







光学字符识别变得无缝且人人可及,由 TensorFlow 2 和 PyTorch 提供支持
您可以从此存储库中期待的内容:
- 从文档中高效解析文本信息(定位和识别每个单词)的方法
- 关于如何将其集成到您当前架构中的指导

快速浏览
获取预训练模型
在 docTR 中,端到端 OCR 是使用两阶段方法实现的:文本检测(定位单词),然后是文本识别(识别单词中的所有字符)。 因此,您可以从可用实现列表中选择文本检测的架构,以及文本识别的架构。
from doctr.models import ocr_predictor
model = ocr_predictor(det_arch='db_resnet50', reco_arch='crnn_vgg16_bn', pretrained=True)
读取文件
可以从 PDF 或图像中解释文档:
from doctr.io import DocumentFile
# PDF
pdf_doc = DocumentFile.from_pdf("path/to/your/doc.pdf")
# 图像
single_img_doc = DocumentFile.from_images("path/to/your/img.jpg")
# 网页(需要安装 `weasyprint`)
webpage_doc = DocumentFile.from_url("https://www.yoursite.com")
# 多页图像
multi_img_doc = DocumentFile.from_images(["path/to/page1.jpg", "path/to/page2.jpg"])
整合起来
让我们用默认的预训练模型做一个示例:
from doctr.io import DocumentFile
from doctr.models import ocr_predictor
model = ocr_predictor(pretrained=True)
# PDF
doc = DocumentFile.from_pdf("path/to/your/doc.pdf")
# 分析
result = model(doc)
处理旋转文档
如果您在包含旋转页面或多个方向盒子的页面上使用 docTR,您有多种选项来处理它:
-
如果您仅使用带有直线文字(水平、相同阅读方向)的直页面,请考虑将
assume_straight_boxes=True传递给 ocr_predictor。它会直接在页面上拟合直框并返回直框,这是最快的选项。 -
如果您希望预测器输出直框(无论页面的方向如何,最终定位将转换为直框),需要在预测器中传递
export_as_straight_boxes=True。否则,如果assume_straight_pages=False,它将返回旋转边界框(可能有 0° 的角度)。
如果两个选项都设置为 False,预测器将始终拟合并返回旋转框。
要解释模型的预测,可以如下交互式地可视化它们:
# 显示结果(需要安装 matplotlib 和 mplcursors)
result.show()

或者甚至从预测中重新构建原始文档:
import matplotlib.pyplot as plt
synthetic_pages = result.synthesize()
plt.imshow(synthetic_pages[0]); plt.axis('off'); plt.show()

ocr_predictor 返回一个具有嵌套结构的 Document 对象(包含 Page、Block、Line、Word、Artefact)。
要更好地了解我们的文档模型,请检查我们的文档:
您也可以将它们导出为嵌套字典格式,更适合 JSON 格式:
json_output = result.export()
使用 KIE 预测器
相比于 OCR 预测器,KIE 预测器更具灵活性,因为您的检测模型可以在文档中检测多个类别。例如,您可以有一个检测模型,在文档中仅检测日期和地址。
KIE 预测器使您可以使用具有多个类别的检测器与识别模型一起使用,并且为整个管道已经设置好。
from doctr.io import DocumentFile
from doctr.models import kie_predictor
# 模型
model = kie_predictor(det_arch='db_resnet50', reco_arch='crnn_vgg16_bn', pretrained=True)
# PDF
doc = DocumentFile.from_pdf("path/to/your/doc.pdf")
# 分析
result = model(doc)
predictions = result.pages[0].predictions
for class_name in predictions.keys():
list_predictions = predictions[class_name]
for prediction in list_predictions:
print(f"Prediction for {class_name}: {prediction}")
KIE 预测器的每页结果为字典格式,每个键代表一个类别名称,其值为该类别的预测结果。
如果您正在寻求来自 Mindee 团队的支持

