
 Github
Github Huggingface
Huggingface
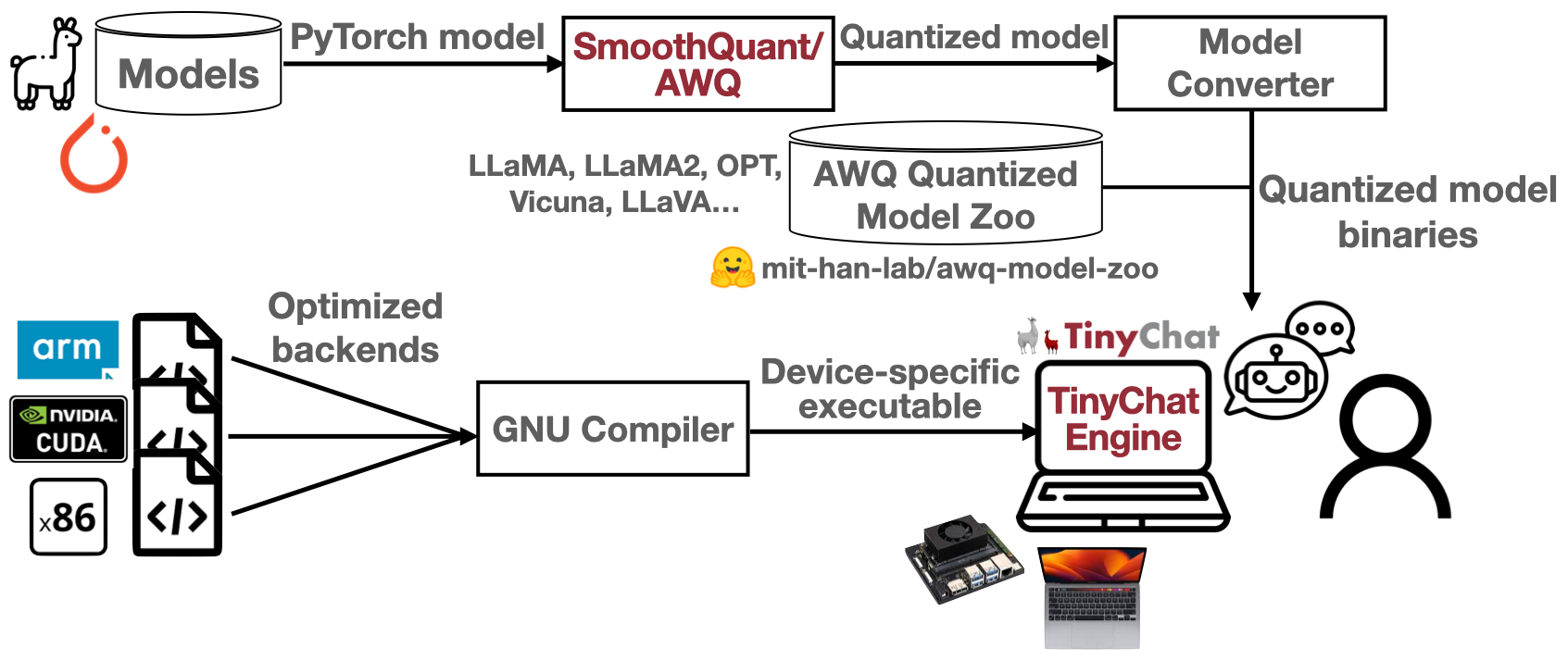
TinyChatEngine:设备端LLM/VLM推理库
在边缘设备上运行大型语言模型(LLMs)和视觉语言模型(VLMs)很有用:可以在笔记本电脑、汽车、机器人等设备上提供助手服务(编程、办公、智能回复)。用户可以获得即时响应,同时由于数据在本地,隐私保护更好。
这得益于LLM模型压缩技术:SmoothQuant和AWQ(激活感知权重量化),它们与实现压缩低精度模型的TinyChatEngine协同设计。
欢迎查看我们的幻灯片了解更多详情!
