
 Github
Github Huggingface
Huggingface 论文
论文CharacterEval:一个用于评估角色扮演对话代理的中文基准测试

CharacterEval是一个专为评估角色扮演对话代理(RPCAs)而设计的中文基准测试。它包含1,785个多轮角色扮演对话和23,020个样本,涉及77个源自中国小说和剧本的角色。此外,它还提供了来自百度百科的深入角色描述。CharacterEval采用多方面的评估方法,涵盖四个维度的十三个针对性指标。为了便于评估,我们还基于人工标注开发了一个基于角色的奖励模型(CharacterRM)。实验结果表明,CharacterRM与人类评估的皮尔逊相关系数显著超过了GPT-4。更多详细信息请参阅我们的论文(https://arxiv.org/abs/2401.01275)。
新闻
[2024-5-31] 我们发布了人工标注文档(CharacterEval预定义标注示例.pdf),主要包括每个维度的描述和两个示例(一个最高分和一个最低分)。我们招募了总共12名标注员,分为两组对所有案例进行评分。对于存在分歧的案例,通过讨论达成一致分数。此外,这些示例将用作GPT-4上下文学习的演示。
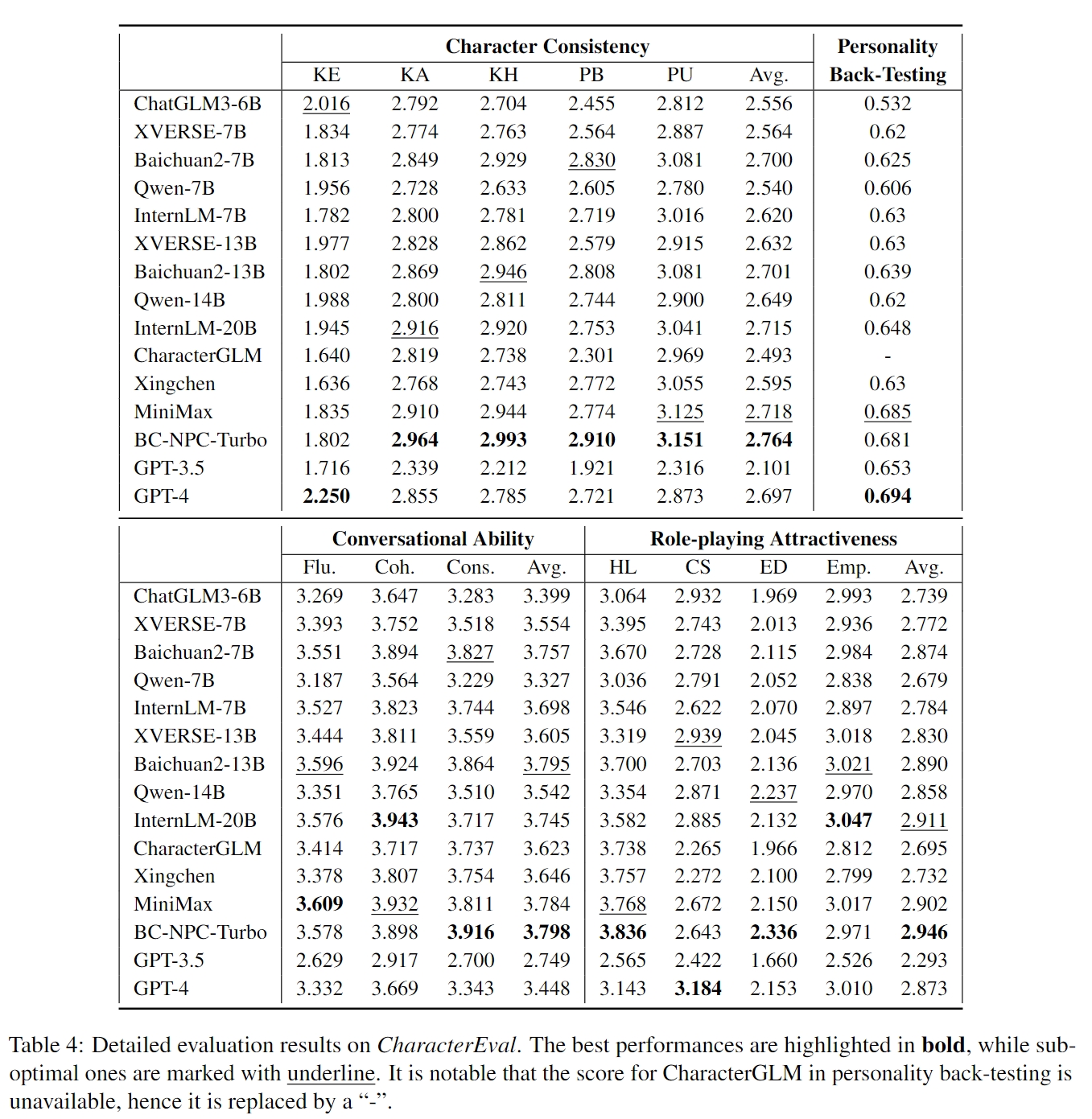
评估维度

排行榜
安装
pip install -r requirements.txt
生成回复
这里我们提供了一个脚本,用于调用ChatGLM3根据上下文和角色描述生成回复。您可以调整它以适应您的模型的输入格式。
CUDA_VISIBLE_DEVICES=0 python get_response.py
# data/test_data.jsonl + data/character_profiles.json -> results/generation.jsonl
转换格式
正如我们在论文中提到的,我们引入标注员对性能矩阵进行稀疏评估。这种方法意味着CharacterEval中的每个示例都使用所有主观指标的子集进行评估,从而得到更加差异化的评估结果。因此,我们需要转换生成结果的格式以进行奖励模型评估。
python transform_format.py
# results/generation.jsonl + data/id2metric.json -> results/generation_trans.jsonl
运行CharacterRM
现在,我们应该下载BaichuanCharRM并使用它来评估生成的回复。
CUDA_VISIBLE_DEVICES=0 python run_char_rm.py
# results/generation_trans.jsonl + data/character_profiles.json -> results/evaluation
计算评估分数
最后一步就是计算每个指标的平均评估分数。
python compute_score.py
为了复现我们的结果,我们提供了五个开源模型的中间运行结果(在results/下),包括ChatGLM-6B、Baichuan-7B-Chat、XVERSE-7B-Chat、InternLM-7B-Chat和Qwen-7B-Chat。所有模型检查点都是从Huggingface下载的。