安装
先决条件
安装 docTR 需要 Python 3.9(或更高版本)和 pip。
最新版本
然后,您可以使用 pypi 安装最新版本的包:
pip install python-doctr
:warning: 请注意,基本安装并不是独立安装的,因为它不提供深度学习框架,而深度学习框架是包运行所必需的。
我们尽量将框架特定的依赖项降至最低。您可以按如下所示安装框架特定的构建版本:
# 对于 TensorFlow
pip install "python-doctr[tf]"
# 对于 PyTorch
pip install "python-doctr[torch]"
# 可选的可视化、html 和 contrib 模块依赖项可以如下安装:
pip install "python-doctr[torch,viz,html,contib]"
对于带有 M1 芯片的 MacBook,您需要一些额外的软件包或特定版本:
- TensorFlow 2: metal 插件
- PyTorch: 版本 >= 1.12.0
开发者模式
或者,您可以从源代码安装,这将要求您安装 Git。 首先克隆项目存储库:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.
同样,如果您更愿意避免遗漏依赖项的风险,可以安装 TensorFlow 或 PyTorch 构建版本:
# 对于 TensorFlow
pip install -e doctr/.[tf]
# 对于 PyTorch
pip install -e doctr/.[torch]
模型架构
功劳归于原作者:此存储库实现了除其他之外来自已发表研究论文的架构。
文本检测
- DBNet: 基于可区分二值化的实时场景文本检测.
- LinkNet: LinkNet: 利用编码器表示的高效语义分割
- FAST: FAST: 具有极简内核表示的更快任意形状文本检测器
文本识别
- CRNN: 一个用于基于图像的序列识别的端到端可训练神经网络及其应用于场景文本识别.
- SAR: 展示、关注和阅读:一个简单且强大的不规则文本识别基线.
- MASTER: MASTER: 多方面非本地网络用于场景文本识别.
- ViTSTR: 用于快速高效场景文本识别的视觉变压器.
- PARSeq: 场景文本识别中的置换自回归序列模型.
更多内容
文档
完整的软件包文档可在这里获取,详细规格请参考。
演示应用
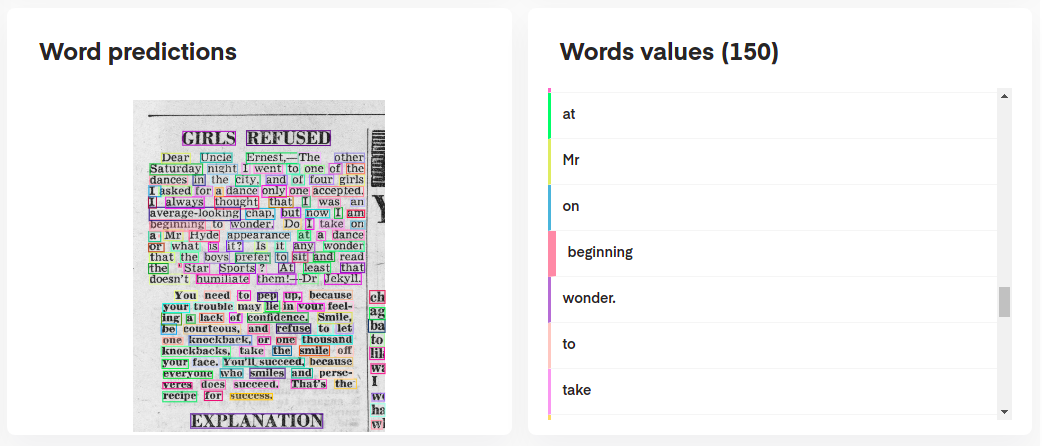
提供了一个极简演示应用程序,供您体验我们的端到端 OCR 模型!