NVIDIA GeForce RTX 4070笔记本上的Code LLaMA演示:

Apple MacBook M1 Pro上的VILA演示:
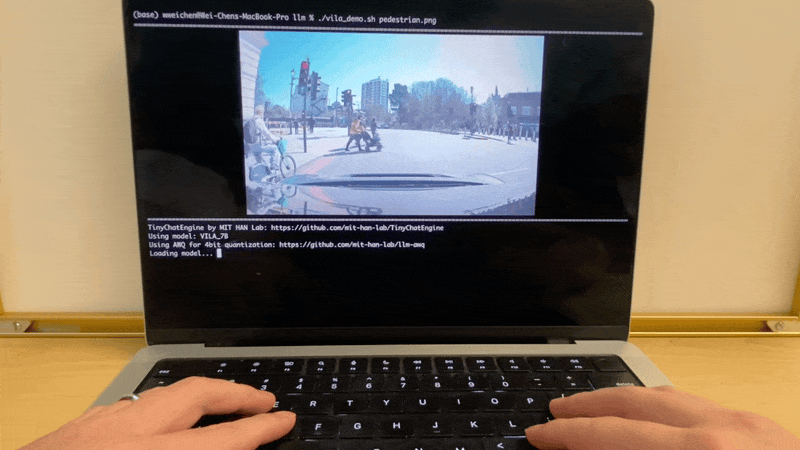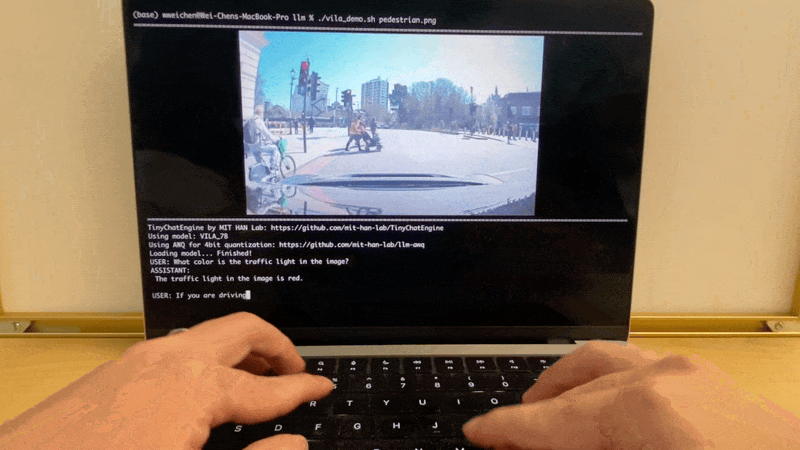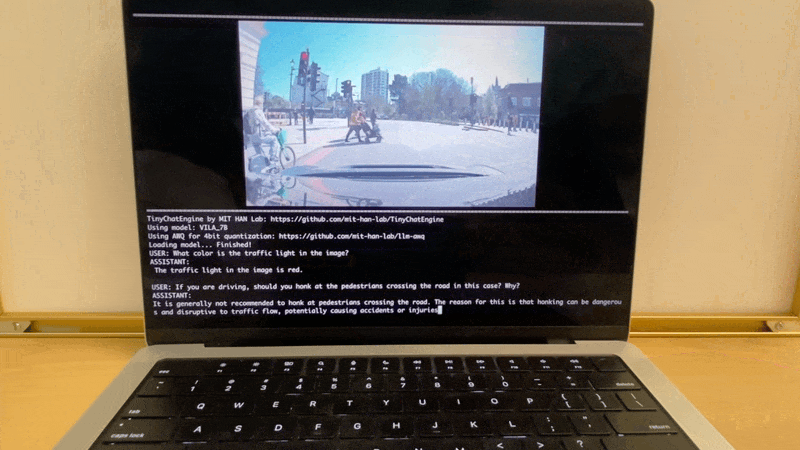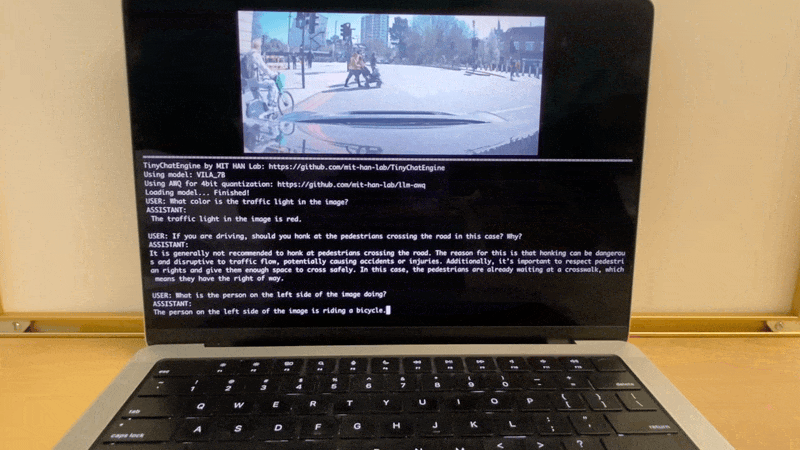
