
 Github
Github Huggingface
Huggingface 论文
论文站外调优:无需全模型的迁移学习 [论文]
摘要
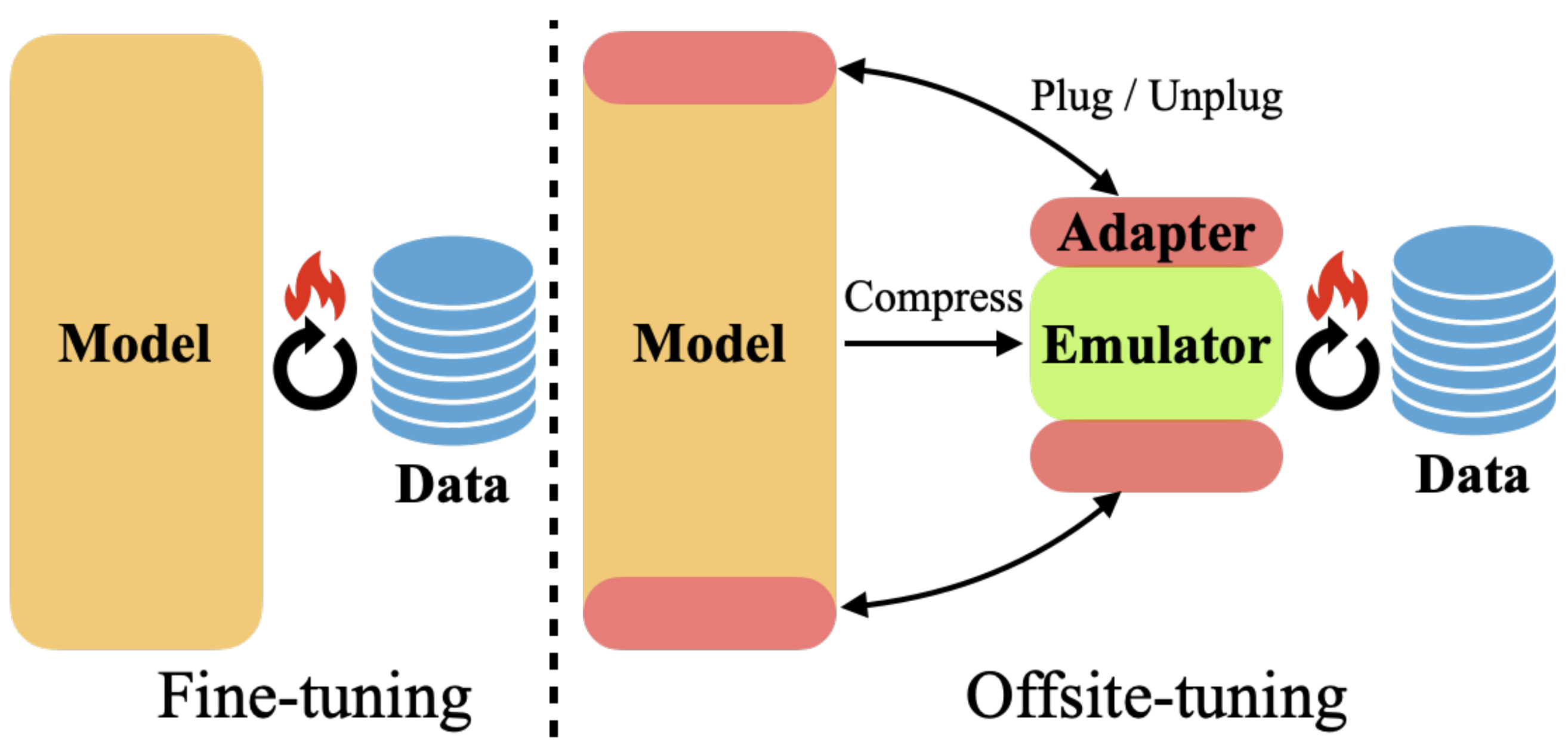
迁移学习对于基础模型适应下游任务至关重要。然而,许多基础模型是专有的,用户必须与模型所有者共享数据以微调模型,这既昂贵又引发隐私问题。此外,微调大型基础模型计算密集,对大多数下游用户来说不切实际。 本文提出了站外调优,一种保护隐私且高效的迁移学习框架,可以在无需访问完整模型的情况下将数十亿参数的基础模型适应下游数据。 在站外调优中,模型所有者向数据所有者发送一个轻量级适配器和一个有损压缩的模拟器,数据所有者随后在模拟器的辅助下,使用下游数据对适配器进行微调。 