
LLM Scraper
LLM Scraper 是一个 TypeScript 库,允许你使用 LLM 从任何网页中提取结构化数据。
[!重要] 代码生成现在在 LLM Scraper 中支持。
[!提示] 在内部,它使用函数调用将页面转换为结构化数据。你可以在这里找到更多关于这种方法的信息。
功能
- 支持本地(Ollama,GGUF)、OpenAI、Vercel AI SDK 提供商
- 使用 Zod 定义的模式
- 完全类型安全的 TypeScript
- 基于 Playwright 框架
- 流对象
- 新功能 代码生成
- 支持四种格式模式:
html用于加载原始 HTMLmarkdown用于加载 markdowntext用于加载提取的文本(使用Readability.js)image用于加载截屏(仅限多模态)
确保给它一个星星!
入门
-
从 npm 安装所需的依赖项:
npm i zod playwright llm-scraper -
初始化你的 LLM:
OpenAI
npm i @ai-sdk/openaiimport { openai } from '@ai-sdk/openai' const llm = openai.chat('gpt-4o')Groq
npm i @ai-sdk/openaiimport { createOpenAI } from '@ai-sdk/openai' const groq = createOpenAI({ baseURL: 'https://api.groq.com/openai/v1', apiKey: process.env.GROQ_API_KEY, }) const llm = groq('llama3-8b-8192')Ollama
npm i ollama-ai-providerimport { ollama } from 'ollama-ai-provider' const llm = ollama('llama3')GGUF
import { LlamaModel } from 'node-llama-cpp' const llm = new LlamaModel({ modelPath: 'model.gguf' }) -
创建一个由 llm 提供的新 scraper 实例:
import LLMScraper from 'llm-scraper' const scraper = new LLMScraper(llm)
示例
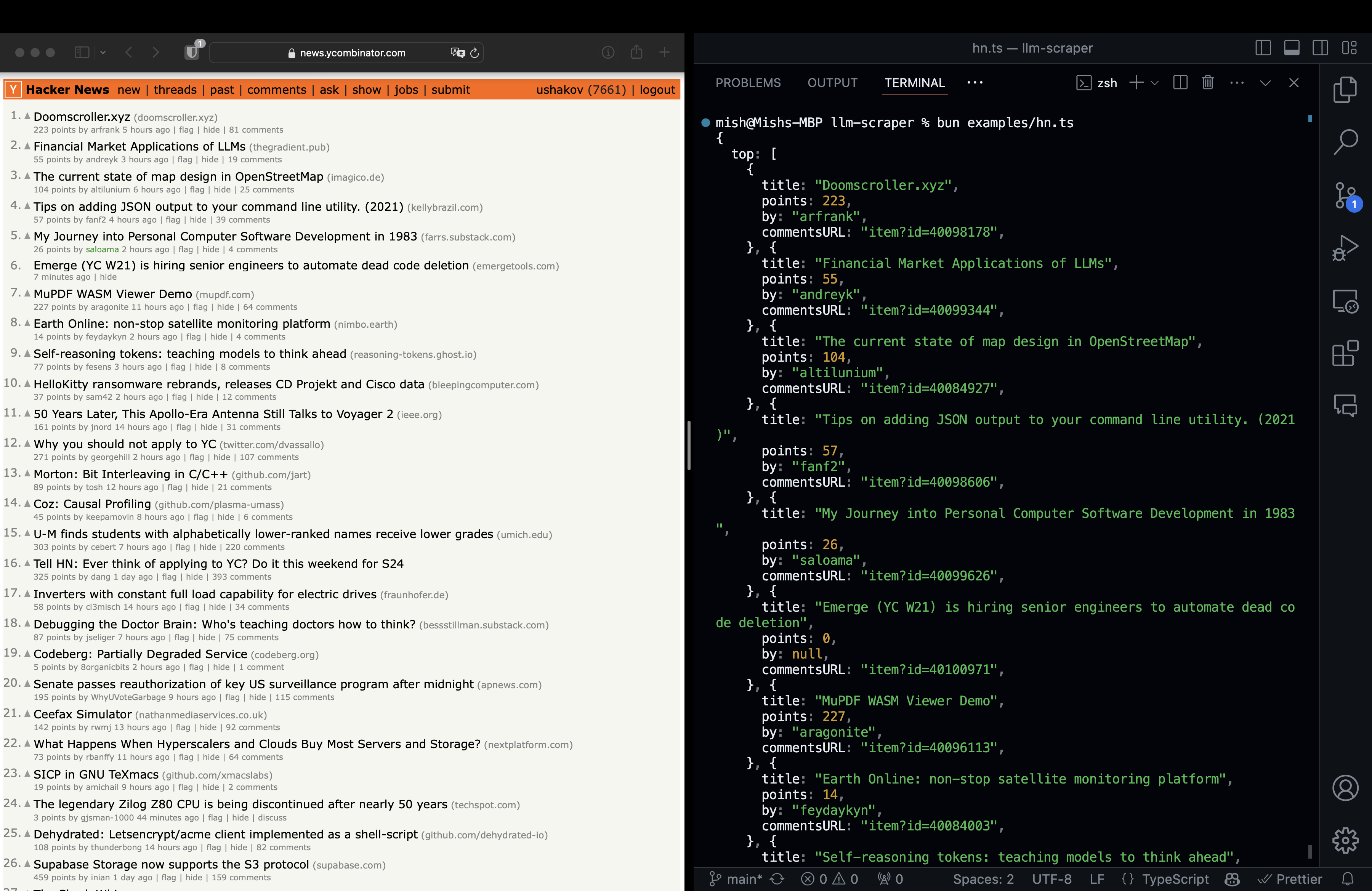
在此示例中,我们正在从 HackerNews 提取热门故事:
import { chromium } from 'playwright'
import { z } from 'zod'
import { openai } from '@ai-sdk/openai'
import LLMScraper from 'llm-scraper'
// 启动浏览器实例
const browser = await chromium.launch()
// 初始化 LLM 提供商
const llm = openai.chat('gpt-4o')
// 创建一个新的 LLMScraper
const scraper = new LLMScraper(llm)
// 打开新页面
const page = await browser.newPage()
await page.goto('https://news.ycombinator.com')
// 定义要提取内容的模式
const schema = z.object({
top: z
.array(
z.object({
title: z.string(),
points: z.number(),
by: z.string(),
commentsURL: z.string(),
})
)
.length(5)
.describe('Hacker News 上的前 5 个故事'),
})
// 运行 scraper
const { data } = await scraper.run(page, schema, {
format: 'html',
})
// 显示 LLM 的结果
console.log(data.top)
await page.close()
await browser.close()
流式传输
将你的run函数替换为stream以获取局部对象流(仅限 Vercel AI SDK)。
// 以流模式运行 scraper
const { stream } = await scraper.stream(page, schema)
// 从 LLM 流中读取结果
for await (const data of stream) {
console.log(data.top)
}
代码生成
使用generate函数,你可以生成可重复使用的 playwright 脚本,根据模式抓取内容。
// 生成代码并在页面上运行
const { code } = await scraper.generate(page, schema)
const result = await page.evaluate(code)
const data = schema.parse(result)
// 显示解析后的结果
console.log(data.news)
贡献
作为一个开源项目,我们欢迎社区的贡献。如果你遇到任何 bug 或想添加一些改进,请随时提出问题或拉取请求。