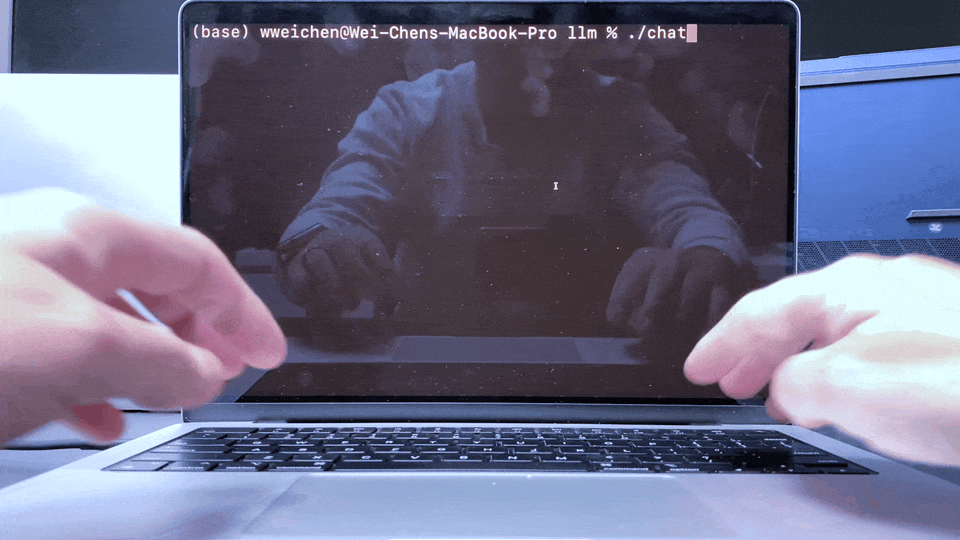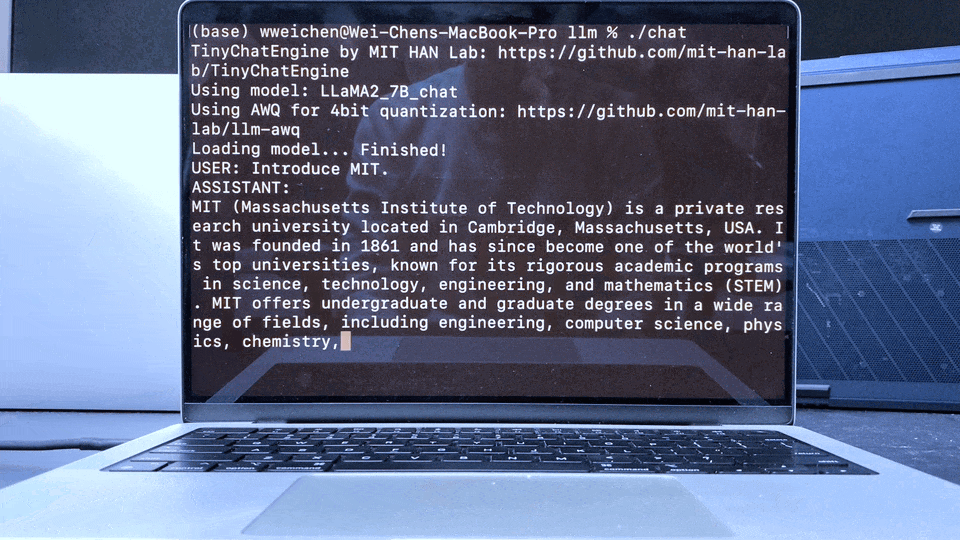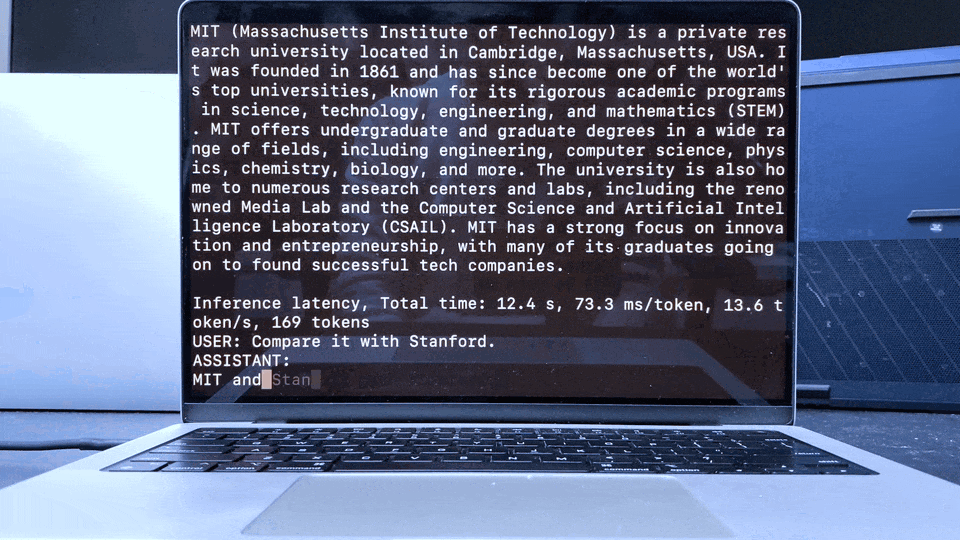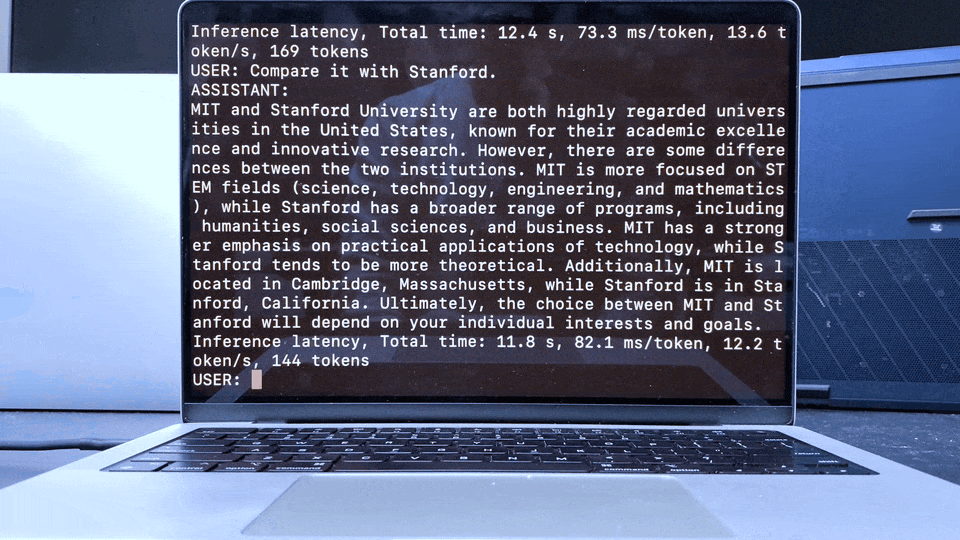
Apple MacBook M1 Pro上的LLaMA聊天演示:
概述
LLM压缩:SmoothQuant和AWQ
SmoothQuant:通过将量化难度从激活转移到权重来平滑激活异常值,这是一种数学上等价的变换(1001 = 1010)。
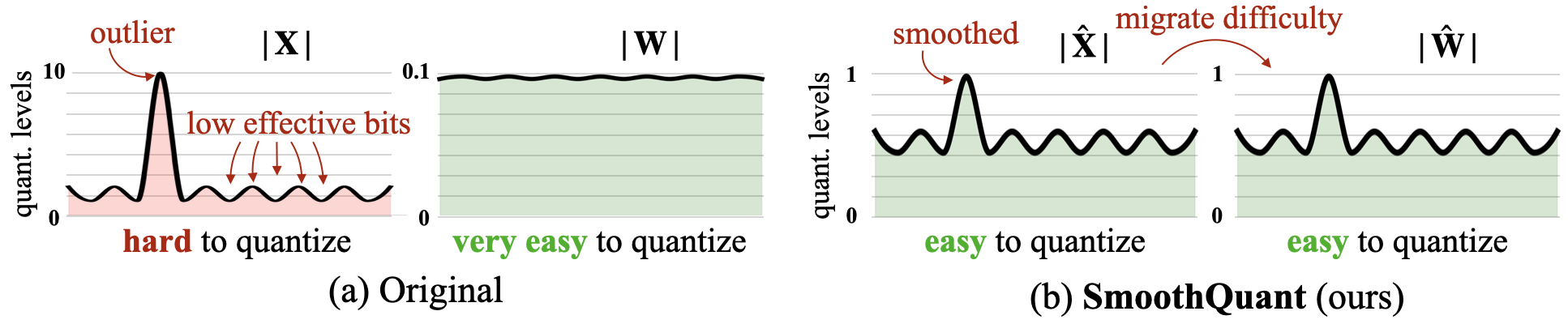
AWQ(激活感知权重量化):通过分析激活幅度而非权重来保护重要的权重通道。
LLM推理引擎:TinyChatEngine
- 通用性:支持x86(Intel/AMD)、ARM(Apple M1/M2、Raspberry Pi)、CUDA(Nvidia GPU)。
- 无库依赖:从零开始的C/C++实现。
- 高性能:在Macbook和GeForce笔记本上实现实时运行。
- 易于使用:下载并编译后即可使用!
新闻
- (2024/05) 🏆 AWQ和TinyChat在MLSys 2024获得了最佳论文奖。🎉
- (2024/05) 🔥 我们发布了对Llama-3模型系列的支持!查看我们的示例和模型库。
- (2024/02) 🔥AWQ和TinyChat已被MLSys 2024接收!
- (2024/02) 🔥我们扩展了对视觉语言模型(VLM)的支持。欢迎尝试在您的边缘设备上运行VILA。
- (2023/10) 我们扩展了对编程助手Code Llama的支持。欢迎查看我们的模型库。
- (2023/10) ⚡我们发布了新的CUDA后端,支持计算能力≥6.1的Nvidia GPU(包括服务器和边缘GPU)。其性能比之前版本提升了约40%。欢迎尝试!