微调后的适配器返回给模型所有者,后者将其插入完整模型以创建适应后的基础模型。 站外调优保护了双方的隐私,并且在计算效率上优于需要访问完整模型权重的现有微调方法。 我们在各种大型语言和视觉基础模型上展示了站外调优的有效性。 站外调优可以达到与完整模型微调相当的准确度,同时保护隐私并提高效率,实现了6.5倍的加速和5.6倍的内存减少。
使用方法
设置
conda create -n offsite python
conda activate offsite
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install transformers accelerate datasets evaluate wandb scikit-learn scipy timm
pip install lm-eval
python setup.py develop
复现我们的结果
在本仓库中,您将找到复现我们研究结果所需的所有组件。说明如下:
- 核心代码:站外调优的核心代码可以在
offsite_tuning文件夹中找到。 - 脚本:用于生成论文结果的所有脚本可以在
scripts文件夹中找到。 - 模拟器:我们蒸馏的模拟器可以在
emulators文件夹中找到。我们已将论文中使用的模拟器上传到Huggingface。 - 预训练检查点:本研究中使用的预训练检查点可以在
models文件夹中找到。我们已将论文中使用的模型上传到Huggingface。 - 视觉下游数据集:设置研究中使用的视觉下游数据集的脚本可以在
datasets文件夹中找到。
结果
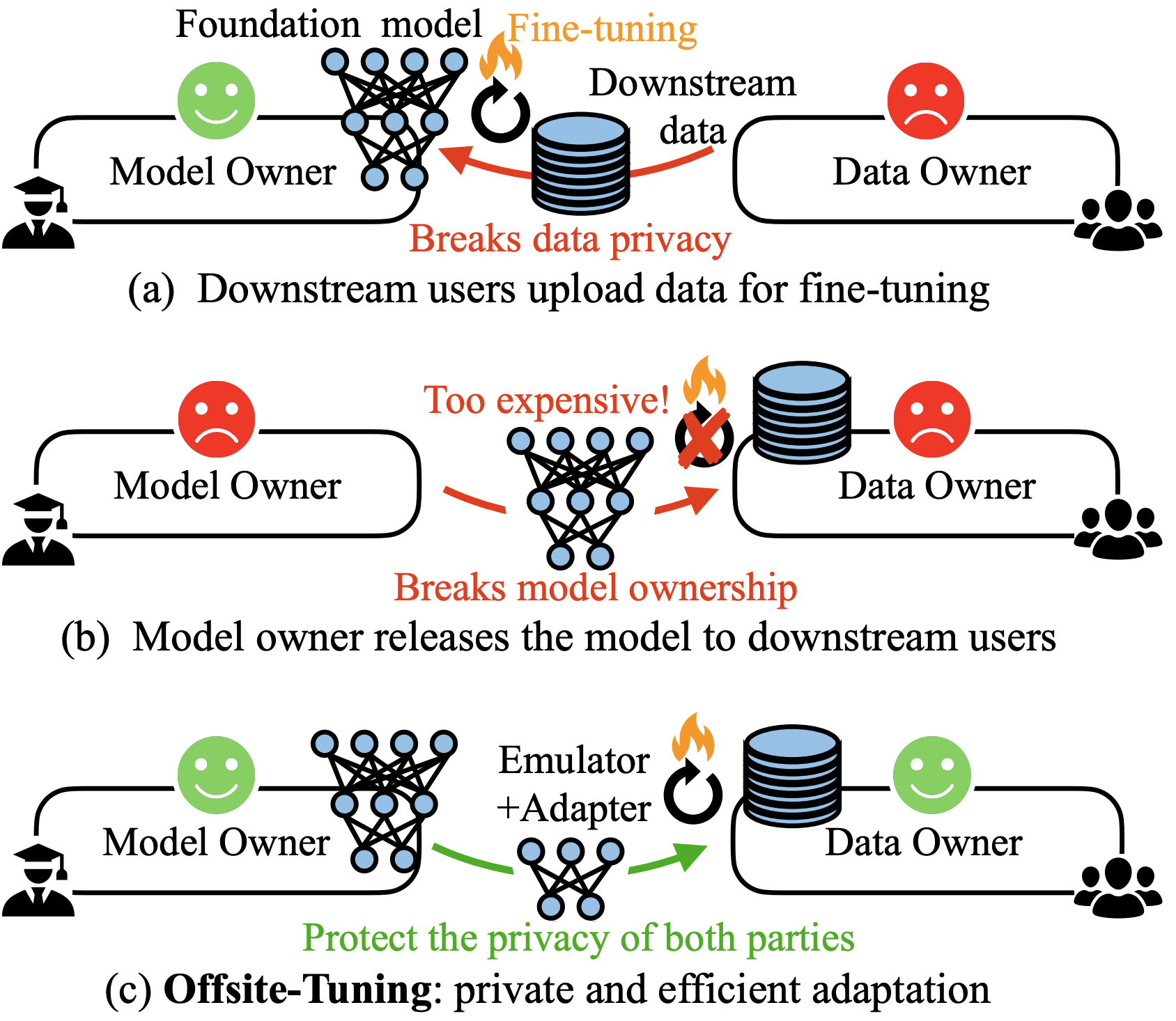
