HPSv2.git
cd HPSv2/
pip install -e .
cd ..
📺 推理
请首先运行 accelerate config 来配置加速器设置。如果您不熟悉加速器配置,可以参考 VADER-Open-Sora 文档。
假设你在 VADER/ 目录下,你可以使用以下命令进行推理:
cd VADER-Open-Sora
sh scripts/run_text2video_inference.sh
- 我们在 PyTorch 2.3.0 和 CUDA 12.1 上进行了测试。如果
resolution设置为360p,当我们设置val_batch_size=1并使用bf16混合精度时,需要一个 40GB 显存的 GPU。它也应该适用于最新的 PyTorch 和 CUDA 版本。有关 GPU 要求和模型设置的更多详细信息,请参阅原始 Open-Sora 仓库。 VADER/VADER-Open-Sora/scripts/train_t2v_lora.py是一个使用 VADER 通过 Open-Sora 1.2 进行推理的脚本。--num-frames、'--resolution'、'fps'和'aspect-ratio'是从原始 Open-Sora 模型继承的。简而言之,你可以将'--num-frames'设置为'2s'、'4s'、'8s'和'16s'。--resolution可用的值有'240p'、'360p'、'480p'和'720p'。'fps'的默认值是24,'aspect-ratio'的默认值是3:4。更多详细信息请参阅原始 Open-Sora 仓库。需要注意的一点是,例如,如果你将--num-frames设置为2s并将--resolution设置为'240p',最好使用bf16混合精度而不是fp16。否则,模型可能会生成噪声视频。--prompt-path是提示文件的路径。与 VideoCrafter 不同,我们不为 Open-Sora 提供提示功能。相反,你可以提供一个包含提示列表的提示文件。--num-processes是 Accelerator 的进程数。建议将其设置为 GPU 的数量。
VADER/VADER-Open-Sora/configs/opensora-v1-2/vader/vader_inferece.py是推理的配置文件。你可以按照文档中的指导修改配置文件以更改推理设置。- 主要区别是
is_vader_training应设置为False。--lora_ckpt_path应设置为预训练 LoRA 模型的路径。否则,将使用原始 Open-Sora 模型进行推理。
- 主要区别是
🔧 训练
请先运行 accelerate config 来配置加速器设置。如果你不熟悉加速器配置,可以参考 VADER-Open-Sora 文档。
假设你在 VADER/ 目录下,你可以使用以下命令训练模型:
cd VADER-Open-Sora
sh scripts/run_text2video_train.sh
- 我们的实验在 PyTorch 2.3.0 和 CUDA 12.1 上进行,使用 4 个 A6000(48GB RAM)。它也应该适用于最新的 PyTorch 和 CUDA 版本。当使用
bf16混合精度,resolution设置为360p,num_frames设置为2s时,微调模型需要 48GB 显存的 GPU。 VADER/VADER-Open-Sora/scripts/train_t2v_lora.py是通过 LoRA 使用 VADER 微调 Open-Sora 1.2 的脚本。- 参数与上面的推理过程相同。
VADER/VADER-Open-Sora/configs/opensora-v1-2/vader/vader_train.py是训练的配置文件。你可以修改配置文件以更改训练设置。- 你可以阅读 VADER-Open-Sora 文档来了解参数的使用。
🎥 ModelScope
⚙️ 安装
假设你在 VADER/ 目录下,你可以使用以下命令为 VADER-ModelScope 创建 Conda 环境:
cd VADER-ModelScope
conda create -n vader_modelscope python=3.10
conda activate vader_modelscope
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=12.1 -c pytorch -c nvidia
conda install xformers -c xformers
pip install -r requirements.txt
git clone https://github.com/tgxs002/HPSv2.git
cd HPSv2/
pip install -e .
cd ..
📺 推理
请先运行 accelerate config 来配置加速器设置。如果你不熟悉加速器配置,可以参考 VADER-ModelScope 文档。
假设你在 VADER/ 目录下,你可以使用以下命令进行推理:
cd VADER-ModelScope
sh run_text2video_inference.sh
- 当前代码可以在显存大于 14GB 的单个 GPU 上运行。
- 注意:我们在原始推理脚本中没有设置
lora_path。如果你有预训练的 LoRA 模型,你可以将lora_path设置为该模型的路径。
🔧 训练
请先运行 accelerate config 来配置加速器设置。如果你不熟悉加速器配置,可以参考 VADER-ModelScope 文档。
假设您位于VADER/目录下,您可以使用以下命令来训练模型:
cd VADER-ModelScope
sh run_text2video_train.sh
- 当前代码可以在VRAM大于14GB的单个GPU上运行。通过使用deepspeed和CPU卸载,代码可以进一步优化以适应更小的VRAM。在我们的实验中,我们使用了4个A100-40GB RAM来运行我们的代码。
VADER/VADER-ModelScope/train_t2v_lora.py是一个通过LoRA使用VADER对ModelScope进行微调的脚本。- 可以增加
gradient_accumulation_steps的同时减少加速器的--num_processes,以缓解GPU数量造成的瓶颈。我们在4个A100-40GB RAM上测试了gradient_accumulation_steps=4和--num_processes=4。 prompt_fn是提示函数,可以是Core/prompts.py中任何函数的名称,如'chatgpt_custom_instruments'、'chatgpt_custom_animal_technology'、'chatgpt_custom_ice'、'nouns_activities'等。注意:如果您设置--prompt_fn 'nouns_activities',您必须提供--nouns_file和--nouns_file,它们将从文件中随机选择一个名词和一个活动,并将它们组合成一个句子作为提示。reward_fn是奖励函数,可以从'aesthetic'、'hps'和'actpred'中选择。
- 可以增加
VADER/VADER-ModelScope/config_t2v/config.yaml是训练的配置文件。您可以按照该文件中的注释修改配置文件以更改训练设置。
💡 教程
本节提供一个教程,指导您如何在VideoCrafter和Open-Sora上自行实现VADER方法。我们将提供一步步的指南,帮助您理解修改细节。这样,您就可以轻松地将VADER方法适配到VideCrafter的后续版本。
- 请参考VideoCrafter教程
- 请参考Open-Sora教程
致谢
我们的代码库直接基于VideoCrafter、Open-Sora和Animate Anything构建。我们要感谢这些作者开源他们的代码。
引用
如果您在研究中发现这项工作有用,请引用:
@misc{prabhudesai2024videodiffusionalignmentreward,
title={Video Diffusion Alignment via Reward Gradients},
author={Mihir Prabhudesai and Russell Mendonca and Zheyang Qin and Katerina Fragkiadaki and Deepak Pathak},
year={2024},
eprint={2407.08737},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.08737},
}