前提条件
MacOS
对于MacOS,通过以下命令安装boost和llvm:
brew install boost
brew install llvm
对于M1/M2用户,从AppStore安装Xcode以启用metal编译器以支持GPU。
Windows(CPU版本)
对于Windows,使用MSYS2下载并安装GCC编译器。按照此教程进行安装:https://code.visualstudio.com/docs/cpp/config-mingw
- 使用MSYS2安装所需依赖
pacman -S --needed base-devel mingw-w64-x86_64-toolchain make unzip git
- 将二进制目录(例如C:\msys64\mingw64\bin和C:\msys64\usr\bin)添加到环境路径
Windows(Nvidia GPU版本,实验性)
-
为Windows安装CUDA工具包(链接)。安装CUDA时,请将安装路径更改为不包含"空格"的其他路径。
-
安装带有C和C++支持的Visual Studio:按照说明进行操作。
-
按照以下说明操作,并使用Visual Studio中的x64 Native Tools Command Prompt编译TinyChatEngine。
使用TinyChatEngine部署Llama-3-8B-Instruct的步骤
这里,我们提供从头开始使用TinyChatEngine部署Llama-3-8B-Instruct的详细步骤。
- 下载仓库。
git clone --recursive https://github.com/mit-han-lab/TinyChatEngine cd TinyChatEngine - 安装Python包
- TinyChatEngine的主要代码库是用纯C/C++编写的。Python包仅用于从我们的模型库下载(和转换)模型。
conda create -n TinyChatEngine python=3.10 pip -y conda activate TinyChatEngine pip install -r requirements.txt
- TinyChatEngine的主要代码库是用纯C/C++编写的。Python包仅用于从我们的模型库下载(和转换)模型。
- 从我们的模型库下载量化后的Llama模型。
cd llm- 在x86设备上(如Intel/AMD笔记本)
python tools/download_model.py --model LLaMA_3_8B_Instruct_awq_int4 --QM QM_x86 - 在ARM设备上(如M1/M2 Macbook, 树莓派)
python tools/download_model.py --model LLaMA_3_8B_Instruct_awq_int4 --QM QM_ARM - 在CUDA设备上(如Jetson AGX Orin, PC/服务器)
python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_CUDA - 查看这个表格获取支持的模型的详细列表
- 在x86设备上(如Intel/AMD笔记本)
- (仅CUDA) 根据您使用的平台和GPU的计算能力,相应修改Makefile。如果在使用Nvidia GPU的Windows上,请修改第54行中的
-arch=sm_xx。如果在使用Nvidia GPU的其他平台上,请修改第60行中的-gencode arch=compute_xx,code=sm_xx。 - 编译并在本地启动聊天。
make chat -j ./chat TinyChatEngine由MIT HAN实验室开发: https://github.com/mit-han-lab/TinyChatEngine 使用模型: LLaMA_3_8B_Instruct 使用AWQ进行4比特量化: https://github.com/mit-han-lab/llm-awq 正在加载模型... 完成! 用户: 为并行计算课程编写一个教学大纲。 助手: 以下是并行计算课程的示例教学大纲: **课程名称:** 并行计算 **授课教师:** [姓名] **课程描述:** 本课程涵盖并行计算的基本概念,包括并行算法、编程模型和架构。学生将学习如何使用各种语言和框架设计、实现和优化并行程序。 **先修要求:** 基本的计算机科学和编程概念知识。 **课程目标:** * 理解并行性原理及其应用 * 学习如何使用不同的语言(如OpenMP, MPI)编写并行程序 ...