- 比较现有的微调方法(上部和中部)和站外调优(下部)。(a) 传统上,用户将标记数据发送给模型所有者进行微调,这引发了隐私问题并产生高昂的计算成本。(b) 模型所有者向数据所有者发送完整模型是不切实际的,这威胁到专有模型的所有权,而且由于资源限制,用户无法负担得起微调庞大的基础模型。(c) 站外调优为需要访问完整模型权重的传统微调方法提供了一种保护隐私和高效的替代方案。
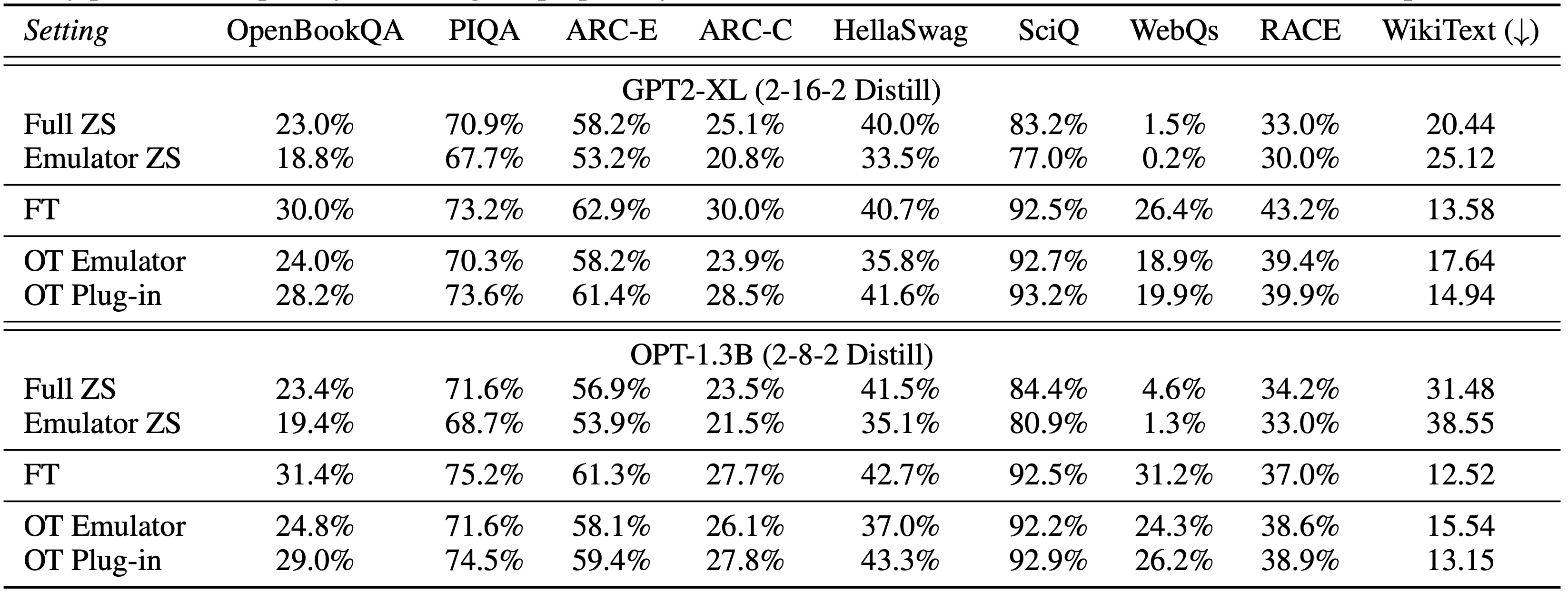
- 在10亿规模的语言模型上,站外调优(OT插件)在所有任务中都提高了零样本(ZS)性能,与完整微调(FT)相比仅略有下降。此外,模拟器微调和插件之间存在一致的性能差距,表明站外调优有效地保护了原始专有模型的隐私(用户无法使用模拟器达到相同的性能)。
