
Tensorflow 语音识别
使用谷歌tensorflow深度学习框架,sequence-to-sequence神经网络的语音识别。
替代了caffe-speech-recognition,有关背景信息请参阅此处。
2024 更新:使用 Whisper!
这个(相对)陈旧的项目已不再更新。
使用的 tensorflow 1.0 已经不再兼容,理论也再不在先进水平。
我们强烈建议查看并使用 whisper
2020 更新:Mozilla 发布了 DeepSpeech
他们达到了很好的误差率。自由语音处于良好的掌控中,如果你是最终用户,请去那里。 现在这个项目仅为教育目的维护。
终极目标
为 Linux 等创建一个像样的独立语音识别系统。 有些人说我们有模型但没有足够的训练数据。 我们不同意:有足够的训练数据(100GB 这里 和 21GB openslr.org 上的这里 ,合成的文字转语音片段,有字幕的电影,古腾堡书籍,YouTube 带字幕等),我们只需要一个简单而强大的模型。这只是时间的问题……

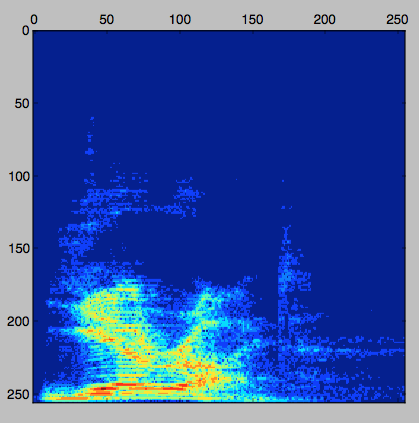
样本频谱图,凯伦以每分钟 160 词的速度说“零”。
安装
克隆代码
git clone https://github.com/pannous/tensorflow-speech-recognition
cd tensorflow-speech-recognition
git clone https://github.com/pannous/layer.git
git clone https://github.com/pannous/tensorpeers.git
pyaudio
需求 portaudio (http://www.portaudio.com/)
git clone https://git.assembla.com/portaudio.git
./configure --prefix=/path/to/your/local
make
make install
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/your/local/lib
export LIDRARY_PATH=$LIBRARY_PATH:/path/to/your/local/lib
export CPATH=$CPATH:/path/to/your/local/include
source ~/.bashrc
安装 pyaudio
pip install pyaudio
入门
玩具例子:
./number_classifier_tflearn.py
./speaker_classifier_tflearn.py
一些不太简单的架构:
./densenet_layer.py
后续:
./train.sh
./record.py
更新:Nervana 展示了独立开发者可以构建最先进的语音识别器。
新手的有趣任务
- 观看视频:https://www.youtube.com/watch?v=u9FPqkuoEJ8
- 理解并纠正相关代码:lstm-tflearn.py
- 数据增强:实时调制数据:增加语音频率,添加背景噪音,改变音调等……
扩展
当前 tensorflow 的扩展可能需要:
- WarpCTC 在 GPU 上 见问题
- 增量协作快照 ('P2P learning')!
- 模块化的图/模型 + 持久性
尽管这个项目还远未完成,但我们希望它能为你提供一些起点。
寻找 tensorflow 合作/顾问/深度学习合同工作?联系 info@pannous.com