使用TinyChatEngine部署视觉语言模型(VLM)聊天机器人
TinyChatEngine不仅支持LLM,还支持VLM。我们为VLM引入了一个复杂的聊天机器人。这里,我们提供了易于遵循的说明,用于使用TinyChatEngine部署视觉语言模型聊天机器人(VILA-7B)。我们建议使用M1/M2 MacBook进行此VLM功能。
-
按照上面的说明设置基本环境,即先决条件和使用TinyChatEngine部署Llama-3-8B-Instruct的步骤。
-
为了在终端中展示图像,请下载并安装以下工具包。
- 安装termvisage。
- (对于MacOS)安装iTerm2。
- (对于其他操作系统)请参考这里准备适当的终端。
-
从我们的模型库下载量化后的VILA-7B模型。
- 在x86设备上(如Intel/AMD笔记本)
python tools/download_model.py --model VILA_7B_awq_int4_CLIP_ViT-L --QM QM_x86 - 在ARM设备上(如M1/M2 Macbook, 树莓派)
python tools/download_model.py --model VILA_7B_awq_int4_CLIP_ViT-L --QM QM_ARM
- 在x86设备上(如Intel/AMD笔记本)
-
(对于MacOS)在本地启动聊天机器人。请使用适当的终端(如iTerm2)。
-
图像/文本到文本
./vila ../assets/figures/vlm_demo/pedestrian.png../assets/figures/vlm_demo路径下有几张图片。随意在您的设备上尝试使用VILA处理不同的图像!
-
对于其他操作系统,请修改vila.sh中的第4行以使用正确的终端。
-
后端支持
| 精度 | x86 (Intel/AMD CPU) | ARM (Apple M1/M2 & RPi) | Nvidia GPU |
|---|---|---|---|
| FP32 | ✅ | ✅ | |
| W4A16 | ✅ | ||
| W4A32 | ✅ | ✅ | |
| W4A8 | ✅ | ✅ | |
| W8A8 | ✅ | ✅ |
- 对于树莓派,我们建议使用8GB RAM的板子。我们的测试主要在Raspberry Pi 4 Model B Rev 1.4(aarch64)上进行。对于其他版本,请随意尝试,如果遇到任何问题,请告诉我们。
- 对于Nvidia GPU,我们的CUDA后端可以支持计算能力 >= 6.1的Nvidia GPU。对于计算能力 < 6.1的GPU,请随意尝试,但我们还没有测试过,因此无法保证结果。
量化和模型支持
TinyChatEngine的目标是在各种设备上支持多种量化方法。例如,目前它支持使用提供的转换脚本opt_smooth_exporter.py从smoothquant生成的int8 opt模型的量化权重。对于LLaMA模型,有可用的脚本将Huggingface格式的检查点转换为我们的int4权重格式,并将它们量化为基于您的设备的特定方法。在转换和量化模型之前,建议应用来自AWQ的伪量化以获得更好的精度。我们目前正在努力支持更多模型,敬请期待!
设备特定的int4权重重排
为了减少运行时权重重排的开销,TinyChatEngine在模型转换过程中离线执行此过程。在本节中,我们将探讨QM_ARM和QM_x86的权重布局。这些布局分别为ARM和x86 CPU定制,支持128位SIMD和256位SIMD操作。我们还支持用于Nvidia GPU(包括服务器和边缘GPU)的QM_CUDA。
| 平台 | 指令集 | 量化方法 |
|---|---|---|
| Intel和AMD | x86-64 | QM_x86 |
| Apple M1/M2 Mac和树莓派 | ARM | QM_ARM |
| Nvidia GPU | CUDA | QM_CUDA |
- QM_ARM布局示例:对于QM_ARM,考虑128位权重向量的初始配置[w0, w1, ... , w30, w31],其中每个wi是4位量化权重。TinyChatEngine通过交错权重的下半部分和上半部分,将这些权重重新排列为序列[w0, w16, w1, w17, ..., w15, w31]。这种新安排便于使用128位AND和移位操作解码上下两半,如后续图所示。这将消除运行时重排开销并提高性能。
TinyChatEngine模型库
我们提供了一系列经过TinyChatEngine测试的模型。这些模型可以直接下载并部署在您的设备上。要下载模型,请在下表中找到目标模型的ID,并使用相关脚本。查看我们的模型库点击这里。
| 模型 | 精度 | ID | x86后端 | ARM后端 | CUDA后端 |
|---|---|---|---|---|---|
