
 访问官网
访问官网 Github
Github 文档
文档项目介绍:lingua-rs
lingua-rs 是一个专注于语言检测的开源库。其主要任务是识别文本所使用的语言。这个功能在自然语言处理应用中非常有用,可以作为文本分类、拼写检查等任务的预处理步骤。同时,语言检测还能帮助邮件根据语言自动分配到相应的客户服务部门,提高服务效率。
语言检测的必要性
在大型机器学习框架和自然语言处理应用中,语言检测是一个重要的部分。然而,对于那些不需要复杂系统功能的小项目或者个人开发者来说,一个小型灵活的库显得尤为重要。lingua-rs 的存在正是为了解决这一需求,它提供了一个简单但有效的语言检测解决方案。
现有问题及解决方案
目前,Rust 生态系统中已有一些用于语言检测的开源库,如 CLD2、Whatlang 和 Whichlang。但大多数库存在两个主要问题:需要较长的文本才能进行有效检测,以及参与决策的语言越多,检测的准确性越低。lingua-rs 通过使用规则和统计方法解决了这些问题,能够对极短文本片段(如单个词语、短语)进行准确检测,而不依赖任何词典或外部API,并且支持离线使用。
支持的语言
lingua-rs 以“质量优于数量”为原则。目前支持 75 种语言,包括:
- 阿非利堪语(Afrikaans)
- 阿拉伯语(Arabic)
- 中文(Chinese)
- 英语(English)
- ……(更多语言详见上文列表)
精准度和测试
lingua-rs 提供了多种测评以确保检测的精确度。对于每种支持的语言,都会使用特定的数据进行测试,这些数据分为单个词、词对和完整句子。这些语言模型及测试数据来自德国莱比锡大学提供的 Wortschatz 语料库。
通过将 lingua-rs 的检测结果与 CLD2、Whatlang 及 Whichlang 的结果进行对比,数据显示 lingua-rs 在短文本和长文本的检测准确性都非常高,尤其在支持的 75 种语言中表现优异。
单词、词对和句子检测效果示例:
-
单个词的检测效果(支持所有语言)
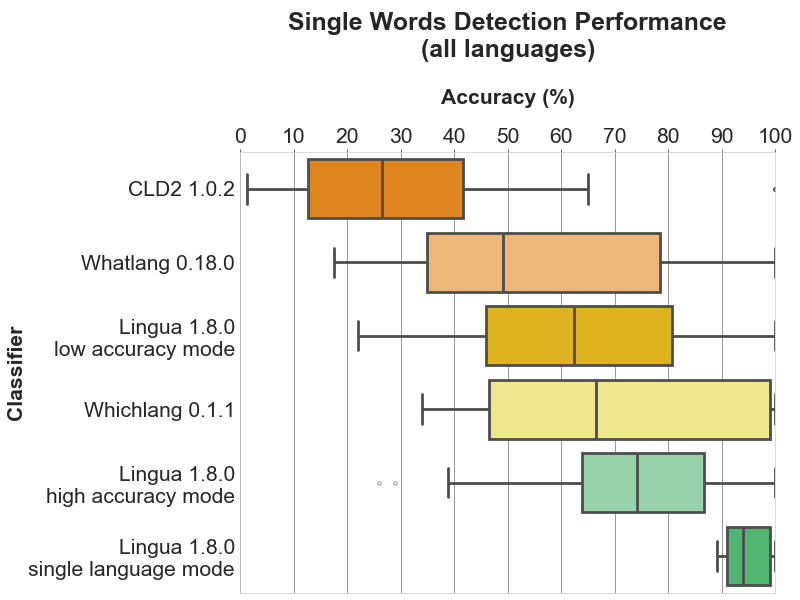
-
句子检测效果(只支持通用语言)
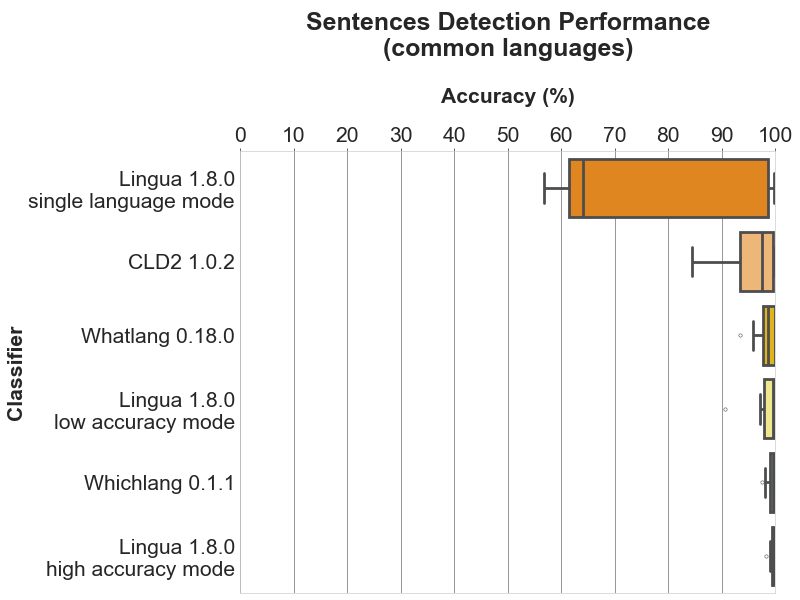
总结
总之,lingua-rs 是一款功能强大、用途广泛的语言检测库,尤其适合那些需要高效、准确语言检测的应用。即使面对短文本,也能提供优雅的解决方案,对广大开发者而言,是一个不容错过的工具。