现场演示
源自::hugs: Hugging Face :hugs:,docTR 现在在 Spaces 上提供了一个完全部署的版本!
查看此链接
本地运行
如果你更喜欢在本地使用它,需要额外依赖 (Streamlit)。
Tensorflow 版本
pip install -r demo/tf-requirements.txt
然后在默认浏览器中运行你的应用程序:
USE_TF=1 streamlit run demo/app.py
PyTorch 版本
pip install -r demo/pt-requirements.txt
然后在默认浏览器中运行你的应用程序:
USE_TORCH=1 streamlit run demo/app.py
TensorFlow.js
你更喜欢在网页浏览器中运行所有内容,而不是实际运行 Python 注释?查看我们的 TensorFlow.js demo 以开始使用!
Docker 容器
在 docTR Docker 镜像中使用 GPU
docTR Docker 镜像支持 GPU,并基于 CUDA 11.8。
然而,要使用这些 Docker 镜像的 GPU 支持,请确保 Docker 已配置为使用你的 GPU。
要验证和配置 Docker 的 GPU 支持,请按照 NVIDIA 容器工具包安装指南中的说明操作。
请配置 Docker 使用 GPU 后,可以运行支持 GPU 的 docTR Docker 容器:
docker run -it --gpus all ghcr.io/mindee/doctr:tf-py3.8.18-gpu-2023-09 bash
可用标签
docTR 的 Docker 镜像遵循特定的标签命名规则:<framework>-py<python_version>-<system>-<doctr_version|YYYY-MM>。以下是标签结构的细分:
<framework>:tf(TensorFlow)或torch(PyTorch)。<python_version>:3.8.18、3.9.18或3.10.13。<system>:cpu或gpu<doctr_version>:标签版本 >=v0.7.1<YYYY-MM>:例如2023-09
以下是不同镜像标签的示例:
| 标签 | 描述 |
|---|---|
tf-py3.8.18-cpu-v0.7.1 | TensorFlow 版本 3.8.18,docTR 版本 v0.7.1。 |
torch-py3.9.18-gpu-2023-09 | PyTorch 版本 3.9.18,支持 GPU,2023-09 每月一次构建。 |
本地构建 Docker 镜像
你也可以在本地计算机上构建 docTR Docker 镜像。
docker build -t doctr .
你可以使用构建参数指定自定义的 Python 版本和 docTR 版本。例如,构建一个 docTR 镜像使用 TensorFlow、Python 版本 3.9.10 和 docTR 版本 v0.7.0,运行以下命令:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .
示例脚本
提供了一个简单的文档分析的示例脚本,可用于 PDF 或图像文件:
python scripts/analyze.py path/to/your/doc.pdf
可以使用 python scripts/analyze.py --help 检查所有脚本参数。
最小的 API 集成
想将 docTR 集成到你的 API 中?这里有一个模板,使用优秀的 FastAPI 框架让你开始拥有一个完全可运行的 API。
本地部署 API
运行 API 模板需要特定依赖项,你可以按如下方式安装:
cd api/
pip install poetry
make lock
pip install -r requirements.txt
现在你可以在本地运行你的 API:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:app
或者,如果你更喜欢使用 Docker 容器,也可以使用:
PORT=8002 docker-compose up -d --build
你的部署内容
你的 API 现在应该在本地端口 8002 上运行。访问自动生成的文档:http://localhost:8002/redoc,并享受你的三个功能路线(“/detection”、“/recognition”、“/ocr”、“/kie”)。下面是一个使用 Python 发送请求到 OCR 路线的示例:
import requests
params = {"det_arch": "db_resnet50", "reco_arch": "crnn_vgg16_bn"}
with open('/path/to/your/doc.jpg', 'rb') as f:
files = [ # application/pdf, image/jpeg, image/png supported
("files", ("doc.jpg", f.read(), "image/jpeg")),
]
print(requests.post("http://localhost:8080/ocr", params=params, files=files).json())
示例笔记本
想了解更多 docTR 功能?你可能想看看设计来给你更广泛概述的 Jupyter 笔记本。
引用
如果你希望引用这个项目,请随意使用这个 BibTeX 引用:
@misc{doctr2021,
title={docTR: Document Text Recognition},
author={Mindee},
year={2021},
publisher = {GitHub},
howpublished = {\url{https://github.com/mindee/doctr}}
}
贡献
如果你滚动到这个部分,你很可能欣赏开源。你想扩展我们支持的字符范围吗?或者提交论文实现?还是以其他方式贡献?
你很幸运,我们为你编写了一份简短的指南 (见 CONTRIBUTING),让你可以轻松地做出贡献!
许可证
根据 Apache 2.0 许可证分发。有关更多信息,请参见 LICENSE。