| LLaMA_3_8B_Instruct | fp32 | LLaMA_3_8B_Instruct_fp32 | ✅ | ✅ | |
| int4 | LLaMA_3_8B_Instruct_awq_int4 | ✅ | ✅ | ||
| LLaMA2_13B_chat | fp32 | LLaMA2_13B_chat_fp32 | ✅ | ✅ | |
| int4 | LLaMA2_13B_chat_awq_int4 | ✅ | ✅ | ✅ | |
| LLaMA2_7B_chat | fp32 | LLaMA2_7B_chat_fp32 | ✅ | ✅ | |
| int4 | LLaMA2_7B_chat_awq_int4 | ✅ | ✅ | ✅ | |
| LLaMA_7B | fp32 | LLaMA_7B_fp32 | ✅ | ✅ | |
| int4 | LLaMA_7B_awq_int4 | ✅ | ✅ | ✅ | |
| CodeLLaMA_13B_Instruct | fp32 | CodeLLaMA_13B_Instruct_fp32 | ✅ | ✅ | |
| int4 | CodeLLaMA_13B_Instruct_awq_int4 | ✅ | ✅ | ✅ | |
| CodeLLaMA_7B_Instruct | fp32 | CodeLLaMA_7B_Instruct_fp32 | ✅ | ✅ | |
| int4 | CodeLLaMA_7B_Instruct_awq_int4 | ✅ | ✅ | ✅ | |
| Mistral-7B-Instruct-v0.2 | fp32 | Mistral_7B_v0.2_Instruct_fp32 | ✅ | ✅ | |
| int4 | Mistral_7B_v0.2_Instruct_awq_int4 | ✅ | ✅ | ||
| VILA-7B | fp32 | VILA_7B_CLIP_ViT-L_fp32 | ✅ | ✅ | |
| int4 | VILA_7B_awq_int4_CLIP_ViT-L | ✅ | ✅ | ||
| LLaVA-v1.5-13B | fp32 | LLaVA_13B_CLIP_ViT-L_fp32 | ✅ | ✅ | |
| int4 | LLaVA_13B_awq_int4_CLIP_ViT-L | ✅ | ✅ | ||
| LLaVA-v1.5-7B | fp32 | LLaVA_7B_CLIP_ViT-L_fp32 | ✅ | ✅ | |
| int4 | LLaVA_7B_awq_int4_CLIP_ViT-L | ✅ | ✅ | ||
| StarCoder | fp32 | StarCoder_15.5B_fp32 | ✅ | ✅ | |
| int4 | StarCoder_15.5B_awq_int4 | ✅ | ✅ | ||
| opt-6.7B | fp32 | opt_6.7B_fp32 | ✅ | ✅ | |
| int8 | opt_6.7B_smooth_int8 | ✅ | ✅ | ||
| int4 | opt_6.7B_awq_int4 | ✅ | ✅ | ||
| opt-1.3B | fp32 | opt_1.3B_fp32 | ✅ | ✅ | |
| int8 | opt_1.3B_smooth_int8 | ✅ | ✅ | ||
| int4 | opt_1.3B_awq_int4 | ✅ | ✅ | ||
| opt-125m | fp32 | opt_125m_fp32 | ✅ | ✅ | |
| int8 | opt_125m_smooth_int8 | ✅ | ✅ | ||
| int4 | opt_125m_awq_int4 | ✅ | ✅ |
- 在 Intel/AMD 笔记本上:
python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_x86 - 在 M1/M2 Macbook 上:
python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_ARM - 在 Nvidia GPU 上:
python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_CUDA
要使用 TinyChatEngine 部署量化模型,请编译并运行聊天程序。
- 在 CPU 平台上
make chat -j
# ./chat <模型名称> <精度> <线程数>
./chat LLaMA2_7B_chat INT4 8
- 在 GPU 平台上
make chat -j
# ./chat <模型名称> <精度>
./chat LLaMA2_7B_chat INT4
相关项目
TinyEngine:用于微控制器的高效且高性能的神经网络库