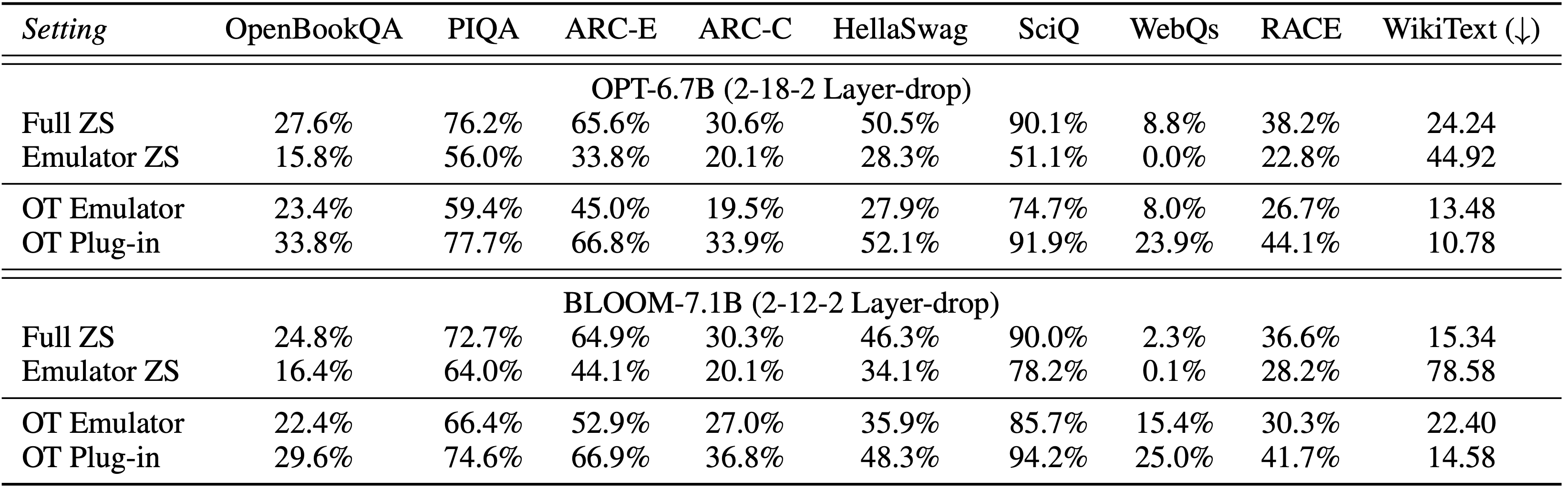
- 站外调优也适用于超过60亿参数的语言模型。
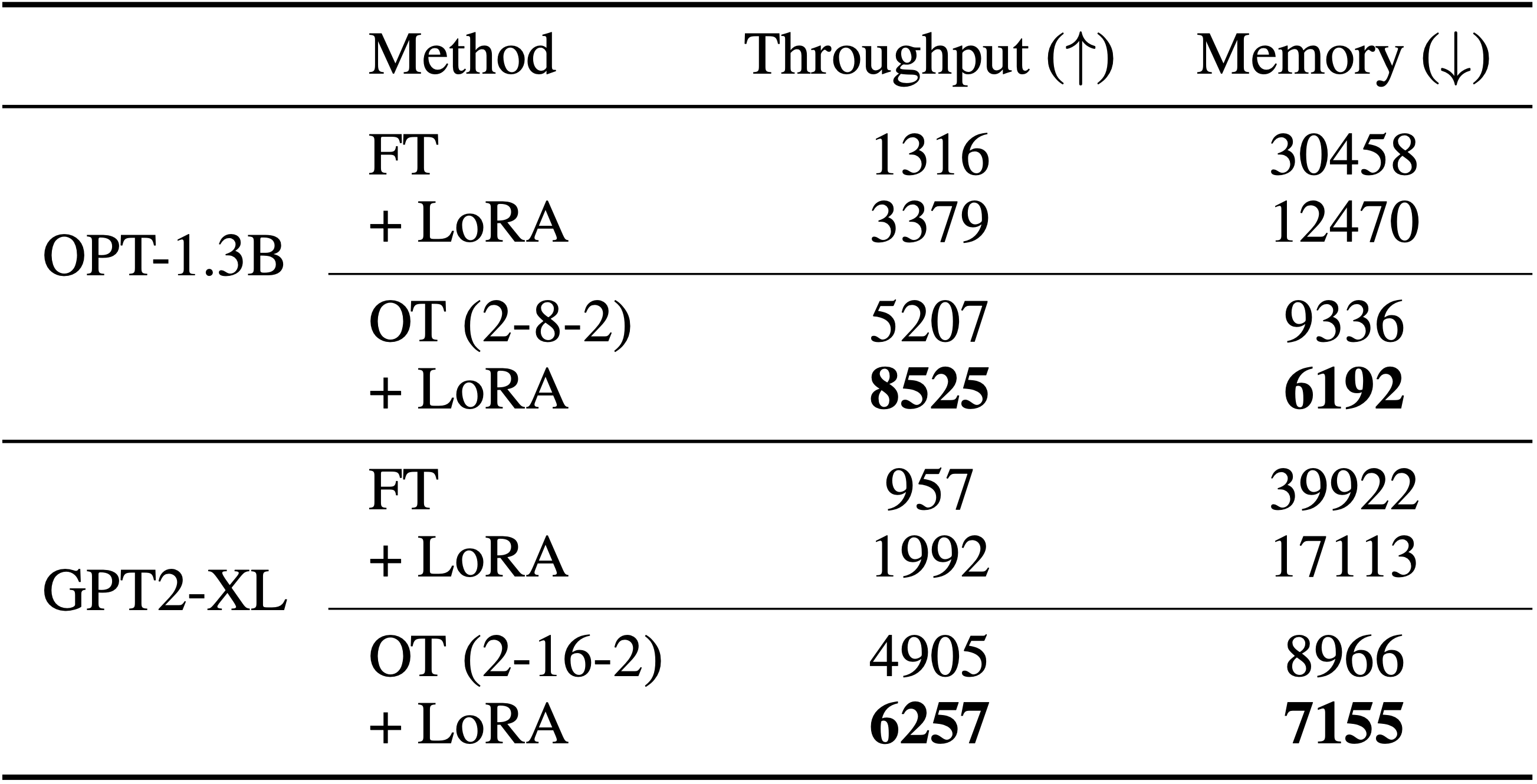
- 与现有微调方法相比,站外调优显著提高了微调吞吐量并减少了内存占用。
引用
如果您发现站外调优对您的研究有用或相关,请引用我们的论文:
@article{xiao2023offsite,
title={Offsite-Tuning: Transfer Learning without Full Model},
author={Xiao, Guangxuan and Lin, Ji and Han, Song},
journal={arXiv},
year={2023}
}











